一、准备
下载地址:: nose.
命令下载:
pip install nose
二、nose介绍
1.更容易编写,查找和运行测试。
2.nose将在当前工作目录下的文件或目录中运行测试,这些文件或目录的名称在单词边界处包括“ test”或“ Test”(例如“ test_this”或“ functional_test”或“ TestClass”,但不包括“ libtest”)。测试输出类似于unittest的输出,但还包括从失败的测试中捕获的stdout输出,以方便进行打印样式的调试。
优势:
三、看个简单的例子了解下
# coding = utf-8
class Testdemo:
def __init__(self):
pass
def setup(self):
print 'start'
def testfunc1(self):
print 'this is func1'
def testfunc2(self):
print 'this is func2'
def testfunc3(self):
print 'this is func3'
def teardown(self):
print 'stop'
nosetests -s

三、nose常用命令简单介绍
常用的几个nosetests命令:
1、查看所有nose相关命令
nosetests -h
2、 执行并捕获输出
nosetests -s
3、 提供XUnit XML 格式的测试结果,并存储在nosetests.xml文件中。主要为jenkins等能理解xnuit格式文件的集成测试环境准备。
nosetests -with-xunit
4、 查看nose的运行信息和调试信息
nosetests -v
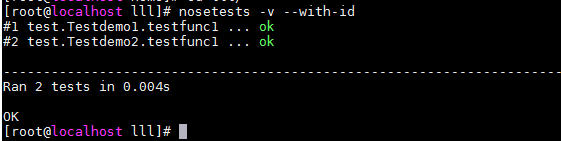
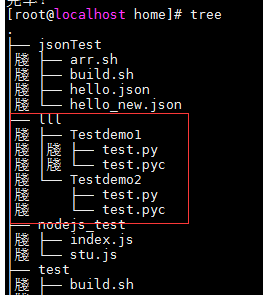
5、 目录 指定一个目录运行测试
nosetests -w XXX

6、只执行上次执行结果中的失败用例
该插件还添加了一种模式,该模式将指导测试运行器记录失败的测试。随后的测试运行将仅运行上次失败的测试。使用–failed开关激活此模式:
nosetests -v --failed
首次使用,执行之后记录下失败用例

再次使用,只执行失败用例

7.出现故障或错误时放入调试器,可用于打断点调试
nosetests -s --pdb
test1.py举例,testfunc1函数中出现a = 0/0 语法错误,执行nosetests -s --pdb,出现调试
# coding = utf-8
class Testdemo:
def __init__(self):
pass
def setup(self):
print 'start'
def testfunc1(self):
a =0/0
print a
print 'this is func1'

ctrl+D中断调试

四、nose命令大全
nosetests XXX 下面是nosetests跟不同的命令有不同的功能
-V, --version
输出nose版本并退出
-p, --plugins
可用插件的输出列表,然后退出。结合较高的详细程度以获取更多细节
-v=DEFAULT, --verbose=DEFAULT
更加冗长。[NOSE_VERBOSE]
--verbosity=VERBOSITY
设置详细程度;–verbosity = 2与-v相同
-q=DEFAULT, --quiet=DEFAULT
减少冗长
-c=FILES, --config=FILES
从配置文件加载配置。可以多次指定;在这种情况下,所有配置文件将被加载并合并
-w=WHERE, --where=WHERE
在此目录中查找测试。可以指定多次。传递的第一个目录将用作工作目录,代替当前的工作目录,这是默认目录。其他的将被添加到要执行的测试列表中。[NOSE_WHERE]
--py3where=PY3WHERE
在Python 3.x下的此目录中查找测试。功能与“ where”相同,但仅在Python 3.x或更高版本下运行时适用。请注意,如果在3.x下存在此选项,则该选项将完全替换所有以“ where”指定的目录,因此“ where”选项无效。[NOSE_PY3WHERE]
-m=REGEX, --match=REGEX, --testmatch=REGEX
与该正则表达式匹配的文件,目录,函数名称和类名称被视为测试。默认值:(?:\ b | _)[Tt] est [NOSE_TESTMATCH]
--tests=NAMES
运行这些测试(以逗号分隔的列表)。此参数主要在配置文件中有用;在命令行上,只需通过测试即可作为其他参数运行而无需切换。
-l=DEFAULT, --debug=DEFAULT
为一个或多个系统激活调试日志记录。可用的调试记录器:鼻子,鼻子。进口商,鼻子。检查器,鼻子。插件,鼻子。结果和鼻子。选择器。用逗号分隔多个名称。
--debug-log=FILE
将调试消息记录到此文件中(默认值:sys.stderr)
--logging-config=FILE, --log-config=FILE
从此文件加载日志配置–绕过所有其他日志配置设置。
-I=REGEX, --ignore-files=REGEX
完全忽略任何与此正则表达式匹配的文件。优先于其他任何设置或插件。指定此选项将替代默认设置。多次指定此选项以添加更多正则表达式[NOSE_IGNORE_FILES]
-e=REGEX, --exclude=REGEX
不要运行与正则表达式匹配的测试[NOSE_EXCLUDE]
-i=REGEX, --include=REGEX
此正则表达式将应用于文件,目录,函数名称和类名称,以便有机会包括与TESTMATCH不匹配的其他测试。多次指定此选项可添加更多正则表达式[NOSE_INCLUDE]
-x, --stop
在第一个错误或失败后停止运行测试
-P, --no-path-adjustment
加载测试时不要对sys.path进行任何更改[NOSE_NOPATH]
--exe
在可执行的python模块中查找测试。正常行为是排除可执行模块,因为它们可能不是导入安全的[NOSE_INCLUDE_EXE]
--noexe
不要在可执行的python模块中寻找测试。(Windows平台上的默认设置是这样做。)
--traverse-namespace
遍历名称空间包的所有路径条目
--first-package-wins, --first-pkg-wins, --1st-pkg-wins
如果鼻子的进口商在不同位置看到相同名称的软件包,通常会将其从sys.modules中逐出。设置此选项可禁用该行为。
--no-byte-compile
在鼻子扫描并运行测试时,防止鼻子将源字节编译为.pyc文件。
-a=ATTR, --attr=ATTR
仅运行具有ATTR [NOSE_ATTR]指定的属性的测试
-A=EXPR, --eval-attr=EXPR
仅运行测试Python表达式EXPR的属性值为True的测试[NOSE_EVAL_ATTR]
-s, --nocapture
不要捕获标准输出(任何标准输出输出将立即打印)[NOSE_NOCAPTURE]
--nologcapture
禁用日志记录捕获插件。日志配置将保持不变。[NOSE_NOLOGCAPTURE]
--logging-format=FORMAT
指定自定义格式以打印语句。使用与标准日志记录处理程序相同的格式。[NOSE_LOGFORMAT]
--logging-datefmt=FORMAT
指定自定义日期/时间格式以打印报表。使用与标准日志记录处理程序相同的格式。[NOSE_LOGDATEFMT]
--logging-filter=FILTER
指定要过滤的语句。默认情况下,所有内容都会被捕获。如果输出太冗长,请使用此选项过滤掉不必要的输出。示例:filter = foo将捕获仅发布给foo或foo.what.ever.sub的语句,而不捕获发给foobar或其他记录器的语句。用逗号指定多个记录器:filter = foo,bar,baz。如果任何记录器名称的前面都带有减号,例如filter = -foo,它将被排除而不是包含在内。默认值:从鼻子本身(-nose)排除日志消息。[NOSE_LOGFILTER]
--logging-clear-handlers
清除所有其他日志记录处理程序
--logging-level=DEFAULT
设置日志级别以捕获
--with-coverage
启用插件覆盖率:使用Ned Batchelder的覆盖率模块激活覆盖率报告。[NOSE_WITH_COVERAGE]
--cover-package=PACKAGE
将覆盖范围输出限制为选定的软件包[NOSE_COVER_PACKAGE]
--cover-erase
运行前清除先前收集的覆盖率统计信息
--cover-tests
在覆盖率报告中包含测试模块[NOSE_COVER_TESTS]
--cover-min-percentage=DEFAULT
测试通过的最低覆盖率[NOSE_COVER_MIN_PERCENTAGE]
--cover-inclusive
在覆盖率报告中的工作目录下包括所有python文件。如果不是所有文件都由测试套件导入,则对于发现测试覆盖范围中的漏洞很有用。[NOSE_COVER_INCLUSIVE]
--cover-html
产生HTML覆盖率信息
--cover-html-dir=DIR
在目录中生成HTML Coverage信息
--cover-branches
将分支机构覆盖范围包括在覆盖率报告中[NOSE_COVER_BRANCHES]
--cover-xml
生成XML覆盖率信息
--cover-xml-file=FILE
在文件中生成XML覆盖率信息
--cover-config-file=DEFAULT
覆盖范围配置文件[NOSE_COVER_CONFIG_FILE]的位置
--cover-no-print
禁止打印承保范围信息
--pdb
出现故障或错误时放入调试器
--pdb-failures
失败时放入调试器
--pdb-errors
出现错误时放入调试器
--no-deprecated
禁用DeprecatedTest异常的特殊处理。
--with-doctest
启用插件doctest:激活doctest插件以在非测试模块中查找并运行doctest。[NOSE_WITH_DOCTEST]
--doctest-tests
还要在测试模块中查找doctest。请注意,类,方法和函数应具有doctest或非doctest测试,不能同时具有两者。[NOSE_DOCTEST_TESTS]
--doctest-extension=EXT
还要在具有此扩展名[NOSE_DOCTEST_EXTENSION]的文件中查找doctest。
--doctest-result-variable=VAR
将变量名设置为默认值“ _”为最后一个解释程序命令的结果。可用于避免与用于文本翻译的_()函数冲突。[NOSE_DOCTEST_RESULT_VAR]
--doctest-fixtures=SUFFIX
在模块中查找doctest文件的固定装置,并将此名称附加到doctest文件的基本名称之后
--doctest-options=OPTIONS
指定要传递给doctest的选项。例如。'+ ELLIPSIS,+ NORMALIZE_WHITESPACE'
--with-isolation
启用插件IsolationPlugin:激活隔离插件,以将对外部模块的更改隔离到单个测试模块或程序包中。在每个测试模块或程序包运行到测试前的状态之后,隔离插件将sys.modules的内容重置。请注意,此插件不应与coverage插件一起使用,或在其他任何情况下重新加载模块可能会产生不良副作用的情况。[NOSE_WITH_ISOLATION]
-d, --detailed-errors, --failure-detail
通过尝试评估失败的断言,将详细信息添加到错误输出中[NOSE_DETAILED_ERRORS]
--with-profile
启用插件配置文件:使用此插件可以使用热点分析器运行测试。[NOSE_WITH_PROFILE]
--profile-sort=SORT
设置分析器输出的排序顺序
--profile-stats-file=FILE
Profiler统计文件;默认是每次运行时都有一个新的临时文件
--profile-restrict=RESTRICT
限制分析器输出。有关详细信息,请参见pstats的帮助。
--no-skip
禁用SkipTest异常的特殊处理。
--with-id
启用插件TestId:激活以将测试ID(如#1)添加到每个测试名称输出中。使用–failed激活,仅重新运行失败的测试。[NOSE_WITH_ID]
--id-file=FILE
将在测试运行中找到的测试ID存储在此文件中。默认值为工作目录中的.noseids文件。
--failed
运行在上次测试运行中失败的测试。
--processes=NUM
在这许多过程中进行传播测试。设置一个等于您计算机中处理器或内核数量的数字即可获得最佳效果。传递负数可将进程数自动设置为核心数。传递0表示禁用并行测试。除非设置了NOSE_PROCESSES,否则默认值为0。[NOSE_PROCESSES]
--process-timeout=SECONDS
设置超时以从每个测试运行器过程返回结果。默认值为10。[NOSE_PROCESS_TIMEOUT]
--process-restartworker
如果设置该选项,将在测试完成后重新启动每个工作进程,这有助于控制内存泄漏以免杀死系统。[NOSE_PROCESS_RESTARTWORKER]
--with-xunit
启用插件Xunit:此插件以标准XUnit XML格式提供测试结果。[NOSE_WITH_XUNIT]
--xunit-file=FILE
用于存储xunit报告的xml文件的路径。默认值为工作目录[NOSE_XUNIT_FILE]中的nasestests.xml。
--xunit-testsuite-name=PACKAGE
xunit xml中的测试套件的名称,由插件生成。默认测试套件名称是鼻子测试。
--xunit-prefix-with-testsuite-name
是否在被测类名的前面加上测试对象名。默认为false。
--all-modules
启用插件AllModules:从所有python模块收集测试。[NOSE_ALL_MODULES]
--collect-only
启用仅收集:仅收集和输出测试名称,请勿运行任何测试。[COLLECT_ONLY]
参考文献:
Testing with nose