目录
版本说明
一、官方的说明
1.使用自定义分片算法
2.数据分片配置说明
二、正确的姿势
1.下载官方源码
2.配置启动sharding-proxy
3.代码、配置文件,结构说明
版本说明
| 组件 | 版本 | 备注 |
| Sharding-Proxy源码 | 4.1.1 | |
| Mysql | 8.x | |
一、官方的说明
1.使用自定义分片算法
你会发现如下的说明不能帮你什么🤣
当用户需要使用自定义的分片算法类时,无法再通过简单的inline表达式在yaml文件进行配置。可通过以下方式配置使用自定义分片算法。
- 实现ShardingAlgorithm接口定义的算法实现类。
- 将上述java文件打包成jar包。
- 将上述jar包拷贝至ShardingProxy解压后的conf/lib目录下。
- 将上述自定义算法实现类的java文件引用配置在yaml文件里tableRule的
algorithmClassName属性上,具体可参考配置规则。
2.数据分片配置说明
如下内容可能会有用一点,来源于:sharding-Jdbc配置说明 注意:仅我下面贴出来的有用,毕竟不是一个组件有些配置是不一样的。
dataSources: #数据源配置,可配置多个data_source_name
<data_source_name>: #<!!数据库连接池实现类> `!!`表示实例化该类
driverClassName: #数据库驱动类名
url: #数据库url连接
username: #数据库用户名
password: #数据库密码
# ... 数据库连接池的其它属性
shardingRule:
tables: #数据分片规则配置,可配置多个logic_table_name
<logic_table_name>: #逻辑表名称
actualDataNodes: #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
databaseStrategy: #分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: #用于单分片键的标准分片场景
shardingColumn: #分片列名称
preciseAlgorithmClassName: #精确分片算法类名称,用于=和IN。。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器
rangeAlgorithmClassName: #范围分片算法类名称,用于BETWEEN,可选。。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器
complex: #用于多分片键的复合分片场景
shardingColumns: #分片列名称,多个列以逗号分隔
algorithmClassName: #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器
inline: #行表达式分片策略
shardingColumn: #分片列名称
algorithmInlineExpression: #分片算法行表达式,需符合groovy语法
hint: #Hint分片策略
algorithmClassName: #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器
none: #不分片
tableStrategy: #分表策略,同分库策略
keyGenerator:
column: #自增列名称,缺省表示不使用自增主键生成器
type: #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
props: #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性
<property-name>: 属性名称
bindingTables: #绑定表规则列表
- <logic_table_name1, logic_table_name2, ...>
- <logic_table_name3, logic_table_name4, ...>
- <logic_table_name_x, logic_table_name_y, ...>
broadcastTables: #广播表规则列表
- table_name1
- table_name2
- table_name_x
defaultDataSourceName: #未配置分片规则的表将通过默认数据源定位
defaultDatabaseStrategy: #默认数据库分片策略,同分库策略
defaultTableStrategy: #默认表分片策略,同分库策略
defaultKeyGenerator: #默认的主键生成算法 如果没有设置,默认为SNOWFLAKE算法
type: #默认自增列值生成器类型,缺省将使用org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
props:
<property-name>: #自增列值生成器属性配置, 比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds
masterSlaveRules: #读写分离规则,详见读写分离部分
<data_source_name>: #数据源名称,需要与真实数据源匹配,可配置多个data_source_name
masterDataSourceName: #详见读写分离部分
slaveDataSourceNames: #详见读写分离部分
loadBalanceAlgorithmType: #详见读写分离部分
props: #读写分离负载算法的属性配置
<property-name>: #属性值
二、正确的姿势
1.下载官方源码
这个不用在说明了,没找到请到我的其他文章中发现有惊喜。
2.配置启动sharding-proxy
这个也不在叙述,没啥有营养的价值,我以实现如下代码,按照预期进行入库操作,步骤如下,请跟着我,别掉队😉
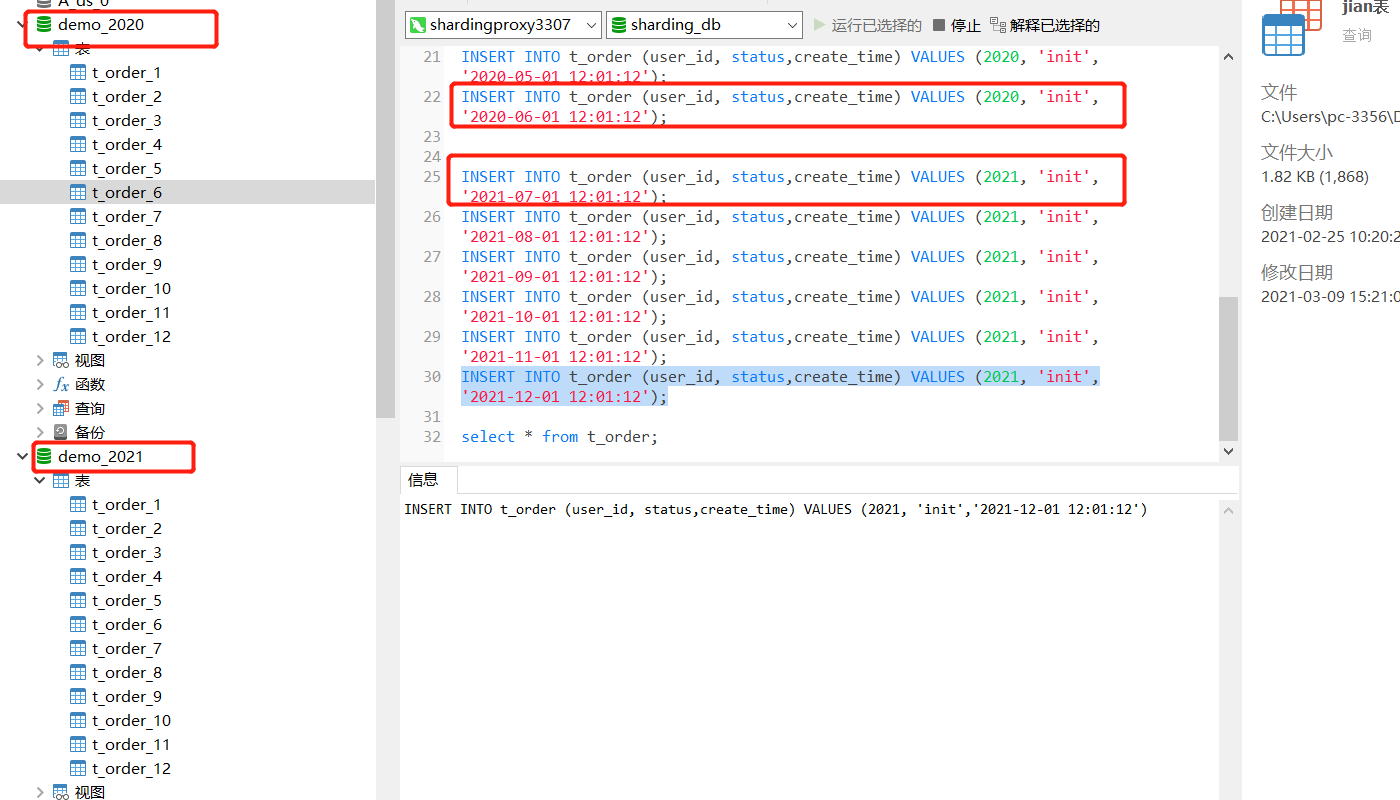
| 数据库配置,如下代码连接sharding-proxy代理在Navicat MySQL中运行,不会操作的也请看看其他文章 |
drop table IF EXISTS t_order;
CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, create_time TIMESTAMP NOT NUll ,status VARCHAR(50), PRIMARY KEY (order_id)); |
| 预期操作 |
#2020 入demo2020库
INSERT INTO t_order (user_id, status,create_time) VALUES (2020, ‘init’,’2020-01-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2020, ‘init’,’2020-02-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2020, ‘init’,’2020-03-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2020, ‘init’,’2020-04-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2020, ‘init’,’2020-05-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2020, ‘init’,’2020-06-01 12:01:12′);
#2021 入demo2021库
INSERT INTO t_order (user_id, status,create_time) VALUES (2021, ‘init’,’2021-07-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2021, ‘init’,’2021-08-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2021, ‘init’,’2021-09-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2021, ‘init’,’2021-10-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2021, ‘init’,’2021-11-01 12:01:12′);
INSERT INTO t_order (user_id, status,create_time) VALUES (2021, ‘init’,’2021-12-01 12:01:12′); |
#检查插入数据,本次操作有且只能有12条记录,并去真实库,真实表中进行数据检验,也就是33080实例中的demo2020库和demo2021库
select * from t_order; |
3.代码、配置文件,结构说明
程序入口点

策略配置

代码结构说明

分片配置文件
schemaName: sharding_db
dataSources:
ds_2020:
url: jdbc:mysql://192.168.32.132:33080/demo_2020
username: root
password: 12345678
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_2021:
url: jdbc:mysql://192.168.32.132:33080/demo_2021
username: root
password: 12345678
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
t_order:
actualDataNodes: ds_${2020..2021}.t_order_${1..12}
databaseStrategy:
standard:
shardingColumn: create_time
preciseAlgorithmClassName: org.apache.shardingsphere.shardingproxy.rules.NxhzShardingDataBaseTimeByStringAlgorithm
tableStrategy:
standard:
shardingColumn: create_time
preciseAlgorithmClassName: org.apache.shardingsphere.shardingproxy.rules.NxhzShardingTableTimeByStringAlgorithm
bindingTables:
- t_order
# defaultDatabaseStrategy:
# standard:
# shardingColumn: create_time
# preciseAlgorithmClassName: org.apache.shardingsphere.shardingproxy.NxhzShardingDataBaseTimeAlgorithm
# defaultTableStrategy:
# standard:
# shardingColumn: create_time
# preciseAlgorithmClassName: org.apache.shardingsphere.shardingproxy.NxhzShardingTableTimeAlgorithm
搞定收工,提供代码下载地址
可以联系本人提供有偿服务哦
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)