目录
一、理论基础
二、核心程序
三、仿真结论
一、理论基础
支持向量机(Support Vector Machine,SVM) 是一种在统计学习基础上发展起来的机器学习方法,其最大特点是根据Vapnik结构风险最小化原则。它的基本模型是定义在特征空间上的间隔最大的线性分类器,在解决小样本、非线性及高维度等问题上具有传统的机器学习方法所不具备的优势。SVM本是针对二分类问题提出的,如何将其应用到多类分类问题将成为对SVM研究的重要问题之一。当前,对于SVM的多分类问题,解决思路有两种:(1)将问题转化为SVM直接可解的问题;(2)适当改变原始SVM中最优化问题,使之成为能同时计算出所有分类决策问题的决策函数,从而一次性实现多分类。其中方法(2)看似简单,但由于其问题最优化求解过程太过复杂,计算量太大,实现困难,未得到广泛应用。故当前多分类主要采用的是方法(1)的思想。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane) 。
SVM使用铰链损失函数(hinge loss)计算经验风险(empirical risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器 。SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一 。
SVM被提出于1964年,在二十世纪90年代后得到快速发展并衍生出一系列改进和扩展算法,在人像识别、文本分类等模式识别(pattern recognition)问题中有得到应用 。
SVM是由模式识别中广义肖像算法(generalized portrait algorithm)发展而来的分类器 ,其早期工作来自前苏联学者Vladimir N. Vapnik和Alexander Y. Lerner在1963年发表的研究 。1964年,Vapnik和Alexey Y. Chervonenkis对广义肖像算法进行了进一步讨论并建立了硬边距的线性SVM [7] 。此后在二十世纪70-80年代,随着模式识别中最大边距决策边界的理论研究、基于松弛变量(slack variable)的规划问题求解技术的出现 ,和VC维(Vapnik-Chervonenkis dimension, VC dimension)的提出 ,SVM被逐步理论化并成为统计学习理论的一部分。1992年,Bernhard E. Boser、Isabelle M. Guyon和Vapnik通过核方法得到了非线性SVM。1995年,Corinna Cortes和Vapnik提出了软边距的非线性SVM并将其应用于手写字符识别问题 ,这份研究在发表后得到了关注和引用,为SVM在各领域的应用提供了参考。
所谓向量,可以简单理解成在直角坐标系中由原点出发,指向某一坐标点的一个剪头,因此它只有两个特征,大小和方向,如下图(以二维空间为例)中x \boldsymbol xx。所谓n nn维超平面(hyperplane)是指在n nn维内积空间中,所有在同一个法向量(如下图中w \boldsymbol ww)上投影长度相同的向量组成的集合,如下图中超平面。


由此可见,超平面外一向量到超平面的几何距离就等于将该向量代入超平面方程取绝对值后,再除以超平面法向量的模长。
总的来说,在集成算法和神经网络风靡之前,SVM 基本上是最好的分类算法,但即使在今天,它依然占有较高的地位。
SVM 的主要优点有:
1)引入最大间隔,分类精确度高
2)在样本量较小时,也能准确的分类,并且具有不错的泛化能力
3)引入核函数,能轻松的解决非线性问题
4)能解决高维特征的分类、回归问题,即使特征维度大于样本的数据,也能有很好的表现
SVM 的主要缺点有:
1)在样本量非常大时,核函数中內积的计算,求解拉格朗日乘子α 值的计算都是和样本个数有关的,会导致在求解模型时的计算量过大
2)核函数的选择通常没有明确的指导,有时候难以选择一个合适的核函数,而且像多项式核函数,需要调试的参数也非常多
二分类:

多分类

二、核心程序
.............................................................
figure;
subplot(131);
for i = 1:Class_Num
%测试数据设置为1维,2维,或者3维,多维测试数据不方便观察
Nums= 10+round(Num*rand(1))+1;
Xo = 3*floor((i+1)/2) + randn(1,Nums);
Yo = 3*mod(i,2) + randn(1,Nums);
Lo = i*ones(1,Nums);
Xt = [Xt,Xo];
Yt = [Yt,Yo];
Lt = [Lt,Lo];
plot(Xo,Yo,colors{1});
hold on;
end
title('原始数据');
Test_Dat = [Xt;Yt];
Category = Lt;
axis square;
Len_xy = axis;
axis([Len_xy(1),Len_xy(2),Len_xy(3),Len_xy(4)]);
subplot(132);
func_MSVM_old(Test_Dat,Category,Class_Num,colors,Len_xy);
%%newmsvm
%%newmsvm
%%newmsvm
%根据MSVM论文的算法进行多分类SVM仿真
%进行训练
Parameter.solver ='Operation';
Parameter.ker ='linear';
Parameter.arg = 1;
Parameter.C = 1;
[dim,num_data] = size(Test_Dat);
CNT = 0;
Category_Index = [];
Classes = zeros(2,(Class_Num-1)*Class_Num/2);
Alpha = zeros(num_data,(Class_Num-1)*Class_Num/2);
b = zeros((Class_Num-1)*Class_Num/2,1);
K = 0;
Test_Dat1 = Test_Dat;
Test_Dat2 = Test_Dat.^2;
Test_Dat3 = [Test_Dat(1,:).*Test_Dat(2,:);Test_Dat(1,:).*Test_Dat(2,:)];
bin_model = [];
Alpha1 = zeros(num_data,(Class_Num-1)*Class_Num/2);
b1 = zeros((Class_Num-1)*Class_Num/2,1);
K1 = 0;
for j1 = 1:Class_Num-1
for j2 = j1+1:Class_Num
CNT = CNT + 1
%dual form
Classes(1,CNT) = j1;
Classes(2,CNT) = j2;
Category_Index1= find(Category==j1);
Category_Index2= find(Category==j2);
Category_Index = unique([Category_Index1,Category_Index2]);
bin_data.X = Test_Dat1(:,Category_Index);
bin_data.y = Category(:,Category_Index);
bin_data.y(find(bin_data.y == j1)) = 1;
bin_data.y(find(bin_data.y == j2)) = 2;
bin_model = feval('Operation',bin_data,Parameter);
%计算alpha
Alpha1(Category_Index(bin_model.POS.inx),CNT) = bin_model.Alpha(:);
%计算b
b1(CNT) = bin_model.b;
%计算K
K1 = K1 + bin_model.K;
end
end
bin_model = [];
CNT = 0;
Category_Index = [];
Alpha2 = zeros(num_data,(Class_Num-1)*Class_Num/2);
b2 = zeros((Class_Num-1)*Class_Num/2,1);
K2 = 0;
for j1 = 1:Class_Num-1
for j2 = j1+1:Class_Num
CNT = CNT + 1
%dual form
Classes(1,CNT) = j1;
Classes(2,CNT) = j2;
Category_Index1= find(Category==j1);
Category_Index2= find(Category==j2);
Category_Index = unique([Category_Index1,Category_Index2]);
bin_data.X = Test_Dat2(:,Category_Index);
bin_data.y = Category(:,Category_Index);
bin_data.y(find(bin_data.y == j1)) = 1;
bin_data.y(find(bin_data.y == j2)) = 2;
bin_model = feval('Operation',bin_data,Parameter);
%计算alpha
Alpha2(Category_Index(bin_model.POS.inx),CNT) = bin_model.Alpha(:);
%计算b
b2(CNT) = bin_model.b;
%计算K
K2 = K2 + bin_model.K;
end
end
bin_model = [];
CNT = 0;
Category_Index = [];
Alpha3 = zeros(num_data,(Class_Num-1)*Class_Num/2);
b3 = zeros((Class_Num-1)*Class_Num/2,1);
K3 = 0;
for j1 = 1:Class_Num-1
for j2 = j1+1:Class_Num
CNT = CNT + 1
%dual form
Classes(1,CNT) = j1;
Classes(2,CNT) = j2;
Category_Index1= find(Category==j1);
Category_Index2= find(Category==j2);
Category_Index = unique([Category_Index1,Category_Index2]);
bin_data.X = Test_Dat3(:,Category_Index);
bin_data.y = Category(:,Category_Index);
bin_data.y(find(bin_data.y == j1)) = 1;
bin_data.y(find(bin_data.y == j2)) = 2;
bin_model = feval('Operation',bin_data,Parameter);
%计算alpha
Alpha3(Category_Index(bin_model.POS.inx),CNT) = bin_model.Alpha(:);
%计算b
b3(CNT) = bin_model.b;
%计算K
K3 = K3 + bin_model.K;
end
end
Alphao{1} = Alpha1;
Alphao{2} = Alpha2;
Alphao{3} = Alpha3;
bo{1} = b1;
bo{2} = b2;
bo{3} = b3;
Ko{1} = K1;
Ko{2} = K2;
Ko{3} = K3;
[V,I] = min([K1(1),K2(1),K3(1)]);
K = Ko{I};
Alpha = Alphao{I};
b = bo{I};
index0 = find(sum(abs(Alpha),2)~= 0);
MSVM_Net.Alpha = Alpha(index0,:);
MSVM_Net.b = b;
MSVM_Net.Classes = Classes;
MSVM_Net.Pos.X = Test_Dat(:,index0);
MSVM_Net.Pos.y = Category(index0);
MSVM_Net.K = K;
MSVM_Net.Parameter = Parameter;
subplot(133);
DIM = size(Test_Dat,1);
for Class_Ind = 1:Class_Num
Index = find(Category == Class_Ind);
if isempty(Index)==0
if DIM == 1
h = plot(Test_Dat(1,Index),zeros(1,length(Index)),colors{Class_Ind});
end
if DIM == 2
h = plot(Test_Dat(1,Index),Test_Dat(2,Index),colors{Class_Ind});
end
if DIM >= 3
h = plot3(Test_Dat(1,Index),Test_Dat(2,Index),Test_Dat(3,Index),colors{Class_Ind});
end
end
hold on;
end
dx = 0.1;
dy = 0.1;
Xgrid = Len_xy(1):dx:Len_xy(2);
Ygrid = Len_xy(3):dy:Len_xy(4);
[X,Y] = meshgrid(Xgrid,Ygrid);
Xmulti = 1;
Ymulti = 1;
for j = 1:DIM
Xmulti = Xmulti*size(X,j);
Ymulti = Ymulti*size(Y,j);
end
View_data = [reshape(X',1,Xmulti);
reshape(Y',1,Ymulti)];
MSVM_ = feval('msvmclassify',View_data,MSVM_Net);
%计算分类错误概率
Ini_Class = Category;
Label_test= msvmclassify(Test_Dat,MSVM_Net);
Label_init= Ini_Class;
Error = length(find((Label_test-Label_init)~=0))/length(Label_test);
Dats = num2str(100*Error);
func_get_boudary(MSVM_,Class_Num,Xgrid,Ygrid);
title(['错误比例:',Dats,'%']);
axis square;
axis([Len_xy(1),Len_xy(2),Len_xy(3),Len_xy(4)]);
clc;
clear;
A05-15
三、仿真结论
二分类:
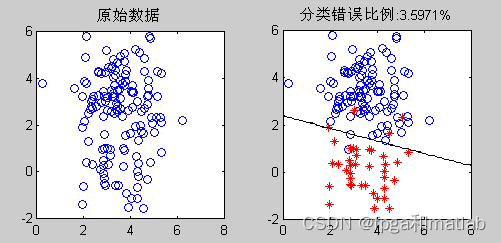
三分类:

四分类:
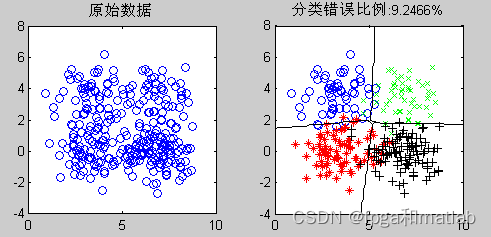
五分类:

六分类:
