本文将会通过一条指令在LLVM中的不同阶段,从源程序语言中的语义结构到成为机器二进制码来研究LLVM的工作原理。
本文不会介绍LLVM是如何工作的,这需要理解LLVM的设计以及code以及各种细节。
输入代码
我们从一段C代码开始探险,如下:
int foo(int aa, int bb, int cc) {
int sum = aa + bb;
return sum / cc;
}
本文将会重点关注除法操作。
Clang
Clang是作为LLVM的前端使用的,负责将C,C++,以及ObjC源程序转化为LLVM IR。
Clang主要的复杂在于它需要正确的parse以及语义分析C++程序;解析C程序还是比较简单的。
Clang的parser会建立一个抽象语法树Abstract Syntax Tree(AST). Clang主要通过AST进行处理。对于我们的除法操作来说,Clang会在AST中创建一个BinaryOperator节点,其带有BO_div操作属性。Clang的代码生成器然后会从该节点产生sdiv LLVM IR指令,因为这是一个有符号整型的除法操作。
LLVM IR
上述程序的LLVM IR如下:
define i32 @foo(i32 %aa, i32 %bb, i32 %cc) nounwind {
entry:
%add = add nsw i32 %aa, %bb
%div = sdiv i32 %add, %cc
ret i32 %div
}
在LLVM IR中,sdiv是一个Binary Operator,是SDiv指令的subclass。像其他的任何指令一样,它可以被LLVM分析并转化。
代码生成器 code generator是LLVM中最复杂的一个部分,它的任务是将相对high-level,不依赖目标机器的LLVM IR转化为 low-level的,依赖目标的机器指令(MachineInstr)。在生成Machine Instr之前,LLVM IR的指令会经过“Selection DAG node”转化。
SelectionDAG Node
Selection DAG node是由SelectionDAGBuilder在SelectionDAGSel阶段创建的,这是instruction selection的主要部分。
SelectionDAGIsel会走遍IR指令,在指令上调用SelectionDAGBuilder::visit dispatcher。处理SDiv指令的是SelectionDAGBuilder::visitDiv. 它需要在DAG中创建一个新的SDNode节点,其操作符为ISD::SDIV.
最初的DAG只是部分依赖目标机器的。在LLVM的命名中,这被叫做“illegal”,因为它的类型可能无法被目标机器支持。同样,其中包含的操作可能也无法支持。
有几种方式来可视化DAG;一种是将 -debug flag传递到LLC,这将会在Selection Phase的过程中创建DAG的文本dump。另一种方式就是使用-view选项,可以dump并display graph的真实图像。如下就是在DAG创建之后的图像:
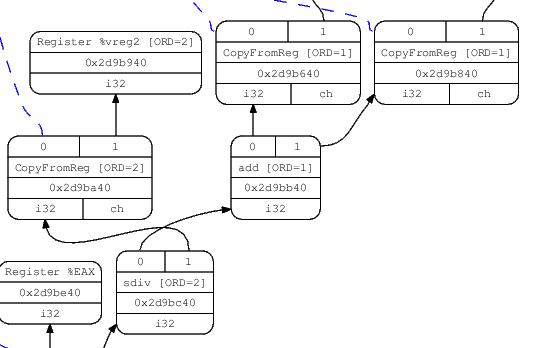
在SelectionDAG从DAG节点真正的输出机器指令之前,这些节点也会经历一些其他的变化。其中最重要的就是类型和操作合法化,通过使用target-specific hook来将所有的操作和类型转为那些机器真正支持的操作和类型。
将SDiv合规化到sdivrem on X86
X86中的idvi指令,同时计算商和余数,并且将结果存到两个不同的寄存器中,因为LLVM的指令选择会将这类指令(叫做ISD::SDIVREM)和只计算商的操作(ISD::SDIV)区分开,因此我们的DAG 节点会在DAG合规化阶段被“legalized”,如果目标机器是X86的话。
代码生成器使用的一个重要的接口:TargetLowering,来将传递target-specific的信息传输到target-indepent算法中。 目标会实现这个接口来描述LLVM IR指令应该怎样被lowered到合规的SelectionDAG操作。 x86的对应接口叫做X86TargetLowering。在它的构造函数中,它标记了那些操作应当被合规化,ISD::SDIV就是其中之一。如下是该段代码的注释:
// Scalar integer divide and remainder are lowered to use operations that
// produce two results, to match the available instructions. This exposes
// the two-result form to trivial CSE, which is able to combine x/y and x%y
// into a single instruction.
当SelectionDAGLegalize::LegalizeOp看到SDIV节点有Expand flag时,它会将其替换为ISD::SDIVREM。这个例子展示了在Selection DAG格式时,一个操作可能经历的变化。
Instruction selection - from SDNode to MachineSDNode
指令生成中的下一步即为instruction selection。 LLVM提供了一个通用的table-based instruction selection 机制,该文件通过TableGen工具自动生成。
然而很多目标后端,都选择自己写SelectionDAGIsel::Select的实现代码来手动处理一些指令。其他的指令会送到叫做SelectCode的auto-generated selector。
X86后端手动的处理ISD::SDIVREM来解决一些特殊的情况和优化。在这个阶段创建的DAG节点叫做MachineSDNode,是SDNode的一个subclass,会存有生成实际的机器指令的信息,但是仍然是以DAG node格式的。此时,真正的的X86指令op code会被选择,在这个例子中为X86::IDIV32r。
调度和发射MachineInstr
此时我们的代码还是DAG格式的,但是CPU不会执行DAG,他们执行的是线性的指令队列。调度的目标是通过给操作节点一个顺序来线性化DAG,最简单的方式就是按照拓扑的方式排序DAG,但是LLVM的代码生成器使用了更为聪明的方式,比如register pressure reduction,来尝试产生更快的代码。
一般每个目标都有自己的hook,来实现指令的调度。
最终,调度器会通过使用InstrEmitter::EmitMachineNode函数将SDNode转化,发射一系列的指令到MachineBasicBlock。这些指令使用MachineInstr 的格式(MI 格式),DAG可以被销毁了。
我们通过调用llc -print-machineinstr 来看看产生的machine instruction。看看在instruction selecttion之后的第一次输出:
# After Instruction Selection:
# Machine code for function foo: SSA
Function Live Ins: %EDI in %vreg0, %ESI in %vreg1, %EDX in %vreg2
Function Live Outs: %EAX
BB#0: derived from LLVM BB %entry
Live Ins: %EDI %ESI %EDX
%vreg2<def> = COPY %EDX; GR32:%vreg2
%vreg1<def> = COPY %ESI; GR32:%vreg1
%vreg0<def> = COPY %EDI; GR32:%vreg0
%vreg3<def,tied1> = ADD32rr %vreg0<tied0>, %vreg1, %EFLAGS<imp-def,dead>; GR32:%vreg3,%vreg0,%vreg1
%EAX<def> = COPY %vreg3; GR32:%vreg3
CDQ %EAX<imp-def>, %EDX<imp-def>, %EAX<imp-use>
IDIV32r %vreg2, %EAX<imp-def>, %EDX<imp-def,dead>, %EFLAGS<imp-def,dead>, %EAX<imp-use>, %EDX<imp-use>; GR32:%vreg2
%vreg4<def> = COPY %EAX; GR32:%vreg4
%EAX<def> = COPY %vreg4; GR32:%vreg4
RET
# End machine code for function foo.
注意输出是按照SSA格式的,其中的一些寄存器使用的是虚拟寄存器(比如%vreg1)。
寄存器分配 —从SSA到non-SSA机器指令
除了一些定义好的异常,指令选择器产生的代码是SSA(静态单赋值)格式的。尤其是,它假想此时我们有无穷的虚拟寄存器。当然,这是假的。因此,指令产生器的下一步就是调用寄存分配器,该分配器的任务就是使用物理寄存器替换掉虚拟寄存器。
上文所说的异常也是比较重要并且有趣的,因此我们再多讨论一点。
一些架构中的一些指令只能使用特定的寄存器。一个例子就是x86中的除法操作,要求输入在EDX和EAX寄存器中。指令选择器知道这些限制,因此我们在上面的代码中可以看到,IDIV32r的输入是物理寄存器,而不是虚拟寄存器。这个是通过X86DAGToDAGISel::Select处理的。
寄存器分配器会处理所有的非固定寄存器,此外,SSA格式的机器指令还会进行一些优化。
输出代码
现在我们原始的C代码已经被翻译为MI 格式,一个使用instruction objects(MachineInstr)组成的MachineFunction。此时,代码生成器完成了它的工作,我们可以输出代码。在LLVM中,有两种方式实现它,一种是使用JIT来产生可执行的,ready-to-run code到内存中。另一种就是MC,是一种复杂的object-file-and-assembly生成器。MC现在被用于汇编和目标文件生成。MC也允许使用MCJIT,是基于MC layer的JIT-ting 框架。
LLVMTargetMachine::addPassesToEmitMachineCode定义了JIT产生代码的pass序列。它调用了addPassesToGenerateCode,该函数调用了所有需要的passes,将IR转为MI格式。下一步,叫做addCodeEmitter,是一个目标特定target-specific的pass用来将MI转化为实际的machine code。因为MI已经十分low-level了,因此可以相对简单的将它们转化为可运行的machine code。X86代码对应的文件为lib/Target/X86/X86CodeEmitter.cpp。我们的除法操作此处不需要特殊的处理,因为MachineInstr已经包含了opcode和操作数了。它和其他的指令一般在emitInstruction中处理。
MCInst
LLVM如果是被用作静态编译器,那么MI被发送到MC layer中,来处理object-file emission,它也可以产生汇编文件。
LLVMTargetMachine::addPassesToEmitFile 负责定义需要产生目标文件的一系列操作。实际上MI-to-MCInst转化在AsmPrinter接口的EmitInstruction函数中完成。在X86中,使用X86AsmPrinter::EmitInstruction函数实现,该函数会分派给X86McInstLower来处理。与JIT相似,除法指令和其他指令相同,不需要特殊的处理。
通过传递-show-mc-inst到LLC,我们可以看到在MC-level创建的指令:
foo: # @foo
# BB#0: # %entry
movl %edx, %ecx # <MCInst #1483 MOV32rr
# <MCOperand Reg:46>
# <MCOperand Reg:48>>
leal (%rdi,%rsi), %eax # <MCInst #1096 LEA64_32r
# <MCOperand Reg:43>
# <MCOperand Reg:110>
# <MCOperand Imm:1>
# <MCOperand Reg:114>
# <MCOperand Imm:0>
# <MCOperand Reg:0>>
cltd # <MCInst #352 CDQ>
idivl %ecx # <MCInst #841 IDIV32r
# <MCOperand Reg:46>>
ret # <MCInst #2227 RET>
.Ltmp0:
.size foo, .Ltmp0-foo
目标文件(或者汇编代码)的发射是通过MCStreamer 接口实现的。目标文件通过MCObjectStreamer产生,该类会因为实际上的目标文件进一步扩展。比如,ELF 产生时在MCELFStreamer产生的。MCInst会先经历MCObjectStreamer::EmitInstruction,然后是针对特定格式的EmitInstToData。最终产生的二进制格式的指令,是目标特定的,这是通过MCCodeEmitter接口(比如X86MCCodeEmitter)。此时的LLVM的代码,一部分是完全通用的,一部分是依赖特定输出目标文件格式的,一部分则是针对特定目标机器的。
Assemblers and disassemblers
MCInst是一个比较简单的格式。它尽可能的去除语义信息,只保存指令的操作码和操作数。像LLVM IR一样,这也是一个内部的表示,可以有不同的编码格式,最常使用的是汇编和二进制文件。
llvm-mc是一个使用MC框架来实现汇编器和反汇编器的工具。在内部,MCInst被用于在二进制和文本格式间进行翻译。此时,工具并不关心是什么编译器产生的汇编或者目标文件。
个人总结:
- Clang将输入源程序转为LLVM IR
- SelectionDAGBuilder遍历IR指令产生Selection DAG,此时DAG基本上还是非目标依赖的
- SelectionDAGLegalize使用TargetLowering对SelectionDAG,针对operation和type进行针对目标依赖的合规化
- SelectCode进行instruction selection,产生MachineSDNode(仍为DAG格式),包含对应的opcode
- InstrEmitter::EmitMachineNode产生线性序列的SSA格式的MachineInstr(MI)指令, DAG可以销毁
- 物理寄存器分配
- code emitter产生最终的目标文件
欢迎关注我的公众号《处理器与AI芯片》