量化选股策略搭建(四)(短期策略搭建)
首先我们需要把选股这个问题转化为一个机器学习问题。那么如何转化成机器学习问题呢?机器学习也分两类问题:1、回归问题,2、分类问题。常规的一些方法是预测股价增长来进行选股(回顾问题),这里我们将其转化为一个分类问题。我们考虑短期策略搭建,即持股周期不能多于5天。如果一支股票在未来5天里最高增长大于5%,最大损失大于-3%,我们将其标签标记为1,其他标签标记为0。
解决一个机器学习通常有以下步骤:1、特征工程(提取有效特征),2、模型选择(选择SVM、树模型等传统模型),3、线下验证。以下我们将用代码实现我们的选股方案。
首先是一些变量定义。
# 模型训练
import numpy as np
import pandas as pd
import os
import tqdm
base_path = 'stock'
market_map = {'主板':0, '中小板':1}
exchange_map = {'SZSE':0, 'SSE':1}
is_hs_map = {'S':0, 'N':1, 'H':2}
area_map = {'深圳': 0, '北京': 1, '吉林': 2, '江苏': 3, '辽宁': 4, '广东': 5, '安徽': 6, '四川': 7, '浙江': 8,
'湖南': 9, '河北': 10, '新疆': 11, '山东': 12, '河南': 13, '山西': 14, '江西': 15, '青海': 16,
'湖北': 17, '内蒙': 18, '海南': 19, '重庆': 20, '陕西': 21, '福建': 22, '广西': 23, '天津': 24,
'云南': 25, '贵州': 26, '甘肃': 27, '宁夏': 28, '黑龙江': 29, '上海': 30, '西藏': 31}
industry_map = {'银行': 0, '全国地产': 1, '生物制药': 2, '环境保护': 3, '区域地产': 4, '酒店餐饮': 5, '运输设备': 6,
'综合类': 7, '建筑工程': 8, '玻璃': 9, '家用电器': 10, '文教休闲': 11, '其他商业': 12, '元器件': 13,
'IT设备': 14, '其他建材': 15, '汽车服务': 16, '火力发电': 17, '医药商业': 18, '汽车配件': 19, '广告包装': 20,
'轻工机械': 21, '新型电力': 22, '饲料': 23, '电气设备': 24, '房产服务': 25, '石油加工': 26, '铅锌': 27, '农业综合': 28,
'批发业': 29, '通信设备': 30, '旅游景点': 31, '港口': 32, '机场': 33, '石油贸易': 34, '空运': 35, '医疗保健': 36,
'商贸代理': 37, '化学制药': 38, '影视音像': 39, '工程机械': 40, '软件服务': 41, '证券': 42, '化纤': 43, '水泥': 44,
'专用机械': 45, '供气供热': 46, '农药化肥': 47, '机床制造': 48, '多元金融': 49, '百货': 50, '中成药': 51, '路桥': 52,
'造纸': 53, '食品': 54, '黄金': 55, '化工原料': 56, '矿物制品': 57, '水运': 58, '日用化工': 59, '机械基件': 60,
'汽车整车': 61, '煤炭开采': 62, '铁路': 63, '染料涂料': 64, '白酒': 65, '林业': 66, '水务': 67, '水力发电': 68,
'互联网': 69, '旅游服务': 70, '纺织': 71, '铝': 72, '保险': 73, '园区开发': 74, '小金属': 75, '铜': 76, '普钢': 77,
'航空': 78, '特种钢': 79, '种植业': 80, '出版业': 81, '焦炭加工': 82, '啤酒': 83, '公路': 84, '超市连锁': 85,
'钢加工': 86, '渔业': 87, '农用机械': 88, '软饮料': 89, '化工机械': 90, '塑料': 91, '红黄酒': 92, '橡胶': 93, '家居用品': 94,
'摩托车': 95, '电器仪表': 96, '服饰': 97, '仓储物流': 98, '纺织机械': 99, '电器连锁': 100, '装修装饰': 101, '半导体': 102,
'电信运营': 103, '石油开采': 104, '乳制品': 105, '商品城': 106, '公共交通': 107, '船舶': 108, '陶瓷': 109}
数据读取
首先是上市公司数据读取,这里在对是否是ST公司判断中有点小bug,目前是ST的公司不代表之前是ST,目前是ST的也不代表之前不是ST。
def JudgeST(x):
if 'ST' in x:
return 1
else:
return 0
col = ['open', 'high', 'low', 'pre_close',]
company_info = pd.read_csv(os.path.join(base_path, 'company_info.csv'), encoding='ANSI')
company_info['is_ST'] = company_info['name'].apply(JudgeST)
# 丢弃一些多余的信息
company_info.drop(['index', 'symbol', 'fullname'], axis=1, inplace=True)
company_info.dropna(inplace=True)
company_info['market'] = company_info['market'].map(market_map)
company_info['exchange'] = company_info['exchange'].map(exchange_map)
company_info['is_hs'] = company_info['is_hs'].map(is_hs_map)
读取一些指数信息
# 读取指数信息
stock_index_info = pd.DataFrame()
index = ['000001.SH', '000016.SH', '000002.SH', '399001.SZ', '399007.SZ', '399008.SZ', '399101.SZ',
'399102.SZ']
for ts_code in index:
tmp_df = pd.read_csv(os.path.join(base_path, 'OldData', ts_code + '_NormalData.csv'))
# 特征工程
# tmp_df = FeatureEngineering(tmp_df)
stock_index_info = pd.concat((stock_index_info, tmp_df))
# transaction_day = len(tmp_df)
tmp_list = list(tmp_df['trade_date'].sort_values())
date_map = dict(zip(tmp_list, range(len(tmp_list))))
读取股票交易信息,这里我们去掉一下上市不久的企业
# 读取股票交易信息
stock_info = pd.DataFrame()
remove_stock = []
tmp_list = []
for ts_code in tqdm.tqdm(company_info['ts_code']):
tmp_df = pd.read_csv(os.path.join(base_path, 'OldData', ts_code + '_NormalData.csv'))
# 还需要去除一些停牌时间很久的企业,后期加
if len(tmp_df) < 100: # 去除一些上市不久的企业
remove_stock.append(ts_code)
continue
tmp_df = tmp_df.sort_values('trade_date', ascending=True).reset_index()
# 提取均线信息
# for tmp_col in col:
# for rolling_day in [5, 10, 13, 21, 30]:
# tmp_df = GetMA(tmp_df, tmp_col, rolling_day)
# 特征工程
# tmp_df = FeatureEngineering(tmp_df)
tmp_list.append(tmp_df)
stock_info = pd.concat(tmp_list)
stock_info = pd.concat(tmp_list)
ts_code_map = dict(zip(stock_info['ts_code'].unique(), range(stock_info['ts_code'].nunique())))
stock_info = stock_info.reset_index()
stock_info['ts_code_id'] = stock_info['ts_code'].map(ts_code_map)
stock_info.drop('index', axis=1, inplace=True)
stock_info['trade_date_id'] = stock_info['trade_date'].map(date_map)
stock_info['ts_date_id'] = (10000 + stock_info['ts_code_id']) * 10000 + stock_info['trade_date_id']
stock_info = stock_info.merge(company_info, how='left', on='ts_code')
stock_info_copy = stock_info.copy()
特征工程
接下来是一些简单的特征工程,目前还没来得及做特征工程,后期做好会再更新。首先是把收盘价、开盘价、最低价、最高价变换一个尺度(相当于盈亏比),若不转换直接放进去模型是很难学会的。转换成盈亏比的话(相当于所有股票转化成同一个尺度了),模型更容易学会。
stock_info = stock_info_copy.copy()
col = ['close', 'open', 'high', 'low']
feature_col = []
for tmp_col in col:
stock_info[tmp_col+'_'+'transform'] = (stock_info[tmp_col] - stock_info['pre_close']) / stock_info['pre_close']
feature_col.append(tmp_col+'_'+'transform')
提取前5天收盘价与今天收盘价的盈亏比。
for i in range(5):
tmp_df = stock_info[['ts_date_id', 'close']]
tmp_df = tmp_df.rename(columns={'close':'close_shift_{}'.format(i+1)})
feature_col.append('close_shift_{}'.format(i+1))
tmp_df['ts_date_id'] = tmp_df['ts_date_id'] + i + 1
stock_info = stock_info.merge(tmp_df, how='left', on='ts_date_id')
stock_info.drop('level_0', axis=1, inplace=True)
# stock_info.dropna(inplace=True)
for i in range(5):
stock_info['close_shift_{}'.format(i+1)] = (stock_info['close'] - stock_info['close_shift_{}'.format(i+1)]) / stock_info['close_shift_{}'.format(i+1)]
标签制作:
在标签制作时,如果一支股票在未来5天里最高增长大于5%,最大损失大于-3%,我们将其标签标记为1,其他标签标记为0。在制作标签时为了防止股价拉到5%瞬间掉下来,我们加了一点容错(6%)。这里做标签其实有点bug,这里没有考虑股票先涨到5%,再跌到-3%。因为我们的止盈点是5%,如果先涨到5%我们卖了就不需要考虑后面的情况了。(这个后面再改)
# make_label
# stock_info = stock_info_copy.copy()
use_col = []
for i in range(5):
tmp_df = stock_info[['ts_date_id', 'high', 'low']]
tmp_df = tmp_df.rename(columns={'high':'high_shift_{}'.format(i+1), 'low':'low_shift_{}'.format(i+1)})
use_col.append('high_shift_{}'.format(i+1))
use_col.append('low_shift_{}'.format(i+1))
tmp_df['ts_date_id'] = tmp_df['ts_date_id'] - i - 1
stock_info = stock_info.merge(tmp_df, how='left', on='ts_date_id')
stock_info.dropna(inplace=True)
for i in range(5):
stock_info['high_shift_{}'.format(i+1)] = (stock_info['high_shift_{}'.format(i+1)] - stock_info['close']) / stock_info['close']
stock_info['low_shift_{}'.format(i+1)] = (stock_info['low_shift_{}'.format(i+1)] - stock_info['close']) / stock_info['close']
tmp_array = stock_info[use_col].values
max_increse = np.max(tmp_array, axis=1)
min_increse = np.min(tmp_array, axis=1)
stock_info['label_max'] = max_increse
stock_info['label_min'] = min_increse
stock_info['label_final'] = (stock_info['label_max'] > 0.06) & (stock_info['label_min'] > -0.03)
stock_info['label_final'] = stock_info['label_final'].apply(lambda x: int(x))
stock_info = stock_info.reset_index()
stock_info.drop('index', axis=1, inplace=True)
模型训练:
模型数据输入准备:这里我们选取了18年1月1日至19年4月5日的数据作为训练集,19年4月6号至19年4月10号的数据作为验证集,19年4月17日至19年12月18日的数据作为回测数据(这是一段黑暗的行情,看看我们的模型在黑暗的行情下有什么表现)。
trn_col = ['open', 'high', 'low', 'close', 'pre_close', 'change', 'pct_chg', 'vol', 'amount', 'ts_code_id'] + feature_col
label = 'label_final'
trn_date_min = 20180101
trn_date_max = 20190405
val_date_min = 20190406
val_date_max = 20190410
test_date_min = 20190417
test_date_max = 20191218
trn_data_idx = (stock_info['trade_date'] >= trn_date_min) & (stock_info['trade_date'] <= trn_date_max)
val_data_idx = (stock_info['trade_date'] >= val_date_min) & (stock_info['trade_date'] <= val_date_max)
test_data_idx = (stock_info['trade_date'] >= test_date_min) & (stock_info['trade_date'] <= test_date_max)
trn = stock_info[trn_data_idx][trn_col].values
trn_label = stock_info[trn_data_idx][label].values
val = stock_info[val_data_idx][trn_col].values
val_label = stock_info[val_data_idx][label].values
test = stock_info[test_data_idx][trn_col].values
test_label = stock_info[test_data_idx][label].values
print('rate of 0: %.4f, rate of 1: %.4f' % (np.sum(trn_label==0)/len(trn_label), np.sum(trn_label==1)/len(trn_label)))
print('trn data:%d, val data:%d, test data:%d' % (len(trn), len(val), len(test)))
print('number of features:%d' % len(trn_col))

可以发现样本中正负样本比为1:4,使用了19个特征。
模型训练时我们使用了LGB,还没有尝试其他模型,但是应该LGB就够了。
# 模型训练及评价
import lightgbm as lgb
from sklearn import metrics
param = {'num_leaves': 31,
# 'n_estimatores': 3000,
'min_data_in_leaf': 20,
'objective': 'binary',
# 'max_depth': 5,
'learning_rate': 0.01,
"min_child_samples": 20,
"boosting": "gbdt",
# "feature_fraction": 0.45,
"bagging_freq": 1,
# "bagging_fraction": 0.8,
"bagging_seed": 11,
"verbosity": -1}
trn_data = lgb.Dataset(trn, trn_label)
val_data = lgb.Dataset(val, val_label)
num_round = 2000
clf = lgb.train(param, trn_data, num_round, valid_sets=[trn_data, val_data], verbose_eval=300,
early_stopping_rounds=100)
oof_lgb = clf.predict(val, num_iteration=clf.best_iteration)
test_lgb = clf.predict(test, num_iteration=clf.best_iteration)

模型评价:
oof_lgb_final = np.round(oof_lgb)
print(metrics.accuracy_score(val_label, oof_lgb_final))
print(metrics.confusion_matrix(val_label, oof_lgb_final))
tp = np.sum(((oof_lgb_final == 1) & (val_label == 1)))
pp = np.sum(oof_lgb_final == 1)
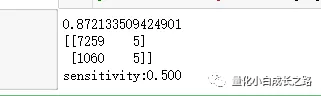
print('sensitivity:%.3f'% (tp/(pp)))
在验证集中,模型敏感度为0.5,意思就是选了10个股票,5支股票在未来5天涨幅能达到5%。
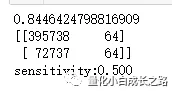
在测试集中,我们调了阈值,模型敏感度同样为0.5。
thresh_hold = 0.6
oof_test_final = test_lgb >= thresh_hold
print(metrics.accuracy_score(test_label, oof_test_final))
print(metrics.confusion_matrix(test_label, oof_test_final))
tp = np.sum(((oof_test_final == 1) & (test_label == 1)))
pp = np.sum(oof_test_final == 1)
print('sensitivity:%.3f'% (tp/(pp)))
这里我们假设在每天即将收盘的时候买入股票(在即将收盘的时候可以利用获取的实时行情来选股,获取的各项指标可以近似为当日收盘后的指标)。所以,在测试集中选出来的股票并不一定能买入,因为会有一些涨停股票,这里我们需要筛选掉一些涨停股票。
在筛选的时候我们直接判断当日收盘价是否等于当日最高价。这里也是有bug的,当日收盘等于当日最高但不一定到涨停价。尝试过先判断是否ST,再判断涨幅,但是现在不是ST的之前可能是ST。(这个筛选后期可以改进)
test_postive_idx = np.argwhere(oof_test_final == 1).reshape(-1)
test_all_idx = np.argwhere(test_data_idx).reshape(-1)
# 查看选了哪些股票
tmp_col = ['ts_code', 'name', 'trade_date', 'open', 'high', 'low', 'close', 'pre_close',
'change', 'pct_chg', 'amount', 'is_ST', 'label_max', 'label_min', 'label_final']
# stock_info.iloc[test_all_idx[test_postive_idx]]
tmp_df = stock_info[tmp_col].iloc[test_all_idx[test_postive_idx]].reset_index()
# idx_tmp = tmp_df['is_ST'] == 0
# tmp_df.loc[idx_tmp, 'is_limit_up'] = (((tmp_df['close'][idx_tmp]-tmp_df['pre_close'][idx_tmp]) / tmp_df['pre_close'][idx_tmp]) > 0.095)
# idx_tmp = tmp_df['is_ST'] == 1
# tmp_df.loc[idx_tmp, 'is_limit_up'] = (((tmp_df['close'][idx_tmp]-tmp_df['pre_close'][idx_tmp]) / tmp_df['pre_close'][idx_tmp]) > 0.047)
tmp_df['is_limit_up'] = tmp_df['close'] == tmp_df['high']
buy_df = tmp_df[(tmp_df['is_limit_up']==False)].reset_index()
buy_df.drop(['index', 'level_0'], axis=1, inplace=True)
print(len(buy_df), sum(buy_df['label_final']))
然后统计了一下,一共有46支股票在未来可以选择,12支股票能够有5%以上收益。

回测:
然后就是回测了,回测的程序昨天已经讲过了,链接为 选股策略搭建(二),今天简单讲一下我们的回测策略。首先持股周期5天,止盈点为5%,止损点为3%,买入股票后不加仓不减仓。
# stock_info.reset_index().head()
# 读取指数信息
index_df = pd.read_csv(os.path.join(base_path, 'OldData', '000001.SH' + '_NormalData.csv'))
tmp_idx = (index_df['trade_date'] >= test_date_min) & (index_df['trade_date'] <= test_date_max)
index_df = index_df.loc[tmp_idx].reset_index()
index_df.drop('index', axis=1, inplace=True)
tmp_idx = (index_df['trade_date'] == test_date_min)
close1 = index_df[tmp_idx]['close'].values[0]
tmp_idx = (index_df['trade_date'] == test_date_max)
close2 = index_df[tmp_idx]['close'].values[0]
from imp import reload
import Account
reload(Account)
money_init = 100000
account = Account.Account(money_init)
account.BackTest(buy_df, stock_info_copy, index_df)

这是我们的部分交易信息:

这是账户盈利情况:
account_profit = (account.market_value - money_init) / money_init
index_profit = (close2 - close1) / close1
win_rate = account.victory / (account.victory + account.defeat)
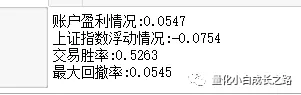
print('账户盈利情况:%.4f' % account_profit)
print('上证指数浮动情况:%.4f' % index_profit)
print('交易胜率:%.4f' % win_rate)
print('最大回撤率:%.4f' % account.max_retracement)
这是账户变化情况,可见我们策略是远远领先大盘的

接下来我们分析一下我们的模型学习到了什么选股思路:(这里挑选了部分分析)
这个应该是想在下跌中强反弹。

这个应该也是想在洗盘时介入,但是介入失败,止损出局。(箭头标的不是很准)

这个应该是超跌反弹,抓住反弹切入点。

总结:
从这几个选出来的股票中,可以发现我们的模型还是有一定能力选出优秀的股票的,但还是需要继续完善,所提取的特征不够多,还有一些均线信息也可以帮助我们选股。接下来的一段时间我将会开始挖掘特征,更新要开始变缓慢了。
对股票、量化、数据挖掘、机器学习、深度学习感兴趣的可以关注公众号,个人不不定期分享一些学习心得。后期策略成熟将不定期分享股票。
以上包括jupyer的所有代码已上传至github,研究的同时别忘了给星,感谢!
github链接为:https://github.com/wbbhcb/stock_market
个人公众号,这里放一个个人公众号,后期策略成熟将会在公众号中分享个股.

个人知乎: https://www.zhihu.com/people/e-zhe-shi-wo/activities