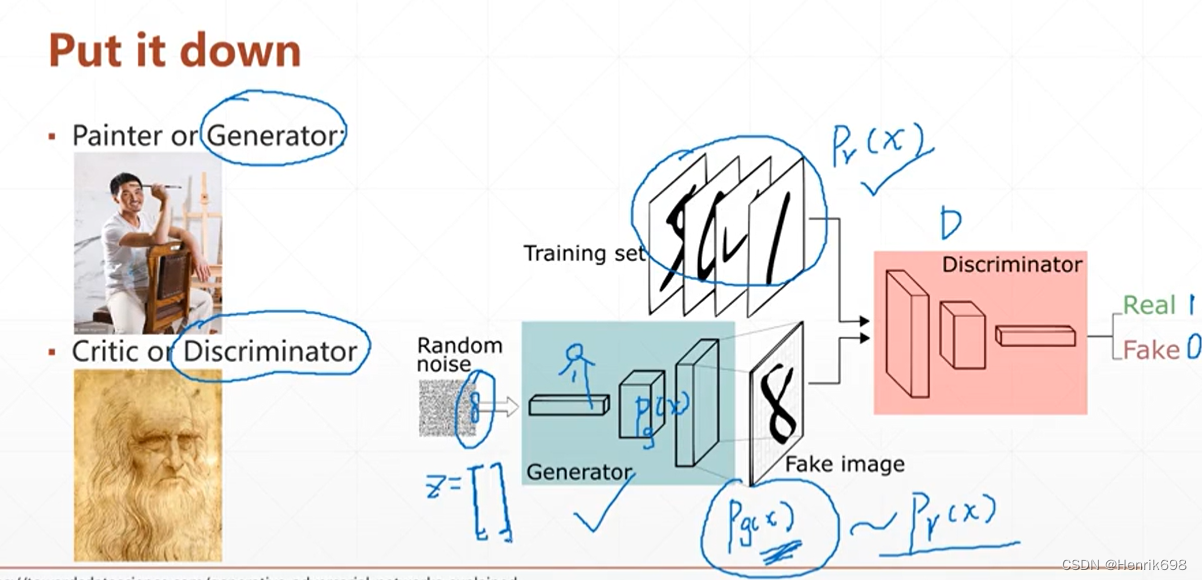
PyTorch-12 生成对抗网络(GAN 、WGAN)
参考:https://zhuanlan.zhihu.com/p/34287744


GAN模型的目标函数如下:

GAN模型优化训练
在训练过程中,生成网络的目标就是尽量生成真实的图片去欺骗判别网络D。而网络D的目标就是尽量把网络G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。这个博弈过程具体是怎么样的呢?
先了解下纳什均衡,纳什均衡是指博弈中这样的局面,对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。对应的,对于GAN,情况就是生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。这是双方网路都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。
GAN模型的目标函数如下:

在这里,训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)和 log(1 - D(G(z))) ),训练网络G最小化log(1 – D(G(z))),即最大化D的损失。而训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布,也就是生成的样本更加的真实。
然后从式子中解释对抗,我们知道G网络的训练是希望[公式]趋近于1,也就是正类,这样G的loss就会最小。而D网络的训练就是一个2分类,目标是分清楚真实数据和生成数据,也就是希望真实数据的D输出趋近于1,而生成数据的输出即[公式]趋近于0,或是负类。这里就是体现了对抗的思想。
然后,这样对抗训练之后,效果可能有几个过程,原论文画出的图如下:

情况1:我们固定住G生成器,查看D判别器能够达到什么水平。



结论:G生成器固定,D判别器的最大值为 Pr(x) /(Pr(x) + Pg(x))
情况2:在D判别器计算完成最大值后(也就是停止D判别器),开始计算G生成器最小值
KL Divergence V.S. JS Divergence


只要pr = pg的时候,Djs(pr || pg) = 0。

结论:在D判别器优化到最大值后,G生成器进化到最小程度为-2log2
前提是pr = pg时,也就是pg逼近pr,G生成器也达到最小。
当G生成器优化到最小值时,其pr=pg的,因此D判别器的最大值Pr(x) /(Pr(x) + Pg(x))= 1/2 = 0.5
DCGAN 深度卷积生成对抗网络
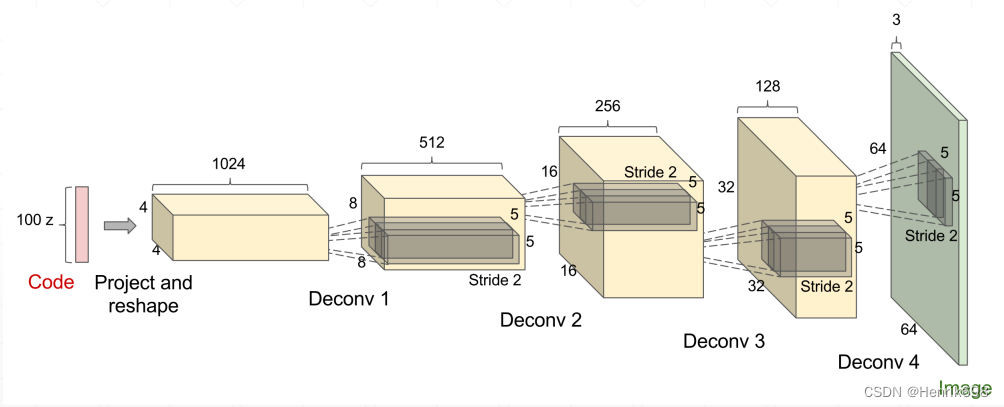
通过Transposed Convolution可以扩大图片的大小

The Last thing?
▪ Training Stability
Why?

Toy example
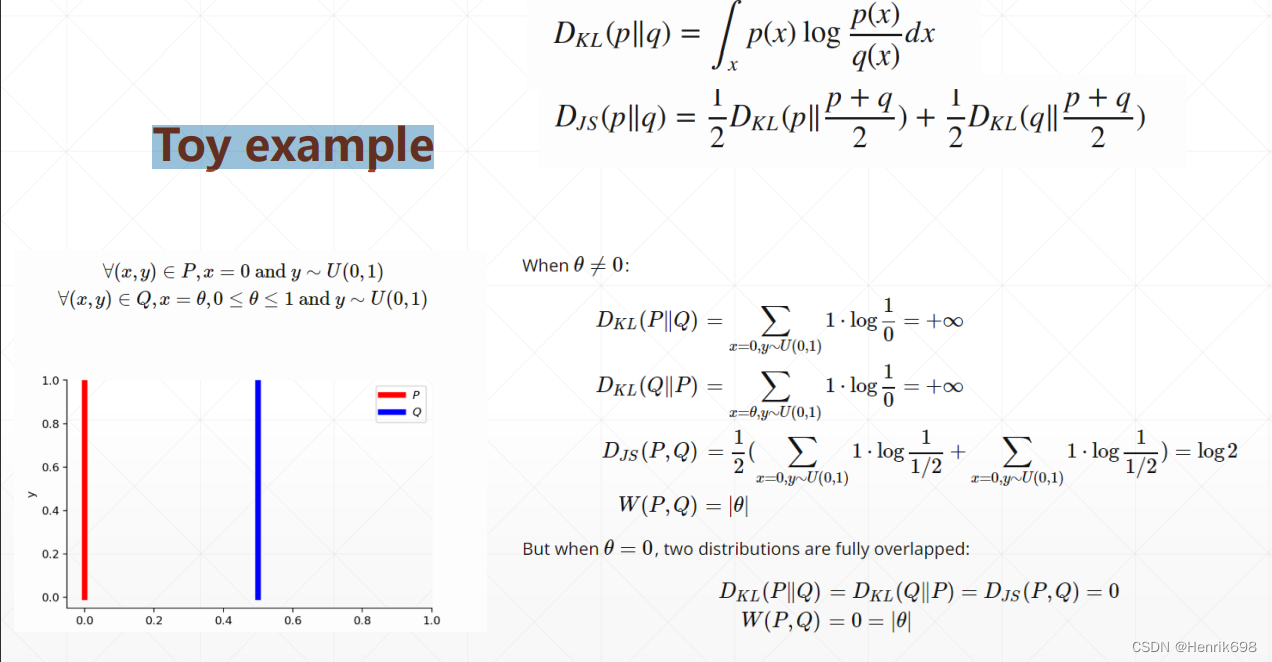
Toy example

JS Divergence

Gradient Vanishing 渐变消失
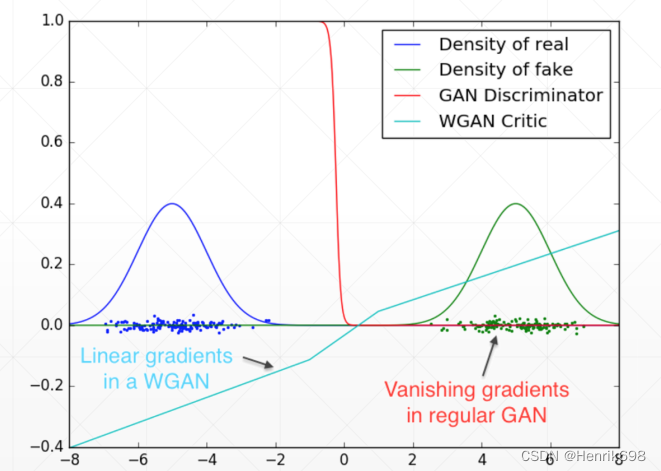
Training Progress Invisible 训练的进展是看不见的
Training Progress Indicator
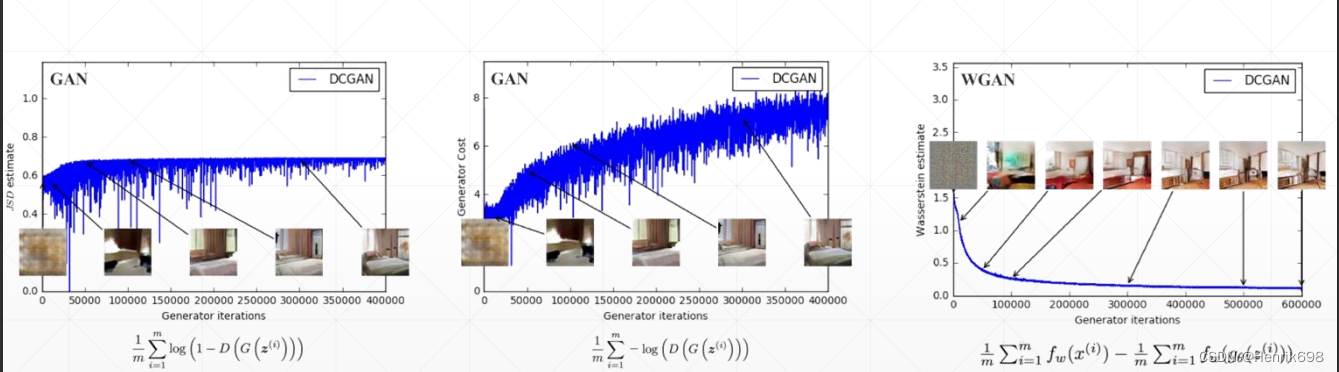
HowTo
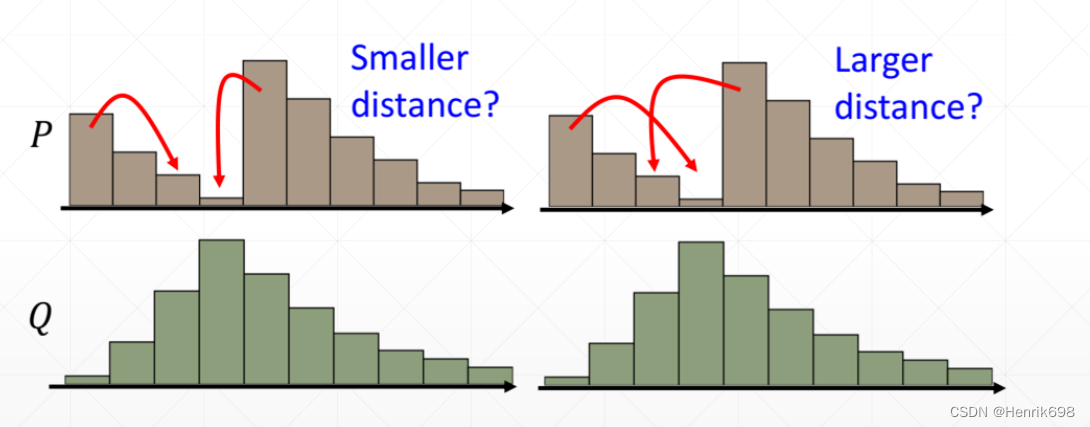
The Least Cost among plans 计划中成本最低的
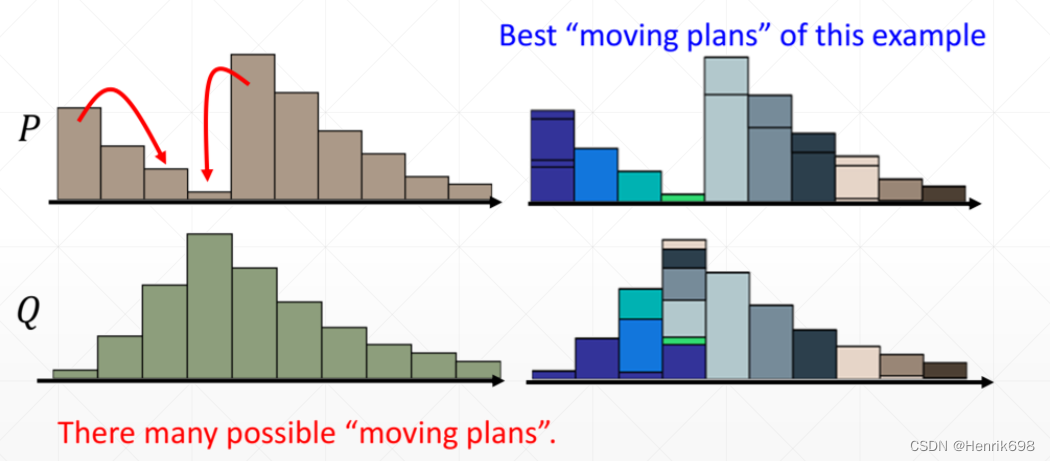
How to compute Wasserstein Distance

WGAN

Sort of Regularization
高斯数据Gaussians

WGAN-Gradient Penalty 梯度惩罚

More stable


实战:GAN
import torch
from torch import nn, optim, autograd
import numpy as np
import visdom
import random
from matplotlib import pyplot as plt
h_dim = 400
batchsz = 512 #这里由于数据量计较少,可以设置大一些,这个值是根据显存来决定的
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.net = nn.Sequential(
#输入中的2是可以随机的,不一定是2,也可以是20
#输出中的2是固定的,因为我们要查看结果,因此将其输出为2维。便于在平面上绘制出来结果。
#z:[b, 2] => [b, 2]
#一共有四层
nn.Linear(2,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,2),
)
def forward(self,z):
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,1),
nn.Sigmoid(),
#输出为1的话,表示数据来自于真实分布的概率非常高,不是由Genator生成的。
#输出如果为0的话,表示这个x可能是由生成器生成的。
)
def forward(self,x):
output = self.net(x)
return output.view(-1) #注意这里降维了,代表概率
def data_generator():
"""
8-gaussian mixture models
:return:
"""
#这里是根据已知的分布,来查看gan是否可以学习出来。
scale = 2.
centers = [
(1,0),
(-1,0),
(0,1),
(0,-1),
(1. / np.sqrt(2),1. / np.sqrt(2)),
(1. / np.sqrt(2),-1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1 / np.sqrt(2)),
(-1. / np.sqrt(2), -1 / np.sqrt(2))
]
#centers是0和1的分布,通过scale对centers进行缩放处理
centers = [(scale * x , scale * y ) for x, y in centers]
while True:
dataset = []
#batchsz是512
for i in range(batchsz):
point = np.random.randn(2) *0.02 #随机生成两个值
center = random.choice(centers) #从上面center的8个点中任意选一个出来
#N(0,1) + center_x1/x2
point[0] += center[0]
point[1] += center[1]
#将这个点添加到dataset中
dataset.append(point)
#转为numpy
dataset = np.array(dataset).astype(np.float32)
dataset /= 1.414
#死循环生成器:每完成一次循环,就跳出,并保存这一次循环的最终状态,下次循环会从这个最终状态开始循环下一次。
yield dataset
#可视化函数
#用于显示sample点与我们理想分布的8个高斯点分布情况,样本点是否符合那八个高斯点的分布。
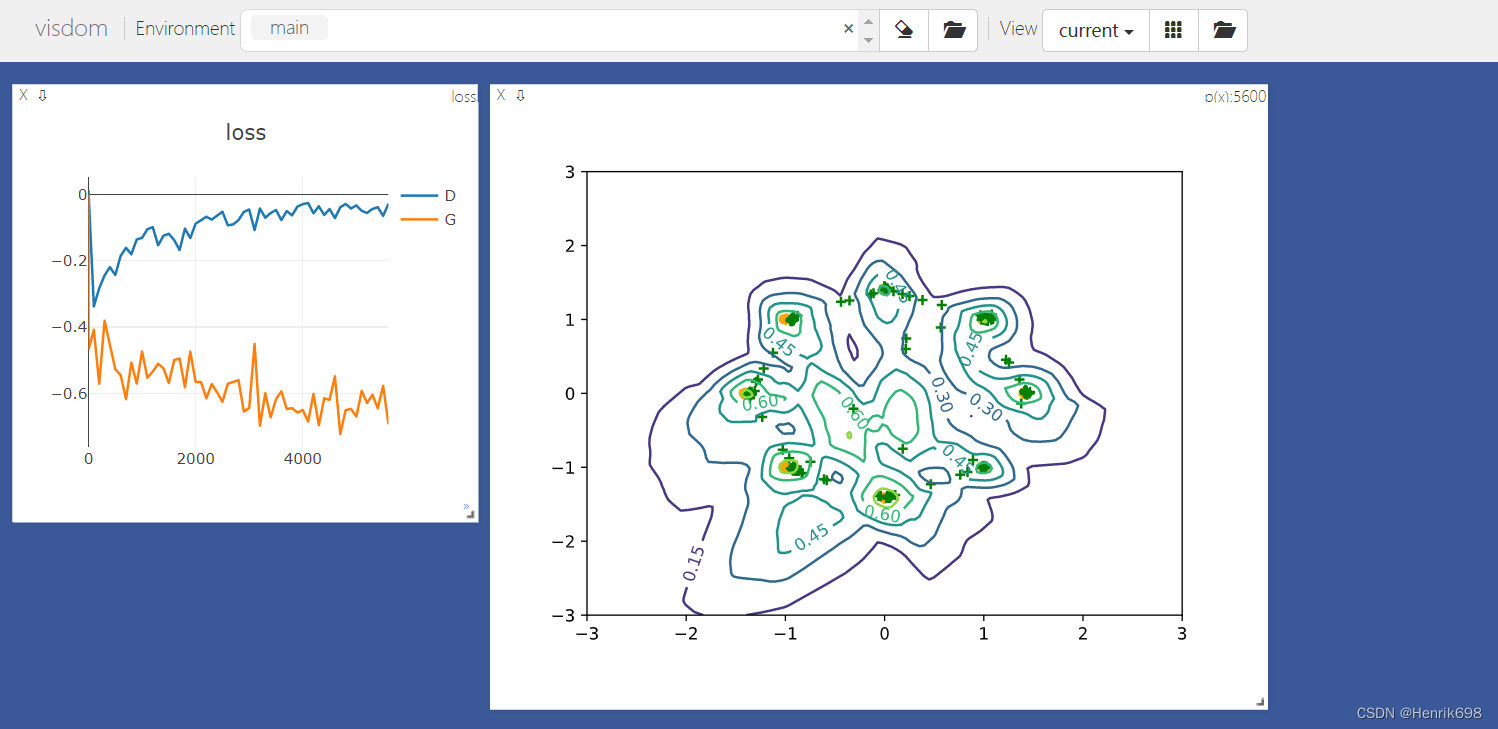
def generate_image(D, G, xr, epoch):
"""
Generates and saves a plot of the true distribution, the generator, and the
critic.
"""
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32')
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
# (16384, 2)
# print('p:', points.shape)
# draw contour
with torch.no_grad():
points = torch.Tensor(points).cuda() # [16384, 2]
disc_map = D(points).cpu().numpy() # [16384]
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
# plt.colorbar()
# draw samples
with torch.no_grad():
z = torch.randn(batchsz, 2).cuda() # [b, 2]
samples = G(z).cpu().numpy() # [b, 2]
plt.scatter(xr[:, 0].cpu().numpy(), xr[:, 1].cpu().numpy(), c='orange', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch))
def main():
#先设置一下种子
torch.manual_seed(23)
np.random.seed(23)
data_iter = data_generator()
#通过next函数获得一次sample
x = next(data_iter)
print(x.shape) #其结果为(512,2)
G = Generator().cuda()
D = Discriminator().cuda()
#可以查看一下网络结构
# print(G)
# print(D)
#优化器
optim_G = optim.Adam(G.parameters(),lr = 5e-4, betas = (0.5,0.9))
optim_D = optim.Adam(D.parameters(),lr = 5e-4, betas = (0.5,0.9))
#生成两个曲线
#1、discrimination和loss_generator
viz.line([[0,0]],[0],win='loss',opts=dict(title='loss',legend = ['D','G']))
#编写GAN的核心部分
for epoch in range(50000):
#G和D彼此间交互着train
#先train判别器,再train生成器
#判别器可能一次train 1-5次
#先train判别器5次,再train生成器
#1、train Discriminator firstly
#因为只优化Discriminator所以不需要计算generator的梯度
#优化1-5步
for _ in range(5):
#有两个loss的来源,一个是真实值,一个是fake值
#1.1、train on real data
#真实数据:
xr = next(data_iter) #这里类型是numpy需要转换
xr = torch.from_numpy(xr).cuda()
#[b,2] => [b,1]
predr = D(xr)
# max predr, min lossr
#最大化predr,就是最小化loss的反方向
#因此要改变其方向,需要加一个负号
#因为我们使用的梯度下降,因此加一个符号,获得最大值。
lossr = -predr.mean()
#1.2、train on fake data
# [b,2]
z = torch.randn(batchsz ,2).cuda()
#生成fake data
#.detach()就是用来限制,是否计算梯度的,有detach存在,回退计算梯度就用因为有detach存在而断开,从而停止计算梯度。
#因为我们只优化Discriminator,所以回退梯度到生成器前停止计算梯度。
#所以generator的梯度是不需要计算的。
xf = G(z).detach() #.detach()类似于tenseflow的tf.stop_gradient()
#将fake data输入到判别器中
predf = D(xf)
#这里是需要最小值的
lossf = predf.mean()
#aggregate all
loss_D = lossr + lossf
#optimize
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
#2、train Generator
z = torch.randn(batchsz, 2).cuda()
xf = G(z)
# 这部分是在继承图的后面,没办法.detach(),只能加进来,也就是判别器的梯度先计算了,只要我们不更新判别器就可以了。
# 这里我们只更新生成器的梯度,因为我们计算了判别器的梯度,因此我们必须要将优化器清零。
predf = D(xf)
#max predf.mean()
loss_G = -predf.mean()
#optimize
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch % 100 ==0:
viz.line([[loss_D.item(),loss_G.item()]],[epoch],win='loss',update='append')
print('loss_D:',loss_D.item(),'; loss_G:',loss_G.item())
generate_image(D,G,xr,epoch)
if __name__ == '__main__':
main()
可以发现:
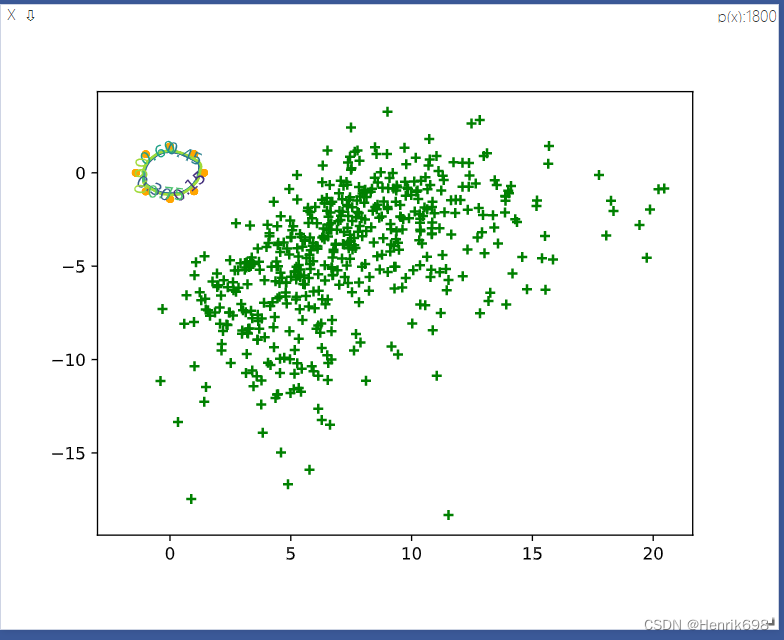
GAN的生成器效果很不好,使得判别器可以非常好的区分出真实数据和假数据,所以判别器的误差为0,GAN train的不稳定,生成器是恒定的,没有梯度信息,生成器长期得不到更新,因此判别器可以很好分别real data和fake data,但是生成器,由于JS divergence,不能很好的衡量两个没有重叠的distribution divergence,因此generator得不到更新,generator的loss一直处于恒定的loss,这个就是原始GAN出现的问题。

其中左侧小全的黄色点就是8个高斯分布模型,右侧绿色点就是sample点,这些sample点和我们想象的8个高斯分布情况完全不一样,现在这个GAN还没有收敛,效果很不好。
实战:WGAN 如何解决GAN train不稳定的问题
WGAN 如何让 GAN的training变得稳定。
WGAN-Gradient Penalty 梯度惩罚
import torch
from torch import nn, optim, autograd
import numpy as np
import visdom
import random
from matplotlib import pyplot as plt
h_dim = 400
batchsz = 512 #这里由于数据量计较少,可以设置大一些,这个值是根据显存来决定的
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.net = nn.Sequential(
#输入中的2是可以随机的,不一定是2,也可以是20
#输出中的2是固定的,因为我们要查看结果,因此将其输出为2维。便于在平面上绘制出来结果。
#z:[b, 2] => [b, 2]
#一共有四层
nn.Linear(2,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,2),
)
def forward(self,z):
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Linear(2,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,1),
nn.Sigmoid(),
#输出为1的话,表示数据来自于真实分布的概率非常高,不是由Genator生成的。
#输出如果为0的话,表示这个x可能是由生成器生成的。
)
def forward(self,x):
output = self.net(x)
return output.view(-1) #注意这里降维了,代表概率
def data_generator():
"""
8-gaussian mixture models
:return:
"""
#这里是根据已知的分布,来查看gan是否可以学习出来。
scale = 2.
centers = [
(1,0),
(-1,0),
(0,1),
(0,-1),
(1. / np.sqrt(2),1. / np.sqrt(2)),
(1. / np.sqrt(2),-1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1 / np.sqrt(2)),
(-1. / np.sqrt(2), -1 / np.sqrt(2))
]
#centers是0和1的分布,通过scale对centers进行缩放处理
centers = [(scale * x , scale * y ) for x, y in centers]
while True:
dataset = []
#batchsz是512
for i in range(batchsz):
point = np.random.randn(2) *0.02 #随机生成两个值
center = random.choice(centers) #从上面center的8个点中任意选一个出来
#N(0,1) + center_x1/x2
point[0] += center[0]
point[1] += center[1]
#将这个点添加到dataset中
dataset.append(point)
#转为numpy
dataset = np.array(dataset).astype(np.float32)
dataset /= 1.414
#死循环生成器:每完成一次循环,就跳出,并保存这一次循环的最终状态,下次循环会从这个最终状态开始循环下一次。
yield dataset
#可视化函数
def generate_image(D, G, xr, epoch):
"""
Generates and saves a plot of the true distribution, the generator, and the
critic.
"""
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32')
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
# (16384, 2)
# print('p:', points.shape)
# draw contour
with torch.no_grad():
points = torch.Tensor(points).cuda() # [16384, 2]
disc_map = D(points).cpu().numpy() # [16384]
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
# plt.colorbar()
# draw samples
with torch.no_grad():
z = torch.randn(batchsz, 2).cuda() # [b, 2]
samples = G(z).cpu().numpy() # [b, 2]
plt.scatter(xr[:, 0].cpu().numpy(), xr[:, 1].cpu().numpy(), c='orange', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch))
#gradient_penalty梯度惩罚
def gradient_penalty(D,xr,xf):
"""
这个惩罚项可以理解为regularization模式:
就是将discrimination约束成one liability function
:param D:
:param xr: [b,2]
:param xf: [b,2]
:return:
"""
#随机sample一个均值分布,维度是[b,1]
t = torch.rand(batchsz,1).cuda()
#[b,1] => [b,2]
#这里需要注意的是,为什么上面不直接生成一个2,而是用下面这种方法。
#这是因为要保持同样的sample,其中t是相同的,所以先通过uniform的分布,sample出b个,之后再expand
#对于一个同样的sample,其权值是相同的。
t = t.expand_as(xr)
# 线性差值,真实与fake data的线性差值
mid = t * xr + (1-t) * xf
#需要有导数信息set it requires gradient
mid.requires_grad_()
pred = D(mid)
grads = autograd.grad(outputs=pred,
inputs=mid,
grad_outputs=torch.ones_like(pred),
create_graph=True, #这个参数是用来二阶求导,如果需要二阶求导就需要设置这个参数。
retain_graph=True, #如果这个图还需要再backward一次,就需要保留这个梯度信息,不然后续的backward就会报错。
)[0]
#平方和:torch.pow(,2)
#.norm(2,dim=1) 表示求2范数:向量元素绝对值的平方和再开方
#这里我们要2范数越接近1越好
gp = torch.pow(grads.norm(2,dim=1) - 1, 2).mean()
return gp
def main():
#先设置一下种子
torch.manual_seed(23)
np.random.seed(23)
data_iter = data_generator()
#通过next函数获得一次sample
x = next(data_iter)
print(x.shape) #其结果为(512,2)
G = Generator().cuda()
D = Discriminator().cuda()
#可以查看一下网络结构
# print(G)
# print(D)
#优化器
optim_G = optim.Adam(G.parameters(),lr = 5e-4, betas = (0.5,0.9))
optim_D = optim.Adam(D.parameters(),lr = 5e-4, betas = (0.5,0.9))
#生成两个曲线
#1、discrimination和loss_generator
viz.line([[0,0]],[0],win='loss',opts=dict(title='loss',legend = ['D','G']))
#编写GAN的核心部分
for epoch in range(50000):
#G和D彼此间交互着train
#先train判别器,再train生成器
#判别器可能一次train 1-5次
#先train判别器5次,再train生成器
#1、train Discriminator firstly
#因为只优化Discriminator所以不需要计算generator的梯度
#优化1-5步
for _ in range(5):
#有两个loss的来源,一个是真实值,一个是fake值
#1.1、train on real data
#真实数据:
xr = next(data_iter) #这里类型是numpy需要转换
xr = torch.from_numpy(xr).cuda()
#[b,2] => [b,1]
predr = D(xr)
# max predr, min lossr
#最大化predr,就是最小化loss的反方向
#因此要改变其方向,需要加一个负号
#因为我们使用的梯度下降,因此加一个符号,获得最大值。
lossr = -predr.mean()
#1.2、train on fake data
# [b,2]
z = torch.randn(batchsz ,2).cuda()
#生成fake data
#.detach()就是用来限制,是否计算梯度的,有detach存在,回退计算梯度就用因为有detach存在而断开,从而停止计算梯度。
#因为我们只优化Discriminator,所以回退梯度到生成器前停止计算梯度。
#所以generator的梯度是不需要计算的。
xf = G(z).detach() #.detach()类似于tenseflow的tf.stop_gradient()
#将fake data输入到判别器中
predf = D(xf)
#这里是需要最小值的
lossf = predf.mean()
#1.3、gradient penalty惩罚项
#这里我们不需要对生成器求导,xf是生成器生成的,因此需要.detach()一下,让其不求导
gp = gradient_penalty(D,xr,xf.detach())
#aggregate all
loss_D = lossr + lossf + 0.2 * gp
#optimize
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
#2、train Generator
z = torch.randn(batchsz, 2).cuda()
xf = G(z)
# 这部分是在继承图的后面,没办法.detach(),只能加进来,也就是判别器的梯度先计算了,只要我们不更新判别器就可以了。
# 这里我们只更新生成器的梯度,因为我们计算了判别器的梯度,因此我们必须要将优化器清零。
predf = D(xf)
#max predf.mean()
loss_G = -predf.mean()
#optimize
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch % 100 ==0:
viz.line([[loss_D.item(),loss_G.item()]],[epoch],win='loss',update='append')
print('loss_D:',loss_D.item(),'; loss_G:',loss_G.item())
generate_image(D,G,xr,epoch)
if __name__ == '__main__':
main()
八个黄色的点是高斯模型点,sample的话在八个高斯点附件的概率是最大的,绿色点是生成的数据点,最好情况是sample出来的绿色点越接近八个高斯点越好。