CUDA提供了两套API来管理GPU设备和组织线程:
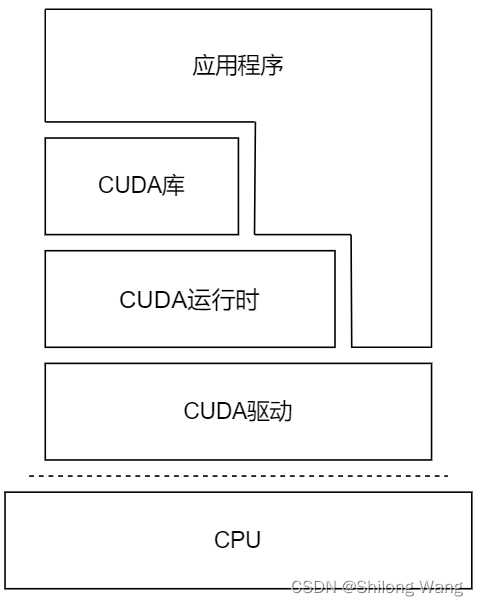
驱动API更加低级,但他提供了对GPU设备的更多控制,运行时API是高级API,它在驱动API的上层实现。驱动API和运行时API没有明显的性能差异,两者的使用是相互排斥的,只能同时使用两者之一。
一个CUDA程序包含了以下两个部分的混合。
- 在CPU上运行的主机代码
- 在GPU上运行的设备代码
NVIDIA 的CUDA nvcc编译器在编译过程中将设备代码从主机代码中分离出来。
主机代码是标准的C代码,使用C编译器进行编译。设备代码,也就是核函数,是用扩展的带有标记数据并行函数关键字的CUDAC语言编写的。设备代码通过nvcc进行编译。在链接阶段,在内核程序调用和显示GPU设备操作中添加CUDA运行时库。
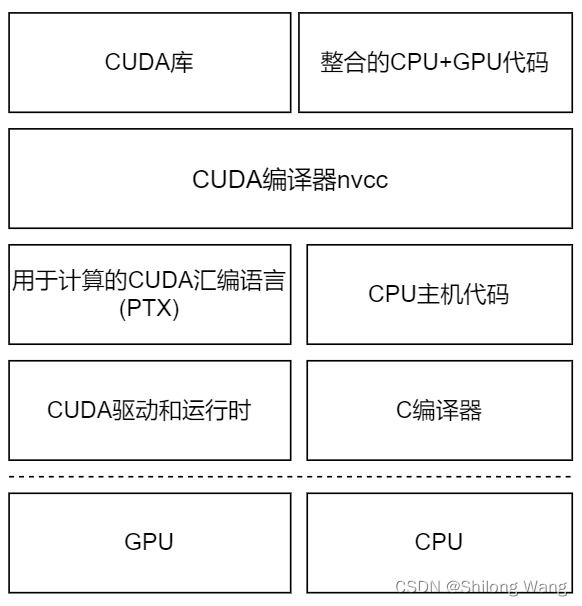
驱动程序API通常为cu**,CUDA Runtime API通常为cuda**
Cuda编程结构
一个典型的CUDA编程结构包括5个主要步骤:
- 分配GPU内存
- 从CPU内存中拷贝数据到GPU内存
- 调用CUDA内核函数来完成程序指定的运算
- 将数据从GPU拷回CPU内存
- 释放GPU内存
编程语句
获取GPU数量
cudaError_t cudaGetDeviceCount(int* count);
获取设备属性
__host__ __device__ cudaError_t cudaGetDevice(int* device );
Returns which device is currently being used.
__host__ cudaError_t cudaGetDeviceProperties(cudaDeviceProp* prop,int device)
cudaGetDeviceProperties(),返回包含设备名称和属性信息的结构体cudaDeviceProp
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, whichDevice);
struct cudaDeviceProp {
char name[256];
cudaUUID_t uuid;
size_t totalGlobalMem;
size_t sharedMemPerBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock;
int maxThreadsDim[3];
int maxGridSize[3];
int clockRate;
size_t totalConstMem;
int major;
int minor;
size_t textureAlignment;
size_t texturePitchAlignment;
int deviceOverlap;
int multiProcessorCount;
int kernelExecTimeoutEnabled;
int integrated;
int canMapHostMemory;
int computeMode;
int maxTexture1D;
int maxTexture1DMipmap;
int maxTexture1DLinear;
int maxTexture2D[2];
int maxTexture2DMipmap[2];
int maxTexture2DLinear[3];
int maxTexture2DGather[2];
int maxTexture3D[3];
int maxTexture3DAlt[3];
int maxTextureCubemap;
int maxTexture1DLayered[2];
int maxTexture2DLayered[3];
int maxTextureCubemapLayered[2];
int maxSurface1D;
int maxSurface2D[2];
int maxSurface3D[3];
int maxSurface1DLayered[2];
int maxSurface2DLayered[3];
int maxSurfaceCubemap;
int maxSurfaceCubemapLayered[2];
size_t surfaceAlignment;
int concurrentKernels;
int ECCEnabled;
int pciBusID;
int pciDeviceID;
int pciDomainID;
int tccDriver;
int asyncEngineCount;
int unifiedAddressing;
int memoryClockRate;
int memoryBusWidth;
int l2CacheSize;
int persistingL2CacheMaxSize;
int maxThreadsPerMultiProcessor;
int streamPrioritiesSupported;
int globalL1CacheSupported;
int localL1CacheSupported;
size_t sharedMemPerMultiprocessor;
int regsPerMultiprocessor;
int managedMemory;
int isMultiGpuBoard;
int multiGpuBoardGroupID;
int singleToDoublePrecisionPerfRatio;
int pageableMemoryAccess;
int concurrentManagedAccess;
int computePreemptionSupported;
int canUseHostPointerForRegisteredMem;
int cooperativeLaunch;
int cooperativeMultiDeviceLaunch;
int pageableMemoryAccessUsesHostPageTables;
int directManagedMemAccessFromHost;
int accessPolicyMaxWindowSize;
}
设置设备参数
设置缓存配置
__host__ cudaError_t cudaDeviceSetCacheConfig( cudaFuncCache cacheConfig);
Parameters
-
cacheConfig:Requested cache configuration
The supported cache configurations are:
-
cudaFuncCachePreferNone: no preference for shared memory or L1 (default)
-
cudaFuncCachePreferShared: prefer larger shared memory and smaller L1 cache
-
cudaFuncCachePreferL1: prefer larger L1 cache and smaller shared memory
-
cudaFuncCachePreferEqual: prefer equal size L1 cache and shared memory
为某些函数专门设置缓存配置
__host__ cudaError_t cudaFuncSetCacheConfig(const void* func,cudaFuncCache cacheConfig)
Parameters
-
func:Device function symbol
-
cacheConfig:Requested cache configuration与cudaDeviceSetCacheConfig相同
释放与GPU相关的所有资源
cudaDeviceRest();
显式释放和清空当前进程中与当前设备有关的所有资源。
主机与设备内存函数
| 标准C函数 |
CUDA C |
| void* malloc(size_t count) |
cudaError_t cudaMalloc(void** Ptr,size_t count) |
| void* memset(void* s,int ch,size_t n) |
cudaError_t cudaMemset(void* devPtr,int ch,size_t n ) |
| void* memcpy(void* dst,const void* src,size_t n); |
cudaError_t cudaMemcpy(void* dst,const void* src,size_t n,cudaMemcpyKind kind) |
| void free(void* ptr) |
cudaError_t cudaFree(void* ptr) |
cudaMemepy 函数负责主机和设备之同的数据传输,此函数从 src 指向的源存储区复制一定数量的字节到 dst 指向的目标存储区。复制方向由 kind 指定,其中的 kind 有以下几种。
- cudaMempyHostToHost
- cudaMempyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
这个函数以同步方式执行,因为在 cudaMemepy 函数返回以及传输操作完成之前主机应用程序是阻塞的。除了内核启动之外的 CUDA 调用都会返回一个错误的校举类型 cudaError_t 。如果 GPU 内存分配成功,丽数返回:cudaSuccess
否则返回: cudaErrorMemoryAllocation
可以使用以下 CUDA 运行时函数将错误代码转化为可读的错误消息:
char* cudaGetErrorString(cudaError_t error)
cudaGetErrorString函数和 C 语言中的 strerror函数类似。
GPU内存层次结构中,最主要的两种内存事全局内存和共享内存。全局类似于CPU的系统内存,而共享内存类似于CPU的缓存。然而GPU的共享内存可以由CUDA C的内核直接控制。
主机与设备都可用的内存函数
__host__ __device__ void * alloca(size_t size);
__host__ __device__ void * malloc(size_t size);
__host__ __device__ void free( void * ptr);
__host__ __device__ void * memcpy( void * dest, const void * src, size_t size);
__host__ __device__ void * memset( void * ptr, int value, size_t size);
时间函数
typedef long clock_t;
clock_t clock();
long long int clock64();
在设备代码中执行时返回每个多核处理器的时钟周期。
CUDA核函数
//定义
__global__ Type kernel_name(argument list)
{
threadIdx.[x y z]//执行当前kernel函数的线程在block中的索引值
blockIdx.[x y z]//执行当前kernel函数的线程所在block在grid中的索引值
blockDim.[x y z]//表示一个block中[x y z]方向包含多少个线程
gridDim.[x y z]//表示一个grid中[x y z]方向包含多少个block
((blockIdx.z*gridDim.x*gridDim.y)+(blockIdx.y*gridDim.y)+blockIdx.x)*blockDim.x*blockDim.y*blockDim.z+(threadIdx.z*blockDim.x*blockDim.y)+threadIdx.y*blockDim.y+ threadIdx.x//线程总索引
}
#or
__device__ Type kernel_name(argument list)
//调用
dim3 grid(g_x,g_y,g_z);//定义网格维度,参数可以是1个、2个或3个
dim3 block(b_x,b_y,b_z);//定义线程块维度
kernel_name<<<grid,block>>>(argument list);
//完整参数格式
kernel_name<<<grid,block,sharedMem,stream>>>(argument list);
- grid是网格维数,即启动线程块的数目结构
- block是块维度,即每个线程块中线程的数目结构
- sharedMem:size_t类型,可缺省,默认为0;用于设置每个block除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为byte。0表示不需要动态分配。
- stream:cudaStream_t类型,可缺省,默认为0。表示该核函数位于哪个流。
核函数的调用和主机线程是异步的。CUDA内核调用完成后,控制权立刻返回给CPU
函数类型限定符
| 限定符 |
执行 |
调用 |
__global__ |
设备端执行 |
可从主机端调用,也可从计算能力大于3的设备中调用 |
__device_ |
设备端执行 |
仅设备端调用 |
__host__ |
主机端执行 |
仅主机端调用 |
__host__和__device__限定符可一起使用,这样函数可以同时再主机和设备端进行编译。
-
__global__函数参数通过constant memory被传递到device,and are limited to 4 KB.
-
__global__ 函数不能使用变长度参数
-
__global__ 函数不能传递引用
-
__global__ 函数不支持递归调用
CUDA核函数的限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
存储限制
内存空间标识符
-
The __device__, __shared__, __managed__ and __constant__ memory space specifiers are not allowed on:
- class, struct, and union data members(类,结构体,共用体成员)
- formal parameters(形参)
- non-extern variable declarations within a function that executes on the host.
-
The __device__,__managed__ and __constant__ memory space specifiers are not allowed on variable declarations that are neither extern nor static within a function that executes on the device.
-
异常处理不能在device code中,也不能在__global__函数中。
-
__constant__变量只能在host code中分配,不能再device code 中分配。
-
__shared__变量不能在声明的同时初始化。
-
__managed__内存空间标识符有以下限制
- managed变量的地址不是一个常量
- managed变量不能是常量类型
- managed变量不能是引用类型
- managed变量不能用于静态存储区的初始化
- managed变量不能用于静态存储区或thread local storage duration的对象的析构函数
- 在Host函数中不允许声明没有外部链接特性的managed变量
- 在Device函数中不允许声明没有外部链接特性或静态链接特性的managed变量
-
内置变量只能在device kernel function中使用,不能被寻址
-
gridDim
This variable is of type dim3 and contains the dimensions of the grid.
-
blockIdx
This variable is of type uint3 and contains the block index within the grid.
-
blockDim
This variable is of type dim3 and contains the dimensions of the block.
-
threadIdx
This variable is of type uint3 and contains the thread index within the block.
-
warpSize
This variable is of type int and contains the warp size in threads
-
指针
- 在host code中对global or shared memory 指针解引用,或在device code中对host memory指针解引用会导致错误(segment fault)
- The address obtained by taking the address of a device, shared or constant variable can only be used in device code. The address of a device or constant variable obtained through
cudaGetSymbolAddress() as described in Device Memory can only be used in host code.
Classes
Data Members
静态数据成员是不支持的,除非是const变量
Function Members
静态成员函数不能是__global__函数