选举介绍
在开始分析选举的原理之前,先了解几个重要的参数
-
服务器 ID(myid)
比如有三台服务器,编号分别是 1,2,3。
编号越大在选择算法中的权重越大。
-
zxid 事务 id-(ZooKeeper transaction ID)
值越大说明数据越新,在选举算法中的权重也越大
-
逻辑时钟(epoch – logicalclock)
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
-
选举状态
LOOKING,竞选状态。
FOLLOWING,随从状态,同步 leader 状态,参与投票。
OBSERVING,观察状态,同步 leader 状态,不参与投票。LEADING,领导者状态。
服务器启动时的 leader 选举
每个节点启动的时候状态都是 LOOKING,处于观望状态,接下来就开始进行选主流程。
若进行 Leader 选举,则至少需要两台机器,一般都是选取 3 台机器组成的服务器集群。
(在下面的例子中,为了表述清晰,我们使用两台进行讲解)
在集群初始化阶段,当有一台服务器 Server1 启动时,其单独无法进行和完成 Leader 选举,当第二台服务器 Server2 启动时,此时两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader选举过程。选举过程如下:
(1) 每个 Server 发出一个投票。由于是初始情况,Server1 和 Server2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 ZXID、epoch,使用(myid, ZXID,epoch)来表示。
此时 Server1 的投票为(1, 0),Server2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK.
PK 规则如下:
i. 优先比较 epochii. 其次检查 ZXID。ZXID 比较大的服务器优先作为 Leader
iii. 如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为Leader 服务器。
对于 Server1 而言,它的投票是(1, 0),接收 Server2 的投票为(2, 0)。
首先会比较两者的 ZXID,均为 0,再比较 myid,此时 Server2 的myid 最大,于是更新自己的投票为(2, 0),然后重新投票。对于Server2 而言,其无须更新自己的投票。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 Server1、Server2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了 Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是 Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。
准备
下载源码:https://codeload.github.com/apache/zookeeper/tar.gz/refs/tags/release-3.7.1
附注:3.7.1发布日期:2022-05-11
编译源码
mvn clean install -DskpTests=true
我这边非常顺利,没报找不到依赖的问题
导入idea
-
正常open即可
-
修改zookeeper-server/pom.xml
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
</dependency>
<dependency>
<groupId>io.dropwizard.metrics</groupId>
<artifactId>metrics-core</artifactId>
</dependency>
<dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
</dependency>
-
在zookeeper/srs/main/resources下增加log4j.properties
zookeeper.root.logger=DEBUG,CONSOLE
zookeeper.console.threshold=DEBUG
log4j.rootLogger=${zookeeper.root.logger}
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
#log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
入口
-
打开zkServer.sh,找到start选项;然后注意一下$ZOOMAIN(启动类)

-
全局搜索ZOOMAIN。找到入口类org.apache.zookeeper.server.quorum.QuorumPeerMain

运行
准备
-
三份zk配置z1.cfg,z2.cfg,z3.cfg;(注意dataDir的路径)
#z1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/Users/twx/code-space/internet/zookeeper-release-3.7.1/quorum/data1
clientPort=2181
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
#z2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/Users/twx/code-space/internet/zookeeper-release-3.7.1/quorum/data2
clientPort=2182
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
#z3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/Users/twx/code-space/internet/zookeeper-release-3.7.1/quorum/data3
clientPort=2183
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
-
创建dataDir目录;并分别echo 1 > data1/myid,echo 2 > data2/myid,echo 3 > data3/myid

开始
打开IDEA/Run Configure;按照下图配置3个实例;
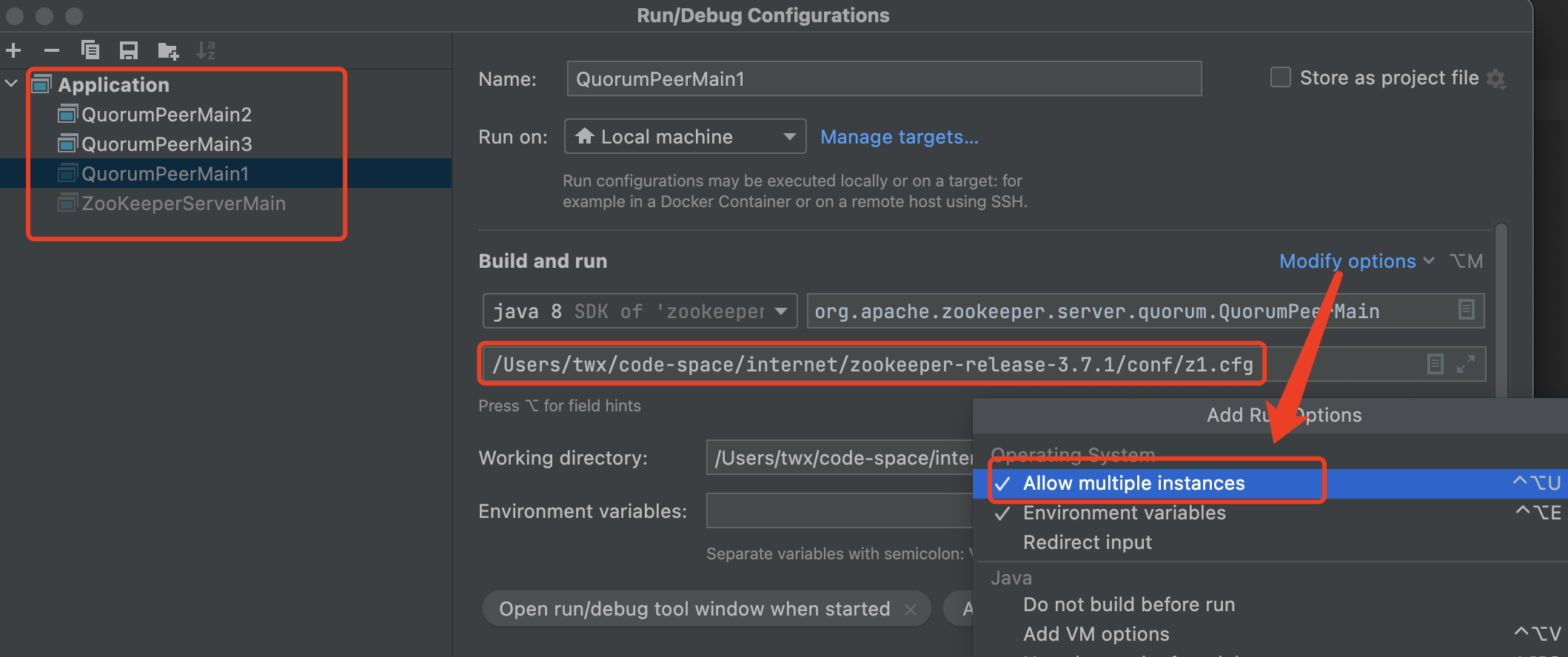
Modify options -> 勾选Allow multiple innstancesProgram args 中填入zookeeper的配置文件地址
解析配置
配置解析我讲着重讲一下parseDynamicConfig()方法,即QuorumVerifier的创建。
其他的大家可以自行跟进下代码。
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
main.initializeAndRun(args);
...
protected void initializeAndRun(String[] args) throws... {
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
...
public void parse(String path) throws ConfigException {
...
initialConfig = new String(Files.readAllBytes(configFile.toPath()));
parseProperties(cfg);
....
public void parseProperties(Properties zkProp) throws ... {
...
for (Entry<Object, Object> entry : zkProp.entrySet()) {
String key = entry.getKey().toString().trim();
String value = entry.getValue().toString().trim();
if (key.equals("dataDir")) {
dataDir = vff.create(value);
}
...
}
...
if (dynamicConfigFileStr == null) {
setupQuorumPeerConfig(zkProp, true);
if (isDistributed() && isReconfigEnabled()) {
backupOldConfig();
}
}
}
void setupQuorumPeerConfig(Properties prop, boolean configBackwardCompatibilityMode) ... {
quorumVerifier = parseDynamicConfig(prop, electionAlg, true, configBackwardCompatibilityMode);
setupMyId();
setupClientPort();
setupPeerType();
checkValidity();
}

public static QuorumVerifier parseDynamicConfig(Properties dynamicConfigProp, int eAlg, boolean warnings, boolean configBackwardCompatibilityMode)...{
boolean isHierarchical = false;
for (Entry<Object, Object> entry : dynamicConfigProp.entrySet()) {
...
}
QuorumVerifier qv = createQuorumVerifier(dynamicConfigProp, isHierarchical);
}
private static QuorumVerifier createQuorumVerifier(Properties dynamicConfigProp, boolean isHierarchical) throws ConfigException {
if (isHierarchical) {
return new QuorumHierarchical(dynamicConfigProp);
} else {
return new QuorumMaj(dynamicConfigProp);
}
}
private Map<Long, QuorumServer> allMembers = new HashMap<Long, QuorumServer>();
private Map<Long, QuorumServer> votingMembers = new HashMap<Long, QuorumServer>();
private Map<Long, QuorumServer> observingMembers = new HashMap<Long, QuorumServer>();
public QuorumMaj(Properties props) throws ConfigException {
for (Entry<Object, Object> entry : props.entrySet()) {
String key = entry.getKey().toString();
String value = entry.getValue().toString();
if (key.startsWith("server.")) {
int dot = key.indexOf('.');
long sid = Long.parseLong(key.substring(dot + 1));
QuorumServer qs = new QuorumServer(sid, value);
allMembers.put(Long.valueOf(sid), qs);
if (qs.type == LearnerType.PARTICIPANT) {
votingMembers.put(Long.valueOf(sid), qs);
} else {
observingMembers.put(Long.valueOf(sid), qs);
}
} else if (key.equals("version")) {
version = Long.parseLong(value, 16);
}
}
half = votingMembers.size() / 2;
}
QuorumMaj类有三个成员变量allMembers、votingMembers、observingMembers,非常重要!QuorumMaj的构造方法遍历配置文件的server.N,将连接信息构造成一个QuorumServer对象,放到allMembers、votingMembers集合中。还有个成员变量half,在构造方法中被赋值votingMembers.size() / 2;half是后续跳过leader选举一个非常关键的点。
启动
刚刚结束了配置文件的解析(config.parse(args[0]);),接下来看看正式的启动流程(runFromConfig(config);)。
protected void initializeAndRun(String[] args)...{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
...
if (args.length == 1 && config.isDistributed()) {
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running in standalone mode");
ZooKeeperServerMain.main(args);
}
}
public void runFromConfig(QuorumPeerConfig config)...{
try {
...
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), false);
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), true);
}
quorumPeer = getQuorumPeer();
quorumPeer.setTxnFactory(new FileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));
...
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
...
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);
if (config.getLastSeenQuorumVerifier() != null) {
quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);
}
quorumPeer.initConfigInZKDatabase();
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setSecureCnxnFactory(secureCnxnFactory);
...
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
...
quorumPeer.start();
ZKAuditProvider.addZKStartStopAuditLog();
quorumPeer.join();
} catch (InterruptedException e) {
LOG.warn("Quorum Peer interrupted", e);
} finally {
try {
metricsProvider.stop();
} catch (Throwable error) {
LOG.warn("Error while stopping metrics", error);
}
}
}
public synchronized void start() {
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
loadDataBase();
startServerCnxnFactory();
...
startLeaderElection();
startJvmPauseMonitor();
super.start();
}
public synchronized void startLeaderElection() {
try {
if (getPeerState() == ServerState.LOOKING) {
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
}
} catch (IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
this.electionAlg = createElectionAlgorithm(electionType);
}
上面代码片段中比较重要的两个方法createElectionAlgorithm(electionType);和start()->super.start();
createElectionAlgorithm(electionType)具体内容稍候再看,这里先简单概括一下它干了些什么事:
- 启动QuorumCnxManager.Listener线程
- 启动FastLeaderElection.Messenger.WorkerReceiver线程
- 启动FastLeaderElection.Messenger.WorkerSender线程
所以createElectionAlgorithm(electionType)只是启动了3个线程而已,所以它会很快返回。
接着就会执行start()->super.start();,即QuorumPeer.run()方法。我们先来看看这个方法:
public void run() {
...
try {
while (running) {
...
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
ServerMetrics.getMetrics().LOOKING_COUNT.add(1);
if (Boolean.getBoolean("readonlymode.enabled")) {
...
} else {
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
...
break;
case FOLLOWING:
...
break;
case LEADING:
..
break;
}
}
} finally {
...
}
}
QuorumPeer.run()真正需要关心的是这一句setCurrentVote(makeLEStrategy().lookForLeader());再跟进一步,其实我们最关心的是FasterLeaderElection.lookForLeader()方法。该方法内部是个while(true)循环,直到leader选举结束!
此时,我们暂且不看lookForLeader方法。
我们先来看看下面这张图。
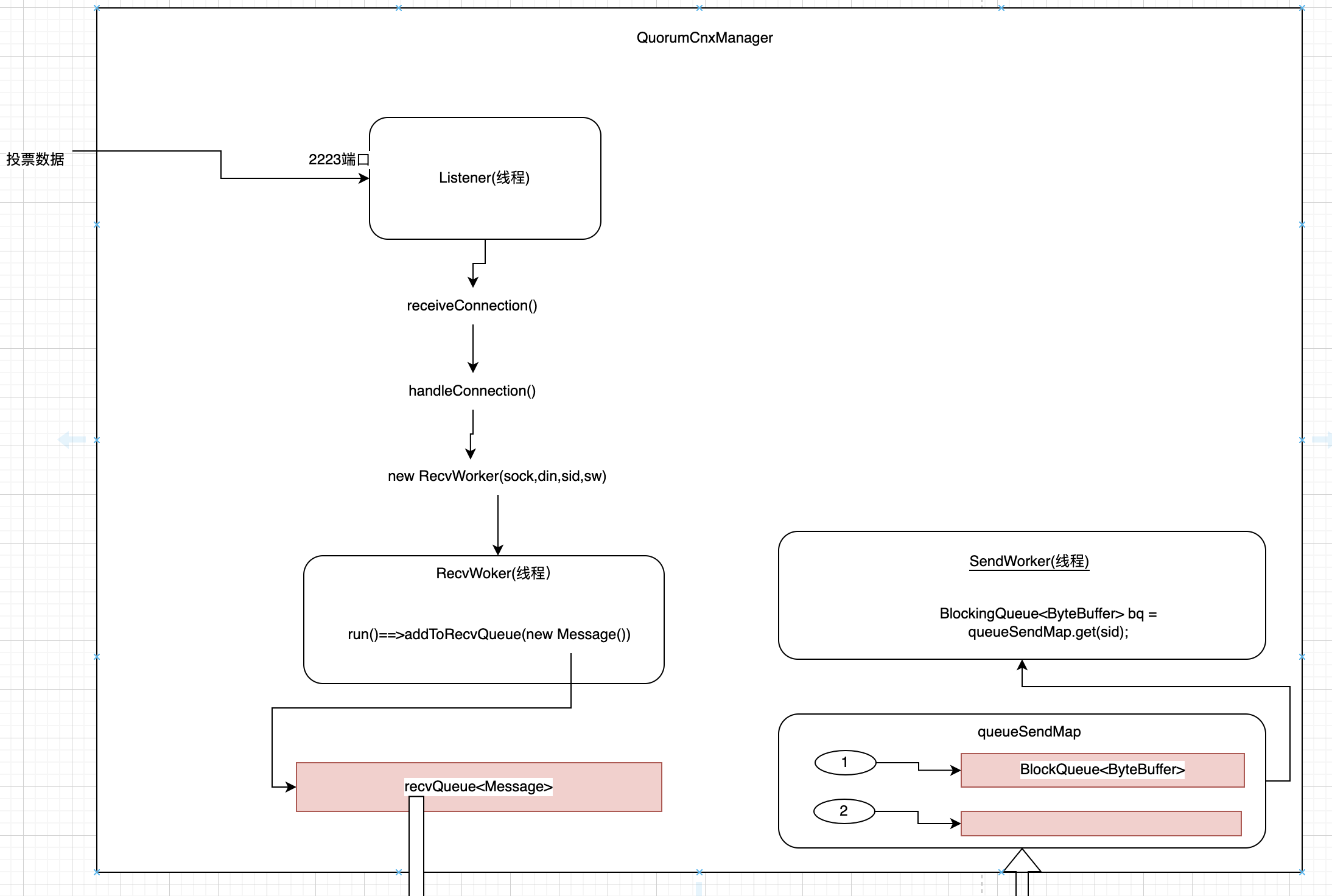
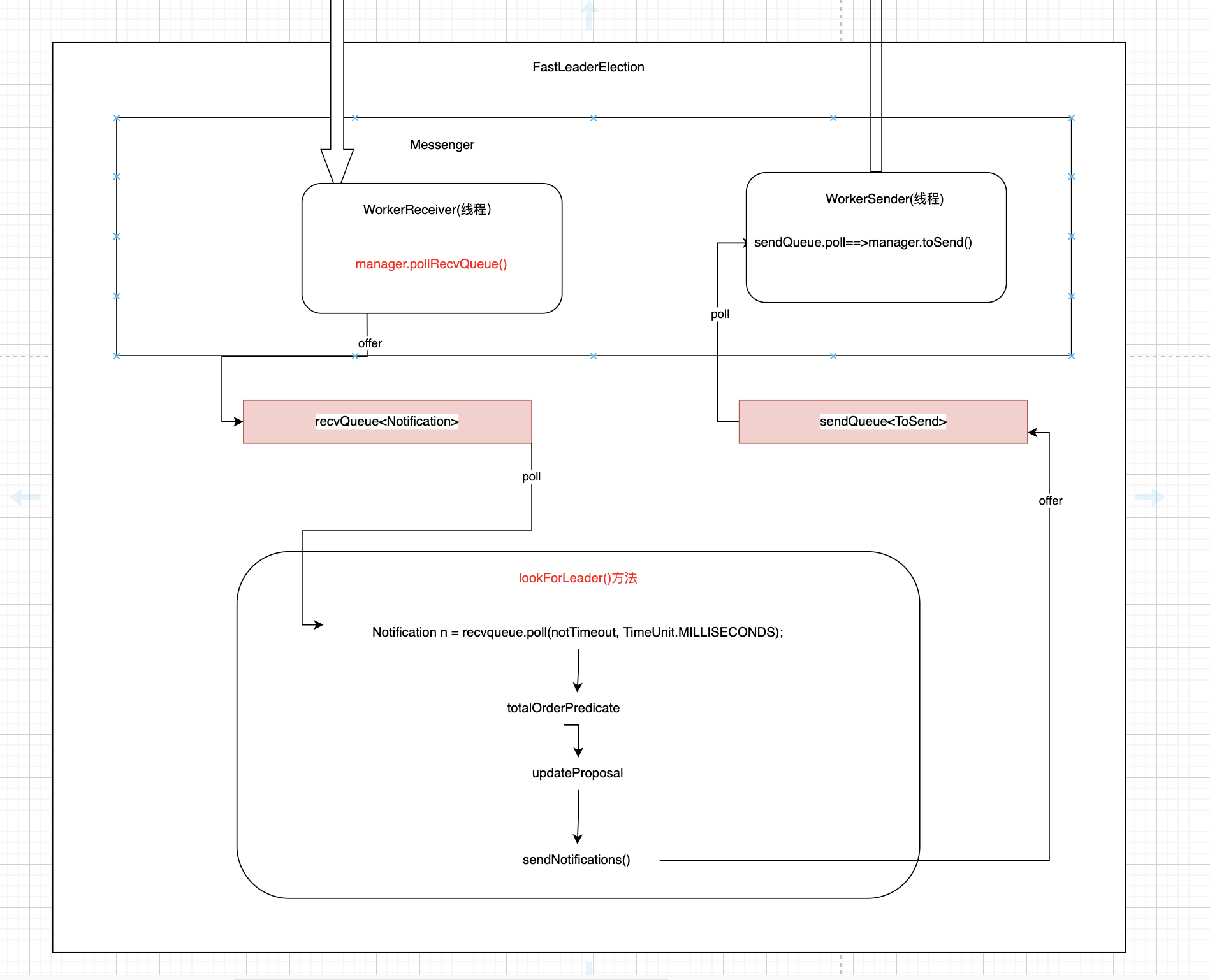
要理解上面这张图,我们把刚刚跳过的createElectionAlgorithm(electionType)方法代码贴一下:
protected Election createElectionAlgorithm(int electionAlgorithm) {
Election le = null;
switch (electionAlgorithm) {
case 1:
throw new UnsupportedOperationException("Election Algorithm 1 is not supported.");
case 2:
throw new UnsupportedOperationException("Election Algorithm 2 is not supported.");
case 3:
QuorumCnxManager qcm = createCnxnManager();
QuorumCnxManager oldQcm = qcmRef.getAndSet(qcm);
if (oldQcm != null) {
LOG.warn("Clobbering already-set QuorumCnxManager (restarting leader election?)");
oldQcm.halt();
}
QuorumCnxManager.Listener listener = qcm.listener;
if (listener != null) {
listener.start();
FastLeaderElection fle = new FastLeaderElection(this, qcm);
fle.start();
le = fle;
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
上面那张图里的QuorumCnxManager是一个非常重要的类。它负责发起网络请求(将投票发送出去或者接受别的节点发送过来的投票)。
QuorumCnxManager有三个内部类Listener(线程)、RecvWoker(线程)、SendWorker(线程)。
Listener(线程)负责创建ServerSocket,用来接收投票信息。具体创建ServerSokcet的过程看代码注释。
当收到网络投票的时候QuorumCnxManager.Listener.ListenerHandler.acceptConnections()的client = serverSocket.accept();就会继续运行下去。最终如图中所示,会将网络投票数据添加到成员变量recvQueue<Message>(阻塞队列)中。
同时FastLeaderElection.start()内部启动了WorkerReceiver线程(见代码注释),在不间断地poll QuorumCnxManager的recvQueue<Message>。拉到消息后,然后把消息封装成Notification放到FastLeaderElection中的recvQueue<Notification>中.
详见如下代码:
public void run() {
Message response;
while (!stop) {
try {
response = manager.pollRecvQueue(3000, TimeUnit.MILLISECONDS);
if (response == null) {
continue;
}
...
Notification n = new Notification();
int rstate = response.buffer.getInt();
long rleader = response.buffer.getLong();
long rzxid = response.buffer.getLong();
long relectionEpoch = response.buffer.getLong();
long rpeerepoch;
int version = 0x0;
QuorumVerifier rqv = null;
...
if (!validVoter(response.sid)) {
...
} else {
LOG.debug("Receive new notification message. My id = {}", self.getId());
QuorumPeer.ServerState ackstate = QuorumPeer.ServerState.LOOKING;
switch (rstate) {
case 0:
ackstate = QuorumPeer.ServerState.LOOKING;
break;
case 1:
ackstate = QuorumPeer.ServerState.FOLLOWING;
break;
case 2:
ackstate = QuorumPeer.ServerState.LEADING;
break;
case 3:
ackstate = QuorumPeer.ServerState.OBSERVING;
break;
default:
continue;
}
n.leader = rleader;
n.zxid = rzxid;
n.electionEpoch = relectionEpoch;
n.state = ackstate;
n.sid = response.sid;
n.peerEpoch = rpeerepoch;
n.version = version;
n.qv = rqv;
...
if (self.getPeerState() == QuorumPeer.ServerState.LOOKING) {
recvqueue.offer(n);
....
if ((ackstate == QuorumPeer.ServerState.LOOKING)
&& (n.electionEpoch < logicalclock.get())) {
...
}
} else {
...
}
}
} catch (InterruptedException e) {
LOG.warn("Interrupted Exception while waiting for new message", e);
}
}
}
lookForLeader
现在我们回过头来看看FasterLeaderElection.lookForLeader()(在贴图之前已经粗略地介绍过了).
下面是lookForLeader()源码:
public Vote lookForLeader() throws InterruptedException {
...
try {
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
...
synchronized (this) {
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
SyncedLearnerTracker voteSet;
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
manager.connectAll();
}
int tmpTimeOut = notTimeout * 2;
notTimeout = Math.min(tmpTimeOut, maxNotificationInterval);
LOG.info("Notification time out: {}", notTimeout);
} else if (validVoter(n.sid) && validVoter(n.leader)) {
switch (n.state) {
case LOOKING:
...
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x{}, logicalclock=0x{}",
Long.toHexString(n.electionEpoch),
Long.toHexString(logicalclock.get()));
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
...
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
if (voteSet.hasAllQuorums()) {
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
...
default:
break;
}
} else {
...
}
}
return null;
} finally {
...
}
}
首先,Map<Long, Vote> recvset = new HashMap<Long, Vote>();是非常重要的,它会将网络(z2、z3节点)上发送过来的投票数据保存下来(包括它自己)。
synchronized (this) {
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
上面这段代码是zk刚启动的时候发送的第一轮投票;
将投票轮次logicalclock设置为1。
初始的Vote是(1,0,0) --(proposedLeader,proposedZxid,proposedEpoch).
通过sendNotifications();将初始投票发送出去。发送流程大家可以参照我上面提供的那张图,去跟一下代码。
需要注意的点是sendNotifications()也会将投票数据发送给自身。参考QuorumCnxManager.toSend()方法。
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
if (n == null) {
if (manager.haveDelivered()) {
sendNotifications();
} else {
manager.connectAll();
}
int tmpTimeOut = notTimeout * 2;
notTimeout = Math.min(tmpTimeOut, maxNotificationInterval);
LOG.info("Notification time out: {}", notTimeout);
}
recvqueue.poll()前面已经介绍过recvqueue的数据是通过FastLeaderElection内部的WorkerReceiver线程offer的。刚刚我们通过sendNotifications()将第一轮投票发送出去。这时候recvqueue应该就有3份Vote数据(z1 z2 z3 包括自身,上面解释过了)。
什么情况下n==null? 如果z2 z3没有启动,那么再第二轮poll的时候就会拉不到数据。
看上面代码注释,如果queueSendMap所有的队列为空,说明z2 z3没连接上,重新发起连接。
这段代码对主流程没影响,我们暂且不细究。
else if (validVoter(n.sid) && validVoter(n.leader)) {
switch (n.state) {
case LOOKING:
...
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x{}, logicalclock=0x{}",
Long.toHexString(n.electionEpoch),
Long.toHexString(logicalclock.get()));
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
validVoter(n.sid) && validVoter(n.leader)用于校验收到的网络投票是否来自配置文件中的server列表中的服务器。如果不是,就不用处理了。
由于z1 z2 z3 都刚刚启动,所有n.state肯定都是LOOKING状态。
if (n.electionEpoch > logicalclock.get()):收到的选举朝代(也可以理解为轮回)比本身的逻辑时钟要大,说明本身的投票轮回落后了。更新一下投票,然后再发送出去。(更新待会再说)
else if (n.electionEpoch < logicalclock.get()):收到的选举朝代(也可以理解为轮回)比本身的逻辑时钟要小,说明从网络上收到的投票消息过期了,自然就不用处理
else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch))来到这里,说明收到的选举朝代和当前的选举朝代(等同于逻辑时钟)是一致的,两者是同一轮投票。
好,现在要插播一下totalOrderPredicate()源码,它是一个比较重要的方法,定义了投票比较规则,我们在看文章、书籍时经常会被介绍到的那段规则:
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
if (self.getQuorumVerifier().getWeight(newId) == 0) {
return false;
}
return ((newEpoch > curEpoch)
|| ((newEpoch == curEpoch)
&& ((newZxid > curZxid)
|| ((newZxid == curZxid)
&& (newId > curId)))));
}
比较顺序,总结一下:
- 优先比较epoch(朝代)
- 然后比较zxid(事务id)
- 最后比较serverId(即myid里的那个值)
totalOrderPredicate()返回true表明网络投票战胜了自身的票据。后续将把自身的票据替换为网络票据,然后重新发送出去。(待会再讲)。如果返回false,保留自身票据。(不用再发送出去了)
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
recvset将收到的网络投票记录下来。后续会用到。
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
getVoteTracker()返回的是一个SyncedLearnerTracker对象。我们先看下SyncedLearnerTracker的结构图:

SyncedLearnerTracker有个内部类QuorumVerifierAcksetPair,内部类又有两个属性QuorumVerifier qv和HashSet<Long> ackset。
QuorumVerifier qv我们之前在解析配置文件的时候介绍过,有三个成员变量allMembers、votingMembers、observingMembers存储了各个节点的连接信息。另外还有一个half变量,默认是votingMembers数量的一半。
HashSet<Long> ackset 存储的是Long类型的数据,实际上最终存储的就是serverId(myid里的那个值)。
现在我们来看一下getVoteTracker()源码:
protected SyncedLearnerTracker getVoteTracker(Map<Long, Vote> votes, Vote vote) {
SyncedLearnerTracker voteSet = new SyncedLearnerTracker();
voteSet.addQuorumVerifier(self.getQuorumVerifier());
LOG.info(">>>getVoteTracker: {}",votes.entrySet());
for (Map.Entry<Long, Vote> entry : votes.entrySet()) {
if (vote.equals(entry.getValue())) {
LOG.info(">>>entryKey: {}, currentVote: {}", entry.getKey(), vote);
voteSet.addAck(entry.getKey());
}
}
LOG.info(">>>getVoteTracker end<<<<<<");
return voteSet;
}
public boolean addAck(Long sid) {
boolean change = false;
for (QuorumVerifierAcksetPair qvAckset : qvAcksetPairs) {
if (qvAckset.getQuorumVerifier().getVotingMembers().containsKey(sid)) {
qvAckset.getAckset().add(sid);
LOG.info(">>>qvAckSet: {}",qvAckset.getAckset());
change = true;
}
}
return change;
}
上面代码和SyncedLearnerTracker有关的是这几行:
SyncedLearnerTracker voteSet = new SyncedLearnerTracker();voteSet.addQuorumVerifier(self.getQuorumVerifier());voteSet.addAck(entry.getKey());
第一行不用解释。
第二行实际上是将self.getQuorumVerifier()赋值给了QuorumVerifierAcksetPair的成员变量qv
第三行解释起来比较麻烦。所以我加了几行log日志。先运行z1节点,然后运行z2节点。通过观察日志给大家讲解。
下面是运行日志:
#这是z1日志
//由于z1节点先启动,第一轮投票recvset只有[1=(1, 0, 0)]
>>>getVoteTracker: [1=(1, 0, 0)]
//当前票据是自身(1,0,0)
>>>entryKey: 1, currentVote: (1, 0, 0)
>>>qvAckSet: [1]
>>>getVoteTracker end<<<<<<
//这时候z2节点启动了
//z1收到了来自z2节点的票据:2=(2, 0, 0),所以recvset是[1=(1, 0, 0), 2=(2, 0, 0)]
//z1将当前票据更新成了(2, 0, 0) 【在方法updateProposal中】,
//同时将票据1->(2,0,0)发送出去(我z1第二轮投票给(2,0,0))
>>>getVoteTracker: [1=(1, 0, 0), 2=(2, 0, 0)]
>>>entryKey: 2, currentVote: (2, 0, 0)
>>>qvAckSet: [2]
>>>getVoteTracker end<<<<<<
//第三轮投票
//收到了自己发送的票据1->(2,0,0)
//所以recvset是[1=(2, 0, 0), 2=(2, 0, 0)] (recvset是个map,key相同覆盖了)
//本来不会进入updateProposal()方法,当前的票据还是(2, 0, 0)
>>>getVoteTracker: [1=(2, 0, 0), 2=(2, 0, 0)]
//拿当前的票据(2, 0, 0)与recvset一一比对,发现节点1,2的value与(2,0,0)都相等
//所以qvAckSet等于[1, 2]
>>>entryKey: 1, currentVote: (2, 0, 0)
>>>qvAckSet: [1]
>>>entryKey: 2, currentVote: (2, 0, 0)
>>>qvAckSet: [1, 2]
>>>getVoteTracker end<<<<<<
#这是节点z2的日志
//节点2刚启动,接收到自己发出的票据
>>>getVoteTracker: [2=(2, 0, 0)]
>>>entryKey: 2, currentVote: (2, 0, 0)
>>>qvAckSet: [2]
>>>getVoteTracker end<<<<<<
//节点2启动后,收到了节点1第一轮的投票,所以此时recvset=[1=(1, 0, 0), 2=(2, 0, 0)]
//此轮不会更新投票(节点2也不会发出投票)
>>>getVoteTracker: [1=(1, 0, 0), 2=(2, 0, 0)]
>>>entryKey: 2, currentVote: (2, 0, 0)
>>>qvAckSet: [2]
>>>getVoteTracker end<<<<<<
//收到节点1第二轮的投票1=(2, 0, 0)
//所以recvset=[1=(2, 0, 0), 2=(2, 0, 0)]
>>>getVoteTracker: [1=(2, 0, 0), 2=(2, 0, 0)]
>>>entryKey: 1, currentVote: (2, 0, 0)
>>>qvAckSet: [1]
>>>entryKey: 2, currentVote: (2, 0, 0)
>>>qvAckSet: [1, 2]
>>>getVoteTracker end<<<<<<
仔细分析一下日志执行结果,应该就能理解getVoteTracker()方法了。
voteSet = getVoteTracker(...)返回后,紧接着我们来看hasAllQuorums()这个方法,非常重要。是跳出外层while循环(即结束leading选举)的关键。
if (voteSet.hasAllQuorums()) {
...
}
break;
public boolean hasAllQuorums() {
for (QuorumVerifierAcksetPair qvAckset : qvAcksetPairs) {
if (!qvAckset.getQuorumVerifier().containsQuorum(qvAckset.getAckset())) {
return false;
}
}
return true;
}
hasAllQuorums()方法里最核心的一句是:
!qvAckset.getQuorumVerifier().containsQuorum(qvAckset.getAckset()),点进containsQuorum里看看,其实是判断qvAckset.getAckset()的大小是否超过集群数量的一半。
qvAckset.getAckset在上面的getVoteTracker()已经介绍过了。它存储的是那些对当前Vote()认同的serverId。所以只需简单的判断一下这个set集合的数量是否过半,即可以决定是否退出leading选举。
if (voteSet.hasAllQuorums()) {
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
虽然voteSet.hasAllQuorums()已过半,但是进入后还是得尝试拉一下recvqueue有没有数据(可能由于网络原因z3节点的投票数据这时候才到达)。如果recvqueue真的没有任务投票数据了,就可以确认节点状态,退出leader选举了。
在setPeerState(proposedLeader, voteSet);方法中更新当前节点的状态。然后就可以退出while循环了。
退出while循环,程序会回到QuorumPeer的setCurrentVote(makeLEStrategy().lookForLeader());继续执行。
在QuorumPeer的run()方法中进行下一轮while,根据state状态进行相应的初始化。
至此,lead选举的主流程介绍完毕!
欢迎访问个人博客: https://tangwx.site/archives/zookeeperleader%E9%80%89%E4%B8%BE%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90md
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)