SQL(Structured Query Language)是一个对数据库进行增删改查的语言。不过这玩意儿还是挺难理解的。所以我就写了这篇文章,希望能帮助到您。为了方便阐述,我做了以下表格作为数据表进行演示:
ABOUT
| NAME(char(5)) |
SELL/万(int) |
AUTHOR(char(5)) |
ID(char(6)) |
| 聪明人 |
10086 |
人 |
079154 |
| 聪明狗 |
9494 |
狗 |
088399 |
| 聪明羊 |
9088 |
羊 |
091650 |
| 阳了个阳 |
10030 |
新冠 |
117014 |
提取:
下面是一个最基础的的提取语句:
SELECT 列名 FROM 表名;
根据我们的表,我们的提取代码是:
SELECT * FROM ABOUT;
提取出结果:

那么,如果我们想要提取出票房一亿以上的优质电影,那该怎么办呢?这个时候我们就要用上where子句声明条件,就像下面这样:
SELECT 列名 FROM 表名 WHERE 条件;
根据我们的表,我们可以得出以下代码;
SELECT * FROM ABOUT WHERE SELL >= 10000;
提取出结果:

但是有些时候声明条件的时候,我们希望一次提取出所有有一个特征的数据而不是单一的数据,怎么办呢?
这时候我们就要用到LIKE子句来声明模糊搜索的条件,下面一句代码会提取出所有名称开头是聪明的是数据:
SELECT * FROM ABOUT WHERE NAME LIKE '聪明%';
其中条件里面的"%"表示任意多个字符,还有一个"_"表示任意单个字符。
执行上面的代码,可以得到下面的结果:

如果我们要把这些数据按照票房(SELL列)排列的话,那我们就要使用ORDERED BY SELL进行排列,就像下面这样:
SELECT * FROM ABOUT WHERE NAME LIKE "聪明%" ORDER BY SELL;
结果是这样的:

从结果里我们可以看到,数据已经按照从小到大的顺序排列起来了,任务达成!
除了这些,我们还可以用AND和OR子句把WHERE后面的条件连起来。
如果我们想要的是票房9000~10000万之间的数据,那该怎么办?我们需要用到BETWEEN子句声明范围,就像这样:
SELECT * FROM ABOUT WHERE SELL BETWEEN 9000 AND 10000;
结果如下:

除了用这些关键字声明,我们还可以用计算函数进行查询,具体的名称与功能如下:
计算函数与其功能
| 计算函数 |
功能 |
| count(*) |
求行数 |
| count(列名) |
求非空值行数 |
| count(distinct 列名) |
忽略空格与重复行之后求行数 |
| sum(列名) |
求取各行的总和(只适用于int列) |
| avg(列名) |
求取各行的平均值(只适用于int列) |
| max(列名) |
求取各行的最大值(只适用于int列) |
| min(列名) |
求取各行的最小值(只适用于int列) |
接下来我们分别实践一下这些函数:
SELECT COUNT(*) FROM ABOUT;

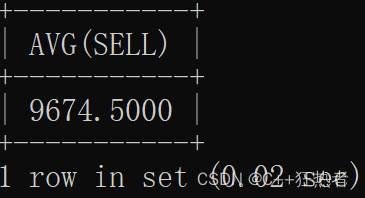
SELECT AVG(SELL) FROM ABOUT;
SELECT SUM(SELL) FROM ABOUT;

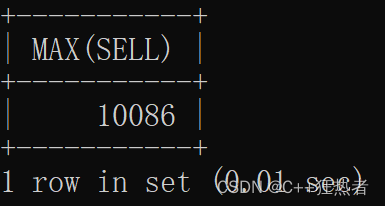
SELECT MAX(SELL) FROM ABOUT;
SELECT MIN(SELL) FROM ABOUT;

我们还可以利用重复数据进行分组,然后求每组的最大值/最小值/平均值/总和,再把每组的信息显示出来,由于我们手上的数据没有重复,所以不做示范。不过语法如下:
SELECT 函数(列名) FROM 表名 GROUP BY 列名;
创建:
不管在执行什么语句之前,都得先创建一个容器。具体能创建什么种类的容器,下面就说的很清楚:

数据库:
下面是一个标准的创建数据库的命令:
CREATE DATABASE TEST_DB;
数据库还简单,表就要详谈了。
表:
如果要创建一个表,先打入CREATE TABLE <这里替换成你的表名称>,后面再打一对括号,括号里面就是表的列名及每列的类型,类型如下:
数据类型
| 数据类型 |
说明 |
| INT |
整型数字 |
| REAL |
实数(浮点数) |
| CHAR(N) |
不可变长度字符串 |
| VARCHAR(N) |
可变长度字符串 |
| BLOB |
二进制数据 |
创建一个表就像下面这样:
CREATE TABLE PRODUCT(ID INT,NAME VARCHAR(10),PRICE REAL,VIDEO BLOB);
如果我们希望一个列上的数据不许出现重复,怎么办呢?我们就在创建的时候在那一列的数据类型后面加上一个UNIQUE,就像这样:
CREATE TABLE PRODUCT(ID INT UNIQUE,NAME VARCHAR(10) UNIQUE,PRICE REAL,VIDEO BLOB);
关于其他的条件请参见下表:
表格的限制
| 限制 |
含义 |
| PRIMARY KEY |
设定主关键字 |
| UNIQUE |
唯一 |
| NOT NULL |
不许出现NULL值 |
| CHECK |
检查范围 |
| DEFAULT |
设定默认值 |
| FOREIGN KEY |
设定外关键字 |
这样约束数据库的数据避免出现矛盾的数据,这样就可以正确的管理数据了。
视图:
如何创建视图呢?视图是基于一个条件而从基本表中提取出来的数据。如何创建视图呢?就像下面那样:
CREATE VIEW VIEW_TABLE(列1 类型,列2 类型...列n 类型) AS SELECT 列名 FROM 基本表 WHERE 条件;
然后这个视图就可以跟正常表一样操作了!
修改:
有三种修改的方法:INSERT,UPDATE,DELETE。
INSERT:
insert是插入,也就是加入新记录。语法如下:
INSERT INTO 表名(这里填入这个表的所有列名(逗号分隔)) VALUES(这里填入分别要插入每一行的数据(逗号分隔));
UPDATE:
update是更新,就是修改记录,就像下面这样:
UPDATE 表名 SET 列名 = 修改数据 WHERE 条件;
如果上面的代码没有加WHERE子句,那么所有记录皆会被修改。
DELETE:
DELETE是删除,它会删除整一行数据。语法如下:
DELETE FROM 表名 WHERE 条件;
如果上面没有加WHERE子句,那么全部记录皆会被删除。