本专题需要具备的基础:
- 了解深度学习分类网络原理。
- 了解2017年的transformer。
Transformer 技术里程碑:

ViT简介
时间:2020年CVPR
论文全称:《An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale》
发明人:谷歌团队
简介:论文中提出了 Vision Transformer (ViT),能直接利用 Transformer 对图像进行分类,而不需要卷积网络。(论文中也提到CNN+transformer,但效果差不多)
基本原理:将图像划分为16x16的小切片,转成序列,输入ViT中,得到分类。
ViT算法全貌

ViT算法结构图
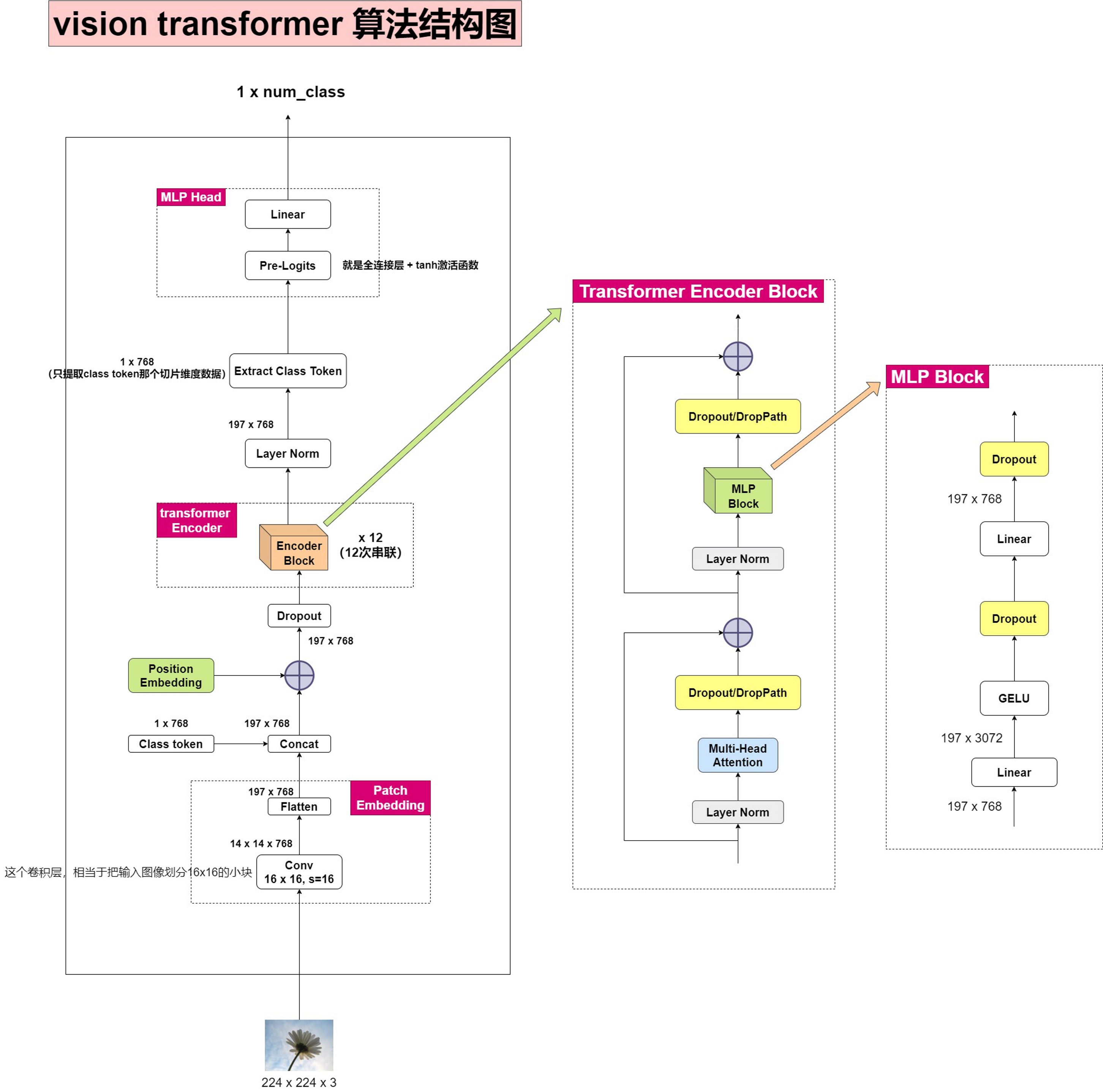
有了基础,理解上图不是很复杂,代码也不是很长,记录几个要点:
-
图像是怎么输入transformer中的:用一个16x16尺度,步长为16,通道数为768的卷积,对图像进行特征提取,这种卷积,相当于把图片信息,分割为独立的14*14的小切片。14x14后续会拉平,就成为NLP中序列一样。
-
类别编码(class token):假设你9个向量经过编码器之后,你该选择哪一个向量进入到最后的分类头呢?因此这里作者给了额外的一个用于分类的向量,与输入进行拼接。同样这是一个可学习的变量。这东西刚开始会随机初始化,作为图像的类别编码信息,然后会和图像切片信息做通道拼接。
-
位置编码:位置编码有两种方式,一种以固定算法生成,另一种是自动学习,ViT中用的自动学习。
-
怎么得到分类结果:经过transformer encoder后,数据维度为197 x 768,其中,1x768是网络预测的类别信息,196x768是图像每个‘切片’的信息。后续只要单独提取出类别信息这一维度,通过全连接层(1 x 768转成 1 x class_num)、softmax等,就能让网络学会给出类别索引序号。
较好的参考资料
Vision Transformer详解_霹雳吧啦Wz-CSDN博客