CVPR 2019
Rare Event Detection using Disentangled Representation Learning
Ryuhei Hamaguchi, Ken Sakurada, and Ryosuke Nakamura
National Institute of Advanced Industrial Science and Technology (AIST)
{ryuhei.hamaguchi, k.sakurada, r.nakamura}@aist.go.jp

Figure 1. The overall concept of the proposed model. From the negative image pairs, the representation learning model (left) learns features that are invariant to trivial events. The rare event detector (right) is then trained on the learned invariant features.
MyNote:
本文用disentangled representation方法,解决微小事件(罕见事件,rare event)检测。核心思想是,把两幅图片中,微小变化的部分看出是特殊特征,而其余内容部分,看成共同部分。解耦模型也是新的,看图1,它并没有采用交叉特殊部分的形式,因为本文最终想要的是fine-tuning这种结构,即输入本身就是两幅图,一个认为是正常图,另外一个认为的发生微小事件的图。但,这种形式比交叉形式更难设计,如何让特殊特征s不包含共同特征c,共同特征c不包含特殊特征s。这就是损失函数的任务。本文提出了三种损失函数。
Abstract
This paper presents a novel method for rare event detection from an image pair with class-imbalanced datasets. A straightforward approach for event detection tasks is to train a detection network from a large-scale dataset in an end-to-end manner. However, in many applications such as building change detection on satellite images, few positive samples are available for the training. Moreover, scene image pairs contain many trivial events, such as in illumination changes or background motions. These many trivial events and the class imbalance problem lead to false alarms for rare event detection.
问题描述。提出了一种基于类不平衡数据集的图像对罕见事件(rare event)检测方法。事件检测任务的一种直接的方法是从一个大规模数据集中以端到端的方式训练一个检测网络。然而,在许多应用中,如建立变化检测卫星图像,很少有正样本的训练。此外,场景图像对包含许多 trivial 事件,如照明变化或背景运动。这些琐碎的事件和类不平衡问题会导致 rare 事件检测的错误警报。
In order to overcome these difficulties, we propose a novel method to learn disentangled representations from only low-cost negative samples. The proposed method disentangles different aspects in a pair of observations: variant and invariant factors that represent trivial events and image contents, respectively.
方法简介。
The effectiveness of the proposed approach is verified by the quantitative evaluations on four change detection datasets, and the qualitative analysis shows that the proposed method can acquire the representations that disentangle rare events from trivial ones.
实验结论。
Introduction
事件检测的背景:在计算机视觉领域,基于图像对的事件检测作为图像相似度估计已经得到了广泛的研究。图像之间的相似度估计是基本问题之一,它可以应用于许多任务,如变化检测[11,14,20,25],图像检索与匹配[3,23,33],识别[26,31],立体匹配[9,34]。由于最近深特征的成功,图像比较方法有了实质性的进展。然而,总的来说,他们需要大量的数据集来充分利用深层特征的表达能力。
件检测中存在的问题和难点:在图像相似度估计的背景下,考虑了从图像对中检测罕见事件的特殊任务,如检测一对卫星图像上的建筑物变化,或通过对比产品的图像来检测制造缺陷。该任务的一个挑战在于难以收集训练样本。由于寻找稀有样本是一项劳动密集型任务,因此训练数据集中正样本往往很少。此外,图像对通常包含许多不感兴趣的难处理的(cumbersome)事件(例如,光照变化、图像配准错误、阴影变化、背景运动或季节变化)。这些小事件和类不平衡问题很可能导致了小事件的假警报,或者漏掉一些罕见事件的预警。
本文解决上述问题的方法:提出了一种新的网络架构,仅使用低成本的负图像进行解耦表示学习。图1演示了所提方法的总体概念。通过在图像内容之间引入相似度约束,训练网络将每幅图像编码为两个独立的特征:具体的特征和共同的特征。共同的特征表示对琐碎事件(trivial event)不变的图像内容,而特定特征表示与琐碎事件相关的混合信息 (例如,光照、阴影或背景运动)。这种解耦只需要通过低成本的负样本来学习,因为负样本包含了关于琐碎事件的丰富信息。一旦获得了共同的特征,就可以使用少量的训练样本在学习的表示上建立罕见事件的检测器。
Method
Overview
图 2 显示了本文提出的模型。该模型由共享参数的两个VAEs分支组成。每个VAE提取两种类型的特征表示:共同的和特定的。它们分别代表输入图像对的不同方面,不变因子和变因子。在罕见事件(rare event)检测中,具体特征表示trivial事件,共同特征表示不受trivial事件影响的图像内容。为了实现这一分离,引入了公共特征之间的相似性约束。这些共同特征的关键方面是它们对普通事件是不变的,这应该有助于从trivial事件区分出目标事件。

Figure 2. Schematics of the proposed representation learning method. The model takes a pair of images xA and xB as input. For each image, the encoder extracts common and specific features, and the decoder reconstructs the input. The key feature of the model is the similarity loss Lsim. This loss constrains the common features to extract invariant factors between xA and xB. Another feature is the activation loss Lact. This loss encourages the mean vector of the common features (µ c ) to be activated, which avoids a trivial solution – (σ c , µ c ) = (1, 0) – for any input.
Variational Auto-encoder
变分式自动编码器 VAE 是一种深层生成模型,将输入 x∈X 与潜变量 z∈Z 的联合分布定义为  。通常将
。通常将 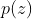 设置为均值和单位方差均为零的高斯分布。
设置为均值和单位方差均为零的高斯分布。
利用带参数 θ 的深度神经网络 (decoder) 对生成分布  进行建模,并且通过最大化边际似然度
进行建模,并且通过最大化边际似然度
pθ(x) = ∑z pθ(x, z) 来训练模型参数。
然而,当p (x|z) 是一个神经网络时,边际似然就变得难以处理。因此,改用以下变分下界:

在上式中, 是另一种近似后验分布
是另一种近似后验分布  的深度神经网络 (encoder)。Eq.(1) 的第一项可以看作是经典的自动编码器的重构误差,第二项可以看作是正则化项。
的深度神经网络 (encoder)。Eq.(1) 的第一项可以看作是经典的自动编码器的重构误差,第二项可以看作是正则化项。
为了使下界在编码器参数可微,使用了一种称为重新参数化(reparameterization)的技术:

在这里,⊙ 表示元素相乘。在这种情况下,编码器成为一个输出后验分布的均值和方差的深度神经网络。
Representation Learning
VAE提供了一种无监督的方法来学习潜在(latent)表示。给定输 入x,可以使用编码器分布 推断潜在表示。其目的是学习编码器分布  ,其中的潜变量被解开,使zc和zs分别代表给定的图像对的不变因子和变因子(invariant and variant factors)。为此,构建了一个模型,其中包含两个相互共享参数的 VAE 分支。如图 2 所示,将输入图像
,其中的潜变量被解开,使zc和zs分别代表给定的图像对的不变因子和变因子(invariant and variant factors)。为此,构建了一个模型,其中包含两个相互共享参数的 VAE 分支。如图 2 所示,将输入图像  输入到不同的VAE分支中,提取每个分支的潜变量zc和zs。利用以下损失函数对 VAE 的参数进行训练:
输入到不同的VAE分支中,提取每个分支的潜变量zc和zs。利用以下损失函数对 VAE 的参数进行训练:
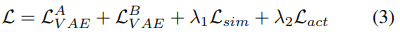
分别为输入图像 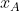 和
和 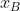 的 VAE 损失。Lsim 是一个相似性损失函数,它约束共同特征来表示成对图像之间的不变因子。Lact 是一个激活丢失函数,它鼓励激活共同特性,以避免包含 trivial 的解。
的 VAE 损失。Lsim 是一个相似性损失函数,它约束共同特征来表示成对图像之间的不变因子。Lact 是一个激活丢失函数,它鼓励激活共同特性,以避免包含 trivial 的解。
Variational auto-encoder loss
VAE各分支的联合分布成为

推理模型是:

VAE的损失函数变为:
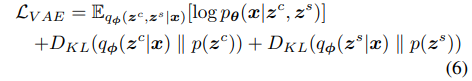
Similarity loss
为了将公共特征编码为输入图像对中的不变因子,在xA和xB中提取的公共特征对之间引入如下相似性损失

其中 D 定义潜在变量之间的统计距离。一个简单的候选是两个后置的中心  和
和  之间的 L2 或 L1 距离。但是,如图3,当后验分布在每个潜在维度上的方差不同时,质心之间的距离不反映分布之间的距离。
之间的 L2 或 L1 距离。但是,如图3,当后验分布在每个潜在维度上的方差不同时,质心之间的距离不反映分布之间的距离。

因此,本文使用一种马氏距离如下:

Activation loss
相似约束的一个问题是存在一个 trivial 解(trivial solution)。通过将公共特征的均值向量设为所有的零,可以完全满足约束条件。在这种情况下,输入中的所有信息都由特定特征编码,共同特征不代表任何信息。为了避免这种情况,引入了另一个损失,以鼓励激活公共特性。

Fine-tuning
现在已经获得了可以分别提取公共特征和特定特征的编码器。下一步,我们利用从每幅图像中提取的共同特征 和 ,建立一个事件检测器网络Cψ。
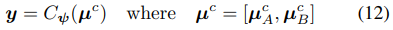
利用交叉熵损失在一个ground truth label t上训练分类器。

在微调阶段,联合训练分类器参数和编码器参数。由于常见特征表示的图像内容不受 trivial事件的影响,因此即使使用少量的标签,稳定的事件检测器也可以有效地训练。在微调阶段,负样本随机(欠)取样,以获得与正样本相同数量的样本。