恶意域名
恶意域名是指黑客在攻击过程中或者对目标网络实施控制时,使用dga算法生成的域名,这种域名通常硬编码在恶意软件中。我们在做流量分析时不仅要通过流量的指纹特征识别威胁,也可以通过检测是否解析了恶意域名来判断网络中是否存在肉鸡。
传统DGA域名检测方法
1、最直接的就是逆向恶意程序,这种办法要求高,并且只能查到已知样本的恶意dga域名。
2 、网络流量分析,抓出异常的dns请求,分析确认
3 、碰撞dga库,白帽子收集和用dga算法生成的域名库。
基于机器学习的检测方法
白样本:采用Alexa top1m
黑样本:http://data.netlab.360.com/dga/
初步分析:dga域名属于文本特征,我们先用最常用文本特征处理手段 N-gram+tf-idf 、NLP提取词向量特征+机器学习分类器,我们将黑白样本合并、打乱顺序,用N-gram+tf-idf方式进行初测试。(没得GPU,使用词向量提取时间过长,放弃…)
2-gram+tf-idf+XGBoost
样本稍微有点不均衡,而且维度很大训练吃力,不过测试效果不错。

数据分析特征提取
黑白样本不均衡,保留类别数目大于3000的家族样本,并使用随机下采样方式使黑白样本均衡。
仅做测试数据足够,而且高维文本特征表示,近乎两两正交,使用SMOTE类似方法过采样效果甚微。
最终数据分布如下:

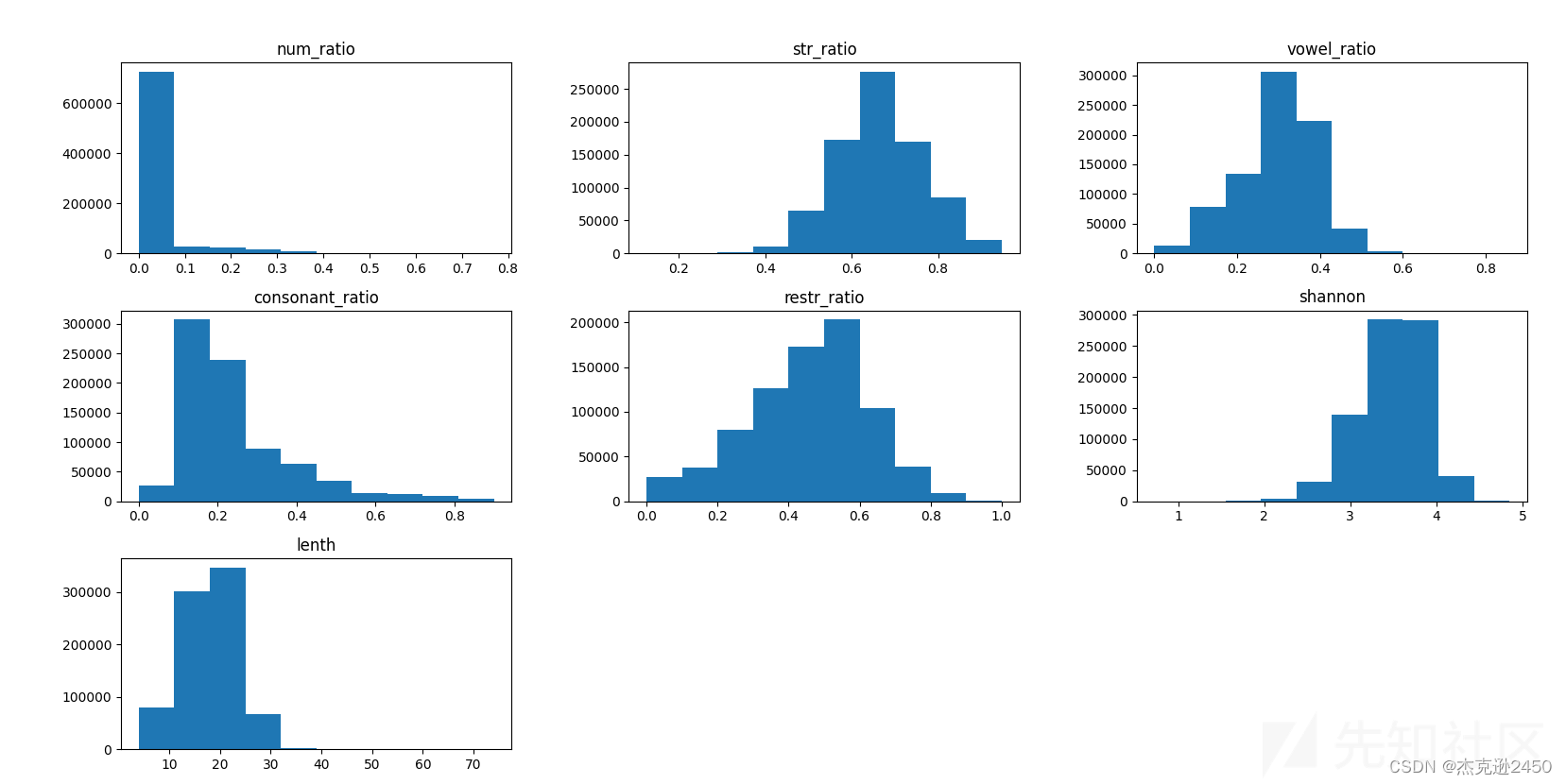
DGA算法作为随机域名生成算法,它生成的域名与正常域名相比随机性更强。可以从如下几个方面考虑特征:
1、数字/字母 占比
2、元音字母/辅音字母 占比(合法域名一般由正常字母组成包含元音字母多,可读行强)
3、字母 重复出现次数占比
4、域名长度
5、香农熵(可以判断域名随机性)
特征数据分布图可以大概看出特征区分度:
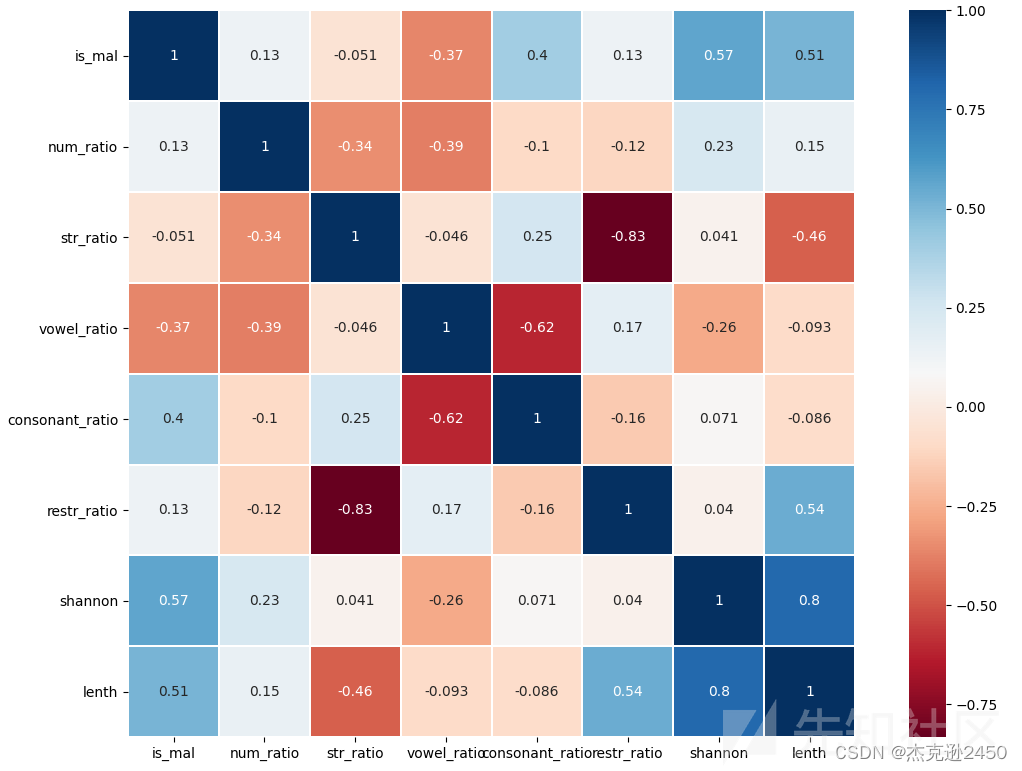
特征相关性分布混淆矩阵:
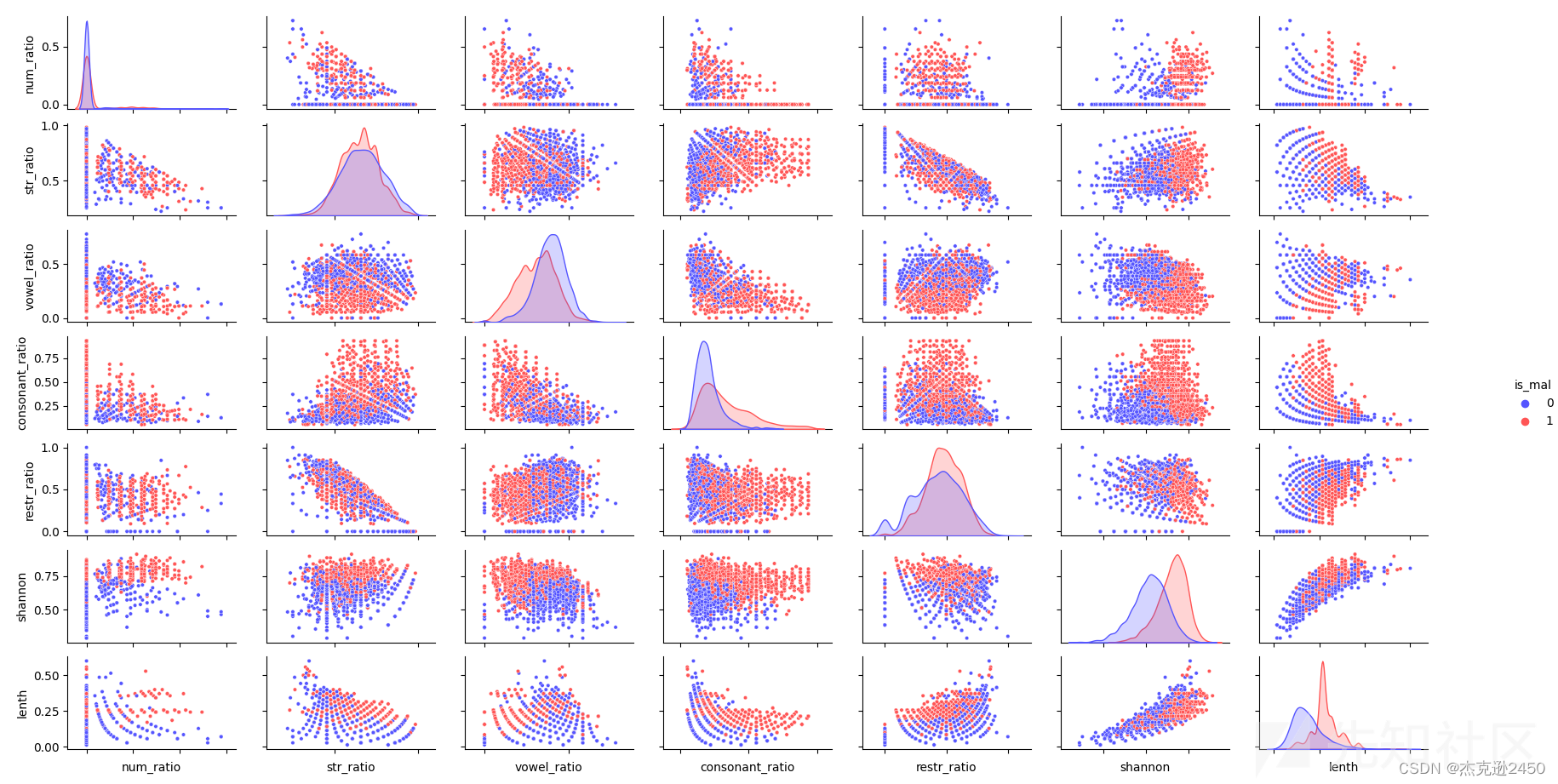
特征关联性分布散点图:
使用SelectKBest对特征评分:

通过以上分析得出DGA域名中字母出现占比与字母重复出现次数占比相关性比较大,根据特征评分删除字母占比特征。
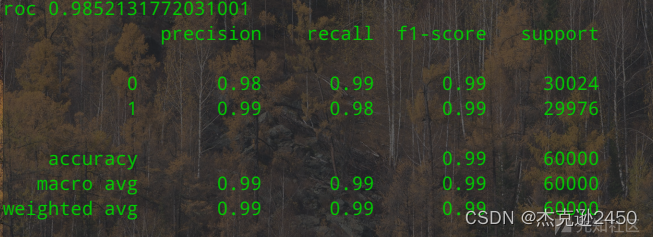
使用上述6个特征经XGBoost分类器训练结果如下:

合并TF-IDF特征经XGBoost分类器训练结果如下:
使用stacking模型融合尝试进一步提升模型效果:
KFOLD,n_splits=5


经测试在本数据集上stacking 在低维数据集表现不佳,使用stacking方法训练上述自己提取的六个特征,stacking模型准确率、roc值均与第一层最优分类器相近(仅适用本数据集)。但处理高维tf-idf特征相较第一层分类器有较大提升,特征融合后使用少量样本集做测试也均有较大提升。