背景
我创建spark的maven工程的时候,在java目录同级还创建了一个scala目录。这就得考虑编译相关的事了。
解决
1、创建source folder
如下图所示,直接创建就好了
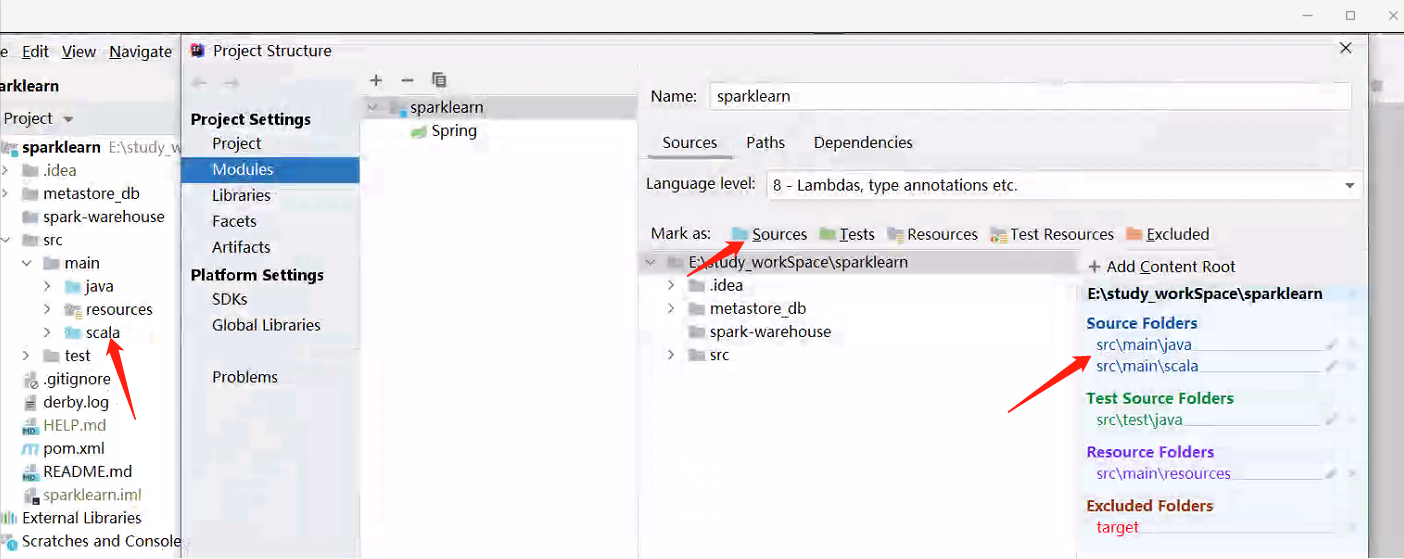
2、编译带来的问题
编译的时候发现一个问题,就是在scala目录中的scala文件可以编译的上,而java文件编译不上,而java目录下的java文件是可以的,
经过查阅问题,发现默认的maven compile是不可以编译多个source folder的,需要添加plugin,如下,问题解决
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<executions>
<execution>
<id>add-source</id>
<phase>initialize</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>${project.basedir}/src/main/scala</source>
<source>${project.basedir}/src/main/java</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>