在开始之前要了解以下这个统计学中背景知识:
贝叶斯学派与频率学派(极大似然估计学派)最大的区别就是,贝叶斯学派认为参数θ不是一个确定值,而是一个随机变量,且随机变量一定是服从某个分布的。
在概率统计中,随机变量(随机数量): 变量中的值是随机现象的结果
似然是个函数!是一个已知量为观测结果未知量为参数的函数,而不是一个概率值。我们已知了观测结果就可以用参数(参数就理解为随机变量服从的某种概率分布的参数)作为未知量列一个表达式写出当前观测结果发生的一个概率。
因为后验概率=先验概率*似然函数,所以我们说得后验概率也是指一个函数并不是一个确定的概率值。
似然用来描述已知随机变量的观测结果时(如随机变量是指抛50次硬币这个事件中,抛硬币获得正面的次数,观测结果是指硬币正面朝上的次数),未知参数的可能取值。似然中就是观测(结果)是已知的,参数是未知的,最大似然估计就是用来估计模型的参数。
所谓最大似然估计就是假设硬币的参数,因为已知实验结果,然后计算实验结果的概率是多少,概率越大的那么这个假设的参数就可能越真。
提到似然就想象用高斯分布模型去理解!可以根据利用最大似然估计求解高斯分布的实例来强化理解上述内容,已知的观测就是高斯分布的x轴坐标,求解的未知参数就是高斯分布的均值和方差,具体参考下面这个链接:
https://zhuanlan.zhihu.com/p/346044291
首先最重要的是要理清算法设计的初衷和大逻辑,即EM算法和变分推断的区别:
1)首先来讲EM算法,EM算法其实就是从非完整数据集中对参数进行 MLE(极大似然估计) 。如下图所示,图中l(θ)为似然函数乘积后取对数得到的。对于没有隐变量的正常情况下,采用极大似然估计法,对下图中的l(θ)求导数并令导数等于0,得到极大值时对应的参数,然后估计出模型参数。可是对于除了含有观测变量还含有隐变量的任务来说,比如:有100个男女身高的样本数据,但是我们不知道具体每个样本来源于男生还是女生,现在需要求男生和女生的身高分别服从什么样的分布;这里样本来源于男生还是女生就是我们的样本中的缺少的观测数据,我们把它叫做隐变量。这种含有隐变量的任务采用上述直接估计参数的方法是不太方便的,因为如果对l(θ)求偏导,会发现非常困难,因为式中包含有隐变量,并且还有和(或积分)的对数,所以很难求解得到未知参数θ。所以我们需要用其它方式去解决参数估计问题。于是我们从求解一个针对已观测变量的似然转而去求解一个针对已观测变量的边际似然 ,笔者认为边际似然这个概念就类似于边缘分布的概念 (其中x就是已观测变量,z是隐变量,x的边际似然就是对应下图红框部分,分号;等价于∣这个符号),所以EM算法便诞生了。因此,EM算法用于求解当变量集合中出现未观测变量时的参数估计问题。
如下面第二张图所示,传统EM算法分为两个步骤,从这张图看出EM和Variational Inference的区别就是,传统EM算法有个先决条件就是q等于pθ(z|x)这个后验分布,说明在EM算法里提前假设了pθ(z|x)这个后验分布是tractable的,而Variational Inference设计的初衷就是为了解决pθ(z|x)是intractable这个问题,这就是两者的区别:
E-step: 即“推断步”,推断隐变量z分布的期望,这一步执行之后,相当于隐变量z在某种程度上成为了一种“已观测”变量;
M-step: 即“估计步”,根据已观测变量x和在E步观测到的z进行参数估计。这里,参数估计采用“极大似然估计”
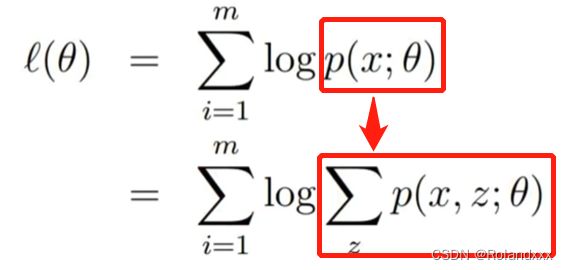
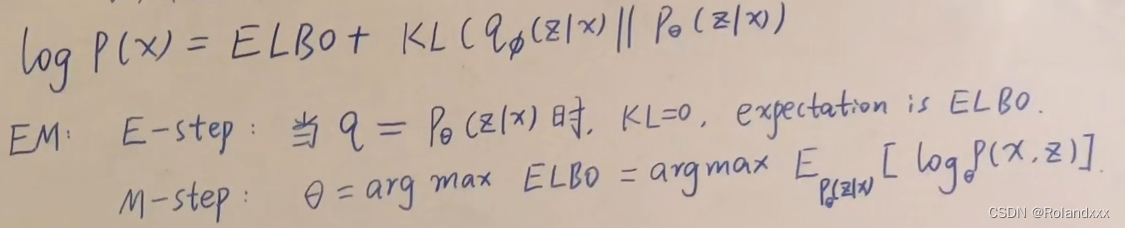
2)变分推断理解:
我们假设x是观测变量(或者叫证据变量、输入变量),z是隐变量(或者说是我们希望推断的label,在监督学习中通常用y表示,但在贝叶斯中,一般会用z表示隐变量),例如在线性回归问题中,x是线性回归模型的输入,z是线性回归模型的预测值;在图像分类问题中,x是图像的像素矩阵,z是图像的类别,即label。
假定我们用 X={x1,x2,…,xm}代表我们输入的观察量,Z={z1,z2,…,zm}代表模型中的隐藏变量,隐变量就是不可观测的变量,是服从未知概率分布,后验概率是一种条件概率,它限定了事件为隐变量取值,而条件为观测结果。一般的条件概率,条件和事件可以是任意的。 推断问题(推断指推断隐变量) 即为依据输入数据的后验条件概率分布 P(Z∣X) 。如下图公式所示,X为已知的观测数据即样本量,Z为模型的隐变量,即Z={z1,z2,…,zm}。下面这个式子称为计算Z的后验概率,其表达的意思是首先给定一个先验分布p(Z),然后在我们观测到数据X的条件下时求Z的分布,最后求出来的这个后验分布 P(Z∣X) 用来更新之前的先验分布p(Z)。但是在计算这个公式中等号右边的分母项时,但隐变量Z通常都是需要高维的,这样才能充分represent样本X,所以如果Z的维度特别高,则计算的是高维度上的积分,数值上计算是非常困难的。并且有些情况是可能不存在解析解的。所以此时就可以尝试用变分推断的方法,寻找容易表达和求解的分布q,当q和p的差距很小的时候,q就可以作为p的近似分布,成为输出结果了。在这个过程中,我们的关键点转变了,从“求分布”的推断问题,变成了“缩小距离”的优化问题。对这一部分的理解还可以结合下文其余小知识点里的后验分布进行理解。
这个变分推断的博客是我看过这么多后觉得讲得最好的一个:https://zhuanlan.zhihu.com/p/507776434
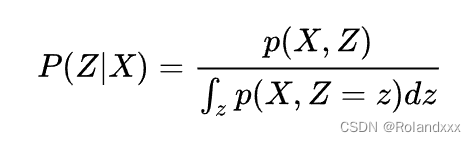
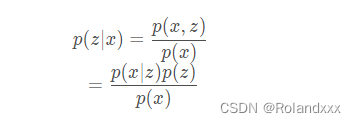
其余小知识点:
1.后验分布: 首先得知道的是得知道D={x1,x2,…,xn}和θ{θ1,θ2,…,θn}都是随机变量!D是关于观测到的数据的随机变量,θ是关于模型参数的随机变量。注意:只要是随机变量就一定服从某个分布,但是这个分布不一定存在对应的密度函数 !!!比如我们假定一个事件x1的发生服从某个分布,那我们就可以让θ1表示这个分布的参数。 把后验分布看作一个函数,它正比于似然函数乘以参数的先验分布,注意的是参数的先验分布也是一个函数。比如有一堆数据{x1,x2,…,xn},我们把这些数据都看成是一个个独立的事件,那么D就是一组事件的集合。其中每个事情服从的分布不一定相同。 举个例子,如投硬币,硬币朝上的概率就可以看作参数。如果硬币不是均匀的,抛硬币这一事件就可能服从多种参数θ={θ1,θ2,…,θn}的0-1分布的其中一种,这些参数θ={θ1,θ2,…,θn}也服从某个分布。θ是关于模型参数的随机变量, 这些参数θ={θ1,θ2,…,θn}也服从某个分布。在VAE中z被称作是隐变量,并不等同于θ,z可以看成在混合高斯模型中可观测变量样本x属于第几个高斯分布,如z=1就是x这个变量是属于第1个高斯分布,而这个选定的高斯分布的参数就是指的θ。P(θ|x)表示的是给定观测数据的基础上,我们对于模型参数的分布产生的新的认知。
具体例子可参见:https://www.zhihu.com/question/24261751/answer/2355943888
2.求谁不积谁(积是指积分),定值不能作为dx。
3.后验概率可以看作等效于似然函数乘以先验,但是似然函数并不是概率密度函数,可从以下两点原因进行区分:
1).似然函数是参数的函数,不是随机变量(指样本)的函数。
2).似然函数的积分并不等于1, 而概率密度的积分为1.
4.概率不等于概率密度,平时说的概率应该是称作概率质量函数(Probability Mass Function, PMF)。具体区别:https://zhuanlan.zhihu.com/p/413360980
5.对于想得到身高数据的概率分布,x是身高,z隐变量就是性别,隐变量和参数θ是两个概念,参数就是均值方差等,可以理解为一个变量对应一组参数。
6.如果一个概率分布在x轴做一个积分或求和的话则结果为1,如下图N就是一个概率分布,概率分布的x轴代表样本(如身高),y轴代表概率密度。
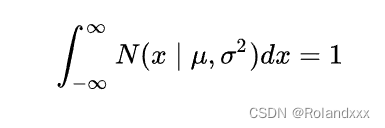
7. 不能乱加隐变量,能加隐变量的条件是:加入隐变量z后得到的marginal distribution仍然要等于原来的P(x),这里的边缘分布即就是利用全概率公式展开得到的:
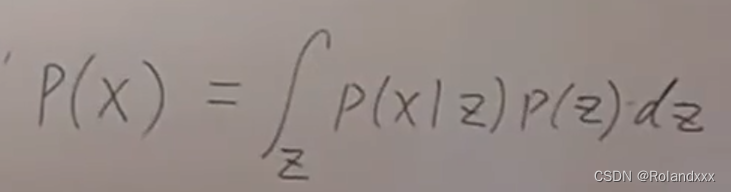
8.连续型随机变量的函数的数学期望(对任何一个数求期望都要首先知道它的分布,如下图f(x)就是它的概率分布),当数量很大时,由大数定律可得,随机变量的期望就等于随机变量的平均值:

9. Jensen不等式,可以看做期望的函数小于等于函数的期望,这说的函数的期望里的函数就是指f(x)。等号成立的条件是当f(x)里的x等于一个常数或者说f(x)恒等于一个常数:

10. 联合分布和边缘分布:

https://zhuanlan.zhihu.com/p/360842262
11.KL散度,范围大于等于0
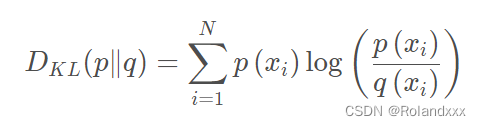
12.贝叶斯基础:条件概率公式(也适用于概率密度函数)是推导的重中之重,然后在证明式子的时候一般以条件概率公式作为桥梁,对左边和右边同时变形来进行证明,逗号是指联合概率,运算顺序是先逗号,再条件概率:

13.这是VAE的loss function,这里log(pθ(x))为什么是const常数呢?因为在这里它和q没有关系,当x固定时,log(pθ(x))就相当于是个常数。

14. 边缘分布
我们经常会遇到求某个随机变量的边缘分布,marginal function就是为了将不同变量对于结果的影响分离出来,起到简化分析的目的。那么在联合分布中,我们怎么能让另一个变量Y失效只研究变量X呢?我们采取的做法是使得Y取到定义域的全部,使其发生的概率达到百分百,那么这个事件究竟发生不发生,就完全取决于我们要研究的X了。
