导入所需的库模块:
import os
import cv2
import numpy as np
import tensorflow as tf2
import matplotlib.pyplot as plt
import tensorflow.compat.v1 as tf
import tensorflow.compat.v1 as tf
这句话是为了将tensorflow 2.x转为1.x,tensorflow1.x更能表现网络结构
import os
是调用系统,可有可无,为了不显示警告内容所以调用该模块
小批量训练法的数据分割:
def nextBatch(data,batch_size,n):
a=n*batch_size
b=(n+1)*batch_size
limdata=len(data[0])
if b>limdata:
b=limdata
a=b-batch_size
data_x=data[0][a:b]
data_y=data[1][a:b]
return data_x,data_y
这里是为了将数据集切割成小批量数据,完成训练,小批量训练结果更好。
CNN网络:
def main_train():
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
training_epochs=100
batch_count=20
L=32
M=64
N=128
O=625
with tf.device('/gpu:0'):
Xin=tf.placeholder(tf.float32,[None,28,28,1],name='Xin')
Yout=tf.placeholder(tf.float32,[None,10],name="Yout")
W1=tf.Variable(tf.random_normal([3,3,1,L],stddev=0.01))
W2=tf.Variable(tf.random_normal([3,3,L,M],stddev=0.01))
W3=tf.Variable(tf.random_normal([3,3,M,N],stddev=0.01))
W4=tf.Variable(tf.random_normal([N*4*4,O],stddev=0.01))
W5=tf.Variable(tf.random_normal([O,10],stddev=0.01))
b1=tf.Variable(tf.random_normal([L],stddev=0.01))
b2=tf.Variable(tf.random_normal([M],stddev=0.01))
b3=tf.Variable(tf.random_normal([N],stddev=0.01))
b4=tf.Variable(tf.random_normal([O],stddev=0.01))
b5=tf.Variable(tf.random_normal([10],stddev=0.01))
'''卷积层一'''
conv1a=tf.nn.conv2d(Xin,W1,strides=[1,1,1,1],padding='SAME')
conv1b=tf.nn.bias_add(conv1a,b1)
conv1c=tf.nn.relu(conv1b)
'''池化层一'''
conv1=tf.nn.max_pool(conv1c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层二'''
conv2a=tf.nn.conv2d(conv1,W2,strides=[1,1,1,1],padding='SAME')
conv2b=tf.nn.bias_add(conv2a,b2)
conv2c=tf.nn.relu(conv2b)
'''池化层二'''
conv2=tf.nn.max_pool(conv2c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层三'''
conv3a=tf.nn.conv2d(conv2,W3,strides=[1,1,1,1],padding='SAME')
conv3b=tf.nn.bias_add(conv3a,b3)
conv3c=tf.nn.relu(conv3b)
'''池化层三'''
conv3d=tf.nn.max_pool(conv3c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv3=tf.reshape(conv3d,[-1,W4.get_shape().as_list()[0]])
'''全连接层'''
FCa=tf.matmul(conv3,W4)+b4
FC=tf.nn.relu(FCa)
'''输出层'''
Y_=tf.matmul(FC,W5)+b5
Y=tf.nn.softmax(Y_,name="output")
'''损失'''
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=Y_, labels=Yout)
loss=tf.reduce_mean(cross_entropy)*100
correct_prediction=tf.equal(tf.argmax(Y,1),tf.argmax(Yout,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name='accuracy')
'''优化器'''
trainer=tf.train.RMSPropOptimizer(learning_rate=0.001,momentum=0.9).minimize(loss)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
out_init=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})
print("初始准确率为:{:.4f}%".format(out_init*100))
for epoch in range(training_epochs):
print("当前训练步为第{}步".format(epoch+1))
batch_size=int(len(y_tr)/batch_count)
for i in range(batch_count):
batch_x,batch_y=nextBatch([x_tr[0:20000],y_tr[0:20000]],batch_size,i)
sess.run(trainer,feed_dict={Xin:batch_x,Yout:batch_y})
out=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})
print("当前准确率为:{:.4f}%".format(out*100))
'''当前会话存储'''
if out>out_init:
out_init=out
saver=tf.train.Saver()
saver.save(sess,r".\savefile\CNN\FigureCNN.ckpt")
下面做详细分析。
首先要导入手写数据库,tensorflow2.0自带手写字体数据库,用下面语句导入:
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()
x_tr0,y_tr0是60000个训练集的图片和标签。图片是28×28像素,标签是该图像所对应的数字。
x_te0,y_te0是10000个测练集的图片和标签。图片是28×28像素,标签是该图像所对应的数字。
在神经网络中,我们输出是10类,利用softmax函数做输出,因此标签的形式应为10位的,数字0应为“1000000000”,数字1为“0100000000”,数字2为“0010000000”,…,数字9为“0000000001”。
下面改变输出标签的格式:
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
此外,数据输入格式也要做改变,输入数据是28×28像素黑白图片,读入信息是2阶矩阵,在网络中改为3阶矩阵,这里进行形式变换:
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
接下来输入网络计算的相关参数:
training_epochs=100
batch_count=20
L=32
M=64
N=128
O=625
接下来,神经网络可以使用cpu计算,也可以使用gpu计算,cpu计算格式为:
with tf.device('/cpu:0'):
gpu计算格式为:
with tf.device('/gpu:0'):
如果不写这两句话,按照安装的tensorflow版本默认计算。我安装的tensorflow是gpu版本,默认进行gpu计算。
下面,定义网络的权值阈值:
W1=tf.Variable(tf.random_normal([3,3,1,L],stddev=0.01))
W2=tf.Variable(tf.random_normal([3,3,L,M],stddev=0.01))
W3=tf.Variable(tf.random_normal([3,3,M,N],stddev=0.01))
W4=tf.Variable(tf.random_normal([N*4*4,O],stddev=0.01))
W5=tf.Variable(tf.random_normal([O,10],stddev=0.01))
b1=tf.Variable(tf.random_normal([L],stddev=0.01))
b2=tf.Variable(tf.random_normal([M],stddev=0.01))
b3=tf.Variable(tf.random_normal([N],stddev=0.01))
b4=tf.Variable(tf.random_normal([O],stddev=0.01))
b5=tf.Variable(tf.random_normal([10],stddev=0.01))
下面构建CNN网络:
Xin=tf.placeholder(tf.float32,[None,28,28,1],name='Xin')
Yout=tf.placeholder(tf.float32,[None,10],name="Yout")
'''卷积层一'''
conv1a=tf.nn.conv2d(Xin,W1,strides=[1,1,1,1],padding='SAME')
conv1b=tf.nn.bias_add(conv1a,b1)
conv1c=tf.nn.relu(conv1b)
'''池化层一'''
conv1=tf.nn.max_pool(conv1c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层二'''
conv2a=tf.nn.conv2d(conv1,W2,strides=[1,1,1,1],padding='SAME')
conv2b=tf.nn.bias_add(conv2a,b2)
conv2c=tf.nn.relu(conv2b)
'''池化层二'''
conv2=tf.nn.max_pool(conv2c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层三'''
conv3a=tf.nn.conv2d(conv2,W3,strides=[1,1,1,1],padding='SAME')
conv3b=tf.nn.bias_add(conv3a,b3)
conv3c=tf.nn.relu(conv3b)
'''池化层三'''
conv3d=tf.nn.max_pool(conv3c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv3=tf.reshape(conv3d,[-1,W4.get_shape().as_list()[0]])
'''全连接层'''
FCa=tf.matmul(conv3,W4)+b4
FC=tf.nn.relu(FCa)
'''输出层'''
Y_=tf.matmul(FC,W5)+b5
Y=tf.nn.softmax(Y_,name="output")
tf.placeholder()占位符是用于接收外界输入
tf.nn.conv2d()进行卷积操作
tf.nn.bias_add()偏置的加法操作
tf.nn.relu()Relu函数,用作卷积层激活函数
tf.nn.max_pool()最大池化函数,池化是用于减少特征量,避免数据爆炸,但是也减少其中的信息量
tf.reshape()用于改变数据形态,全连接层之前要将数据扁平化,变为一维,便于输出计算
Y_=tf.matmul(FC,W5)+b5 这是全连接层的计算,权值相乘,阈值相加
tf.nn.softmax()是softmax函数,计算输出的概率
下面定义损失函数以及正确率计算函数:
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=Y_, labels=Yout)
loss=tf.reduce_mean(cross_entropy)*100
correct_prediction=tf.equal(tf.argmax(Y,1),tf.argmax(Yout,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name='accuracy')
下面定义优化器:
trainer=tf.train.RMSPropOptimizer(learning_rate=0.001,momentum=0.9).minimize(loss)
这里是RMS优化算法,参数包括学习率和动量
下面进行数据训练计算:
with tf.Session() as sess:
sess.run(init)
out_init=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})
print("初始准确率为:{:.4f}%".format(out_init*100))
for epoch in range(training_epochs):
print("当前训练步为第{}步".format(epoch+1))
batch_size=int(len(y_tr)/batch_count)
for i in range(batch_count):
batch_x,batch_y=nextBatch([x_tr[0:20000],y_tr[0:20000]],batch_size,i)
sess.run(trainer,feed_dict={Xin:batch_x,Yout:batch_y})
out=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})
print("当前准确率为:{:.4f}%".format(out*100))
x_tr[0:20000]和y_tr[0:20000]的说明:我的gpu是gtx1050Ti,显存是4G,两万张图片数据的输入是网络中数据的显存极限,再多的数据量就溢出了,不能完成训练。因此,我选择前两万张训练集数据作为输入,这个根据每个人的电脑不一样而不同。
with tf.Session() as sess:是构建会话且自动关闭
为了防止模型丢失,需要将模型存储下来。我们存储准确率最好的会话:
if out>out_init:
out_init=out
saver=tf.train.Saver()
saver.save(sess,r".\savefile\CNN\FigureCNN.ckpt")
读取模型和自己的图片测试:
def main_test():
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
road=[r".\savefile\CNN\FigureCNN.ckpt.meta",r".\savefile\CNN\FigureCNN.ckpt"]
sess=tf.InteractiveSession()
new_saver=tf.train.import_meta_graph(road[0])
new_saver.restore(sess,road[1])
tf.get_default_graph().as_graph_def()
Xin=sess.graph.get_tensor_by_name('Xin:0')
Yout=sess.graph.get_tensor_by_name("Yout:0")
accuracy=sess.graph.get_tensor_by_name('accuracy:0')
Y=sess.graph.get_tensor_by_name('output:0')
Ote=sess.run(accuracy,feed_dict={Xin:x_te,Yout:y_te})
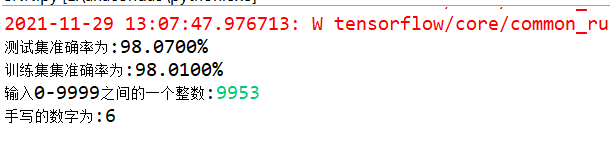
print("测试集准确率为:{:.4f}%".format(Ote*100))
Ote=sess.run(accuracy,feed_dict={Xin:x_tr[30000:40000],Yout:y_tr[30000:40000]})
print("训练集集准确率为:{:.4f}%".format(Ote*100))
u=eval(input("输入0-9999之间的一个整数:"))
if (u<0) or (u>9999):
print('错误!')
sess.close()
return
Otem=sess.run(Y,feed_dict={Xin:[x_te[u]]})
print('手写的数字为:{}'.format(Otem.argmax()))
plt.imshow(x_te[u].reshape(28,28))
plt.show()
for i in [0,2,4,5,9]:
roadpic=r'.\picturefile\handwriting'+str(i)+'.jpg'
pic=cv2.imread(roadpic,flags=0)
pic1=255-pic
pic=pic1.reshape(-1,28,28,1)
Otem=sess.run(Y,feed_dict={Xin:pic})
print('手写的数字为:{}'.format(Otem.argmax()))
plt.imshow(pic1)
plt.show()
sess.close()
return
下面进行详细分析,先导入数据和测试集输出数据变换形态:
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
读取已存储的模型:
road=[r".\savefile\CNN\FigureCNN.ckpt.meta",r".\savefile\CNN\FigureCNN.ckpt"]
sess=tf.InteractiveSession()
new_saver=tf.train.import_meta_graph(road[0])
new_saver.restore(sess,road[1])
tf.get_default_graph().as_graph_def()
Xin=sess.graph.get_tensor_by_name('Xin:0')
Yout=sess.graph.get_tensor_by_name("Yout:0")
accuracy=sess.graph.get_tensor_by_name('accuracy:0')
Y=sess.graph.get_tensor_by_name('output:0')
计算测试集和训练集其他数据的准确率:
Ote=sess.run(accuracy,feed_dict={Xin:x_te,Yout:y_te})
print("测试集准确率为:{:.4f}%".format(Ote*100))
Ote=sess.run(accuracy,feed_dict={Xin:x_tr[30000:40000],Yout:y_tr[30000:40000]})
print("训练集集准确率为:{:.4f}%".format(Ote*100))
随机选择测试集的一个数据,输出模型预测结果并查看这个数据,看看结果:
u=eval(input("输入0-9999之间的一个整数:"))
if (u<0) or (u>9999):
print('错误!')
sess.close()
return
Otem=sess.run(Y,feed_dict={Xin:[x_te[u]]})
print('手写的数字为:{}'.format(Otem.argmax()))
plt.imshow(x_te[u].reshape(28,28))
plt.show()
将自己写的28×28的图片预测结果:
for i in [0,2,4,5,9]:
roadpic=r'.\picturefile\handwriting'+str(i)+'.jpg'
pic=cv2.imread(roadpic,flags=0)
pic1=255-pic
pic=pic1.reshape(-1,28,28,1)
Otem=sess.run(Y,feed_dict={Xin:pic})
print('手写的数字为:{}'.format(Otem.argmax()))
plt.imshow(pic1)
plt.show()
roadpic是图片的位置,共5张自己制作的图片:





所有程序:
'''
Created on 2021年11月2日
@author: 紫薇星君
'''
import os
import cv2
import numpy as np
import tensorflow as tf2
import matplotlib.pyplot as plt
import tensorflow.compat.v1 as tf
def nextBatch(data,batch_size,n):
a=n*batch_size
b=(n+1)*batch_size
limdata=len(data[0])
if b>limdata:
b=limdata
a=b-batch_size
data_x=data[0][a:b]
data_y=data[1][a:b]
return data_x,data_y
def main_train():
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
training_epochs=100
batch_count=20
L=32
M=64
N=128
O=625
with tf.device('/gpu:0'):
Xin=tf.placeholder(tf.float32,[None,28,28,1],name='Xin')
Yout=tf.placeholder(tf.float32,[None,10],name="Yout")
W1=tf.Variable(tf.random_normal([3,3,1,L],stddev=0.01))
W2=tf.Variable(tf.random_normal([3,3,L,M],stddev=0.01))
W3=tf.Variable(tf.random_normal([3,3,M,N],stddev=0.01))
W4=tf.Variable(tf.random_normal([N*4*4,O],stddev=0.01))
W5=tf.Variable(tf.random_normal([O,10],stddev=0.01))
b1=tf.Variable(tf.random_normal([L],stddev=0.01))
b2=tf.Variable(tf.random_normal([M],stddev=0.01))
b3=tf.Variable(tf.random_normal([N],stddev=0.01))
b4=tf.Variable(tf.random_normal([O],stddev=0.01))
b5=tf.Variable(tf.random_normal([10],stddev=0.01))
'''卷积层一'''
conv1a=tf.nn.conv2d(Xin,W1,strides=[1,1,1,1],padding='SAME')
conv1b=tf.nn.bias_add(conv1a,b1)
conv1c=tf.nn.relu(conv1b)
'''池化层一'''
conv1=tf.nn.max_pool(conv1c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层二'''
conv2a=tf.nn.conv2d(conv1,W2,strides=[1,1,1,1],padding='SAME')
conv2b=tf.nn.bias_add(conv2a,b2)
conv2c=tf.nn.relu(conv2b)
'''池化层二'''
conv2=tf.nn.max_pool(conv2c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层三'''
conv3a=tf.nn.conv2d(conv2,W3,strides=[1,1,1,1],padding='SAME')
conv3b=tf.nn.bias_add(conv3a,b3)
conv3c=tf.nn.relu(conv3b)
'''池化层三'''
conv3d=tf.nn.max_pool(conv3c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv3=tf.reshape(conv3d,[-1,W4.get_shape().as_list()[0]])
'''全连接层'''
FCa=tf.matmul(conv3,W4)+b4
FC=tf.nn.relu(FCa)
'''输出层'''
Y_=tf.matmul(FC,W5)+b5
Y=tf.nn.softmax(Y_,name="output")
'''损失'''
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=Y_, labels=Yout)
loss=tf.reduce_mean(cross_entropy)*100
correct_prediction=tf.equal(tf.argmax(Y,1),tf.argmax(Yout,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name='accuracy')
'''优化器'''
trainer=tf.train.RMSPropOptimizer(learning_rate=0.001,momentum=0.9).minimize(loss)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
out_init=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})
print("初始准确率为:{:.4f}%".format(out_init*100))
for epoch in range(training_epochs):
print("当前训练步为第{}步".format(epoch+1))
batch_size=int(len(y_tr)/batch_count)
for i in range(batch_count):
batch_x,batch_y=nextBatch([x_tr[0:20000],y_tr[0:20000]],batch_size,i)
sess.run(trainer,feed_dict={Xin:batch_x,Yout:batch_y})
out=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})
print("当前准确率为:{:.4f}%".format(out*100))
'''当前会话存储'''
if out>out_init:
out_init=out
saver=tf.train.Saver()
saver.save(sess,r".\savefile\CNN\FigureCNN.ckpt")
return
def main_test():
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
road=[r".\savefile\CNN\FigureCNN.ckpt.meta",r".\savefile\CNN\FigureCNN.ckpt"]
sess=tf.InteractiveSession()
new_saver=tf.train.import_meta_graph(road[0])
new_saver.restore(sess,road[1])
tf.get_default_graph().as_graph_def()
Xin=sess.graph.get_tensor_by_name('Xin:0')
Yout=sess.graph.get_tensor_by_name("Yout:0")
accuracy=sess.graph.get_tensor_by_name('accuracy:0')
Y=sess.graph.get_tensor_by_name('output:0')
Ote=sess.run(accuracy,feed_dict={Xin:x_te,Yout:y_te})
print("测试集准确率为:{:.4f}%".format(Ote*100))
Ote=sess.run(accuracy,feed_dict={Xin:x_tr[30000:40000],Yout:y_tr[30000:40000]})
print("训练集集准确率为:{:.4f}%".format(Ote*100))
u=eval(input("输入0-9999之间的一个整数:"))
if (u<0) or (u>9999):
print('错误!')
sess.close()
return
Otem=sess.run(Y,feed_dict={Xin:[x_te[u]]})
print('手写的数字为:{}'.format(Otem.argmax()))
plt.imshow(x_te[u].reshape(28,28))
plt.show()
for i in [0,2,4,5,9]:
roadpic=r'.\picturefile\handwriting'+str(i)+'.jpg'
pic=cv2.imread(roadpic,flags=0)
pic1=255-pic
pic=pic1.reshape(-1,28,28,1)
Otem=sess.run(Y,feed_dict={Xin:pic})
print('高攀手写的数字为:{}'.format(Otem.argmax()))
plt.imshow(pic1)
plt.show()
sess.close()
return
if __name__=="__main__":
tf.disable_v2_behavior()
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
main_train()
main_test()
运行结果:


本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)