79单词搜索

思路:

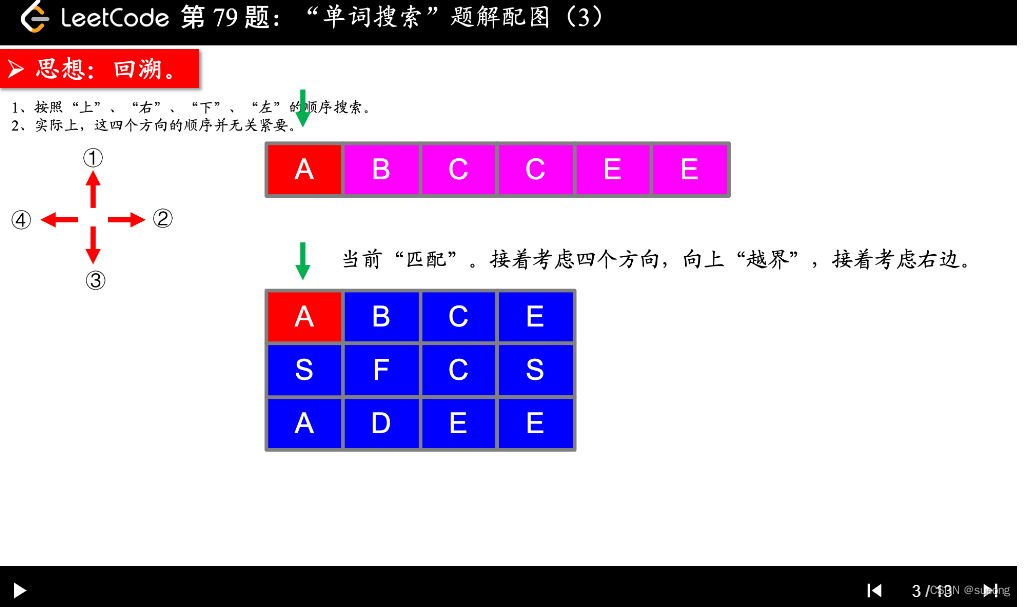
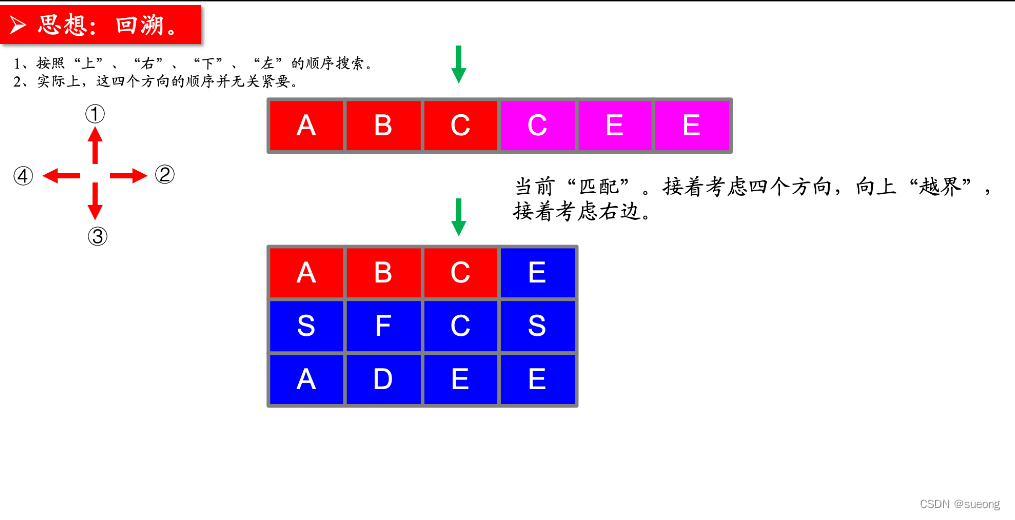



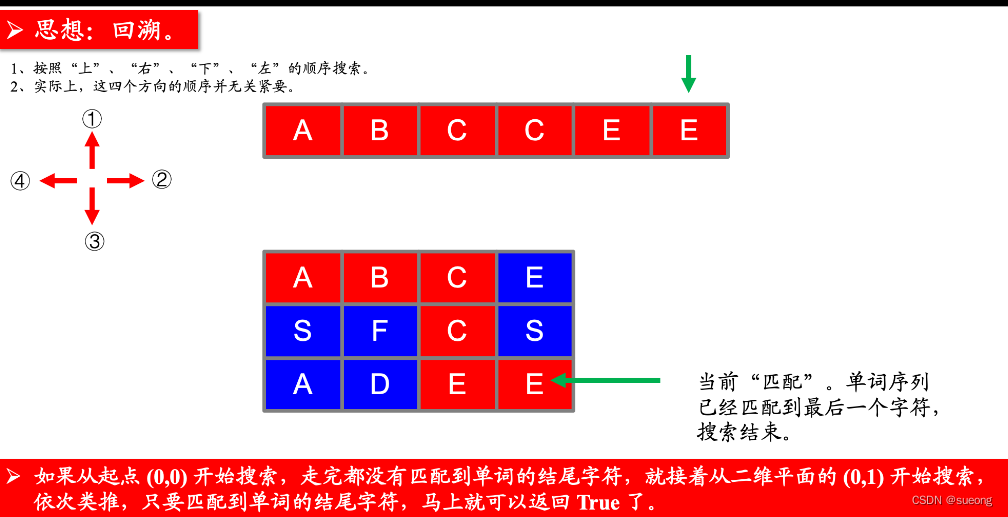
注意:
我自己在写
for i in range(m):
for j in range(n):
# 对每一个格子都从头开始搜索
if self.__search_word(board, word, 0, i, j, marked, m, n):
return True
这一段的时候,就写成了:
这一段代码是错误的,不要模仿
for i in range(m):
for j in range(n):
# 对每一个格子都从头开始搜索
return self.__search_word(board, word, 0, i, j, marked, m, n)
这样其实就变成只从坐标 (0,0) 开始搜索,搜索不到返回 False,但题目的意思是:只要你的搜索返回 True 才返回,如果全部的格子都搜索完了以后,都返回 False ,才返回 False。
class Solution:
directs = [(0,1),(0,-1),(1,0),(-1,0)]
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
if m == 0:
return False
n = len(board[0])
visited = [[0] * n for _ in range(m)]
for i in range (0,m):
for j in range (0,n):
if self.dfs(i, j, 0, board, word, visited):
return True
return False
def dfs(self, x, y, begin, board, word, visited):
if begin == len(word) - 1:
return board[x][y] == word[begin]
if board[x][y] == word[begin]:
visited[x][y] = 1
for dire in self.directs:
new_x = x + dire[0]
new_y = y + dire[1]
if 0 <= new_x < len(board) and 0<= new_y < len(board[0]) and visited[new_x][new_y]==0:
if self.dfs(new_x, new_y, begin+1, board, word, visited):
return True
visited[x][y] = 0
return False
class Solution:
directs = [(0,1),(0,-1),(1,0),(-1,0)]
def exist(self, board: List[List[str]], word: str) -> bool:
m = len(board)
if m == 0:
return False
n = len(board[0])
visited = [[0] * n for _ in range(m)]
def dfs(x, y, begin):
if begin == len(word) - 1:
return board[x][y] == word[begin]
if board[x][y] == word[begin]:
visited[x][y] = 1
for dire in self.directs:
new_x = x + dire[0]
new_y = y + dire[1]
if 0 <= new_x < len(board) and 0<= new_y < len(board[0]) and visited[new_x][new_y]==0:
if dfs(new_x, new_y, begin+1):
return True
visited[x][y] = 0
return False
for i in range (0,m):
for j in range (0,n):
if dfs(i, j, 0):
return True
return False
208 前缀树

包含三个单词 “sea”,“sells”,“she” 的 Trie 会长啥样呢?

简化后:
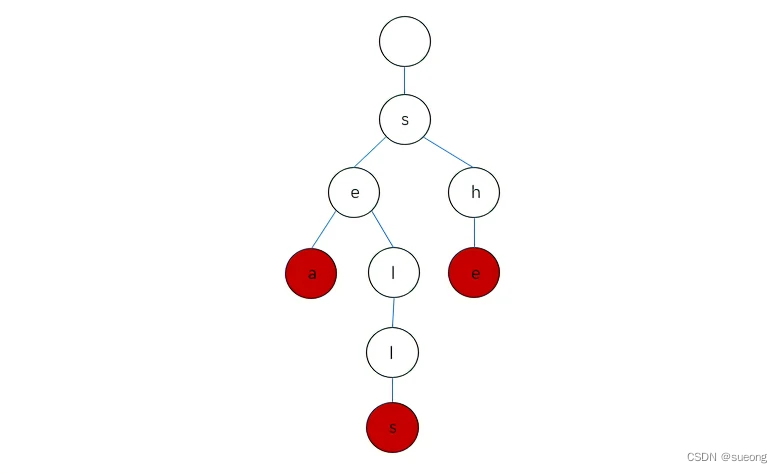
定义类 Trie
class Trie {
private:
bool isEnd;
Trie* next[26];
public:
};
插入
描述:向 Trie 中插入一个单词 word
实现:这个操作和构建链表很像。首先从根结点的子结点开始与 word 第一个字符进行匹配,一直匹配到前缀链上没有对应的字符,这时开始不断开辟新的结点,直到插入完 word 的最后一个字符,同时还要将最后一个结点isEnd = true;,表示它是一个单词的末尾。
void insert(string word) {
Trie* node = this;
for (char c : word) {
if (node->next[c-'a'] == NULL) {
node->next[c-'a'] = new Trie();
}
node = node->next[c-'a'];
}
node->isEnd = true;
}
查找
描述:查找 Trie 中是否存在单词 word
实现:从根结点的子结点开始,一直向下匹配即可,如果出现结点值为空就返回 false,如果匹配到了最后一个字符,那我们只需判断 node->isEnd即可。
bool search(string word) {
Trie* node = this;
for (char c : word) {
node = node->next[c - 'a'];
if (node == NULL) {
return false;
}
}
return node->isEnd;
}
前缀匹配
描述:判断 Trie 中是或有以 prefix 为前缀的单词
实现:和 search 操作类似,只是不需要判断最后一个字符结点的isEnd,因为既然能匹配到最后一个字符,那后面一定有单词是以它为前缀的。
bool startsWith(string prefix) {
Trie* node = this;
for (char c : prefix) {
node = node->next[c-'a'];
if (node == NULL) {
return false;
}
}
return true;
}
链接:https://leetcode.cn/problems/implement-trie-prefix-tree/solution/trie-tree-de-shi-xian-gua-he-chu-xue-zhe-by-huwt/
class Trie:
def __init__(self):
self.next = [None] * 26
self.isEnd = False
def insert(self, word: str) -> None:
node = self
for ch in word:
if node.next[ord(ch) - ord('a')] == None:
node.next[ord(ch) - ord('a')] = Trie()
node = node.next[ord(ch) - ord('a')]
node.isEnd = True
def search(self, word: str) -> bool:
node = self
for ch in word:
if node.next[ord(ch) - ord('a')] == None:
return False
node = node.next[ord(ch) - ord('a')]
return node.isEnd
def startsWith(self, prefix: str) -> bool:
node = self
for ch in prefix:
if node.next[ord(ch) - ord('a')] == None:
return False
node = node.next[ord(ch) - ord('a')]
return True
211. 添加与搜索单词 - 数据结构设计

思路:和208构建字典树类似
只是查询的时候需要对通配符.特殊处理,

class WordDictionary:
def __init__(self):
self.next = [None] * 26
self.isEnd = False
def addWord(self, word: str) -> None:
node = self
for ch in word:
if node.next[ord(ch) - ord("a")] == None:
node.next[ord(ch) - ord("a")] = WordDictionary()
node = node.next[ord(ch) - ord("a")]
node.isEnd = True
def search(self, word: str) -> bool:
root = self
def dfs(index,node):
if index == len(word):
return node.isEnd
ch = word[index]
if ch != '.':
child = node.next[ord(ch) - ord("a")]
if child != None and dfs(index+1,child):
return True
else:
for child in node.next:
if child != None and dfs(index+1,child):
return True
return False
return dfs(0,root)
212单词搜索 II

思路:
对棋盘上的每个位置进行dfs,对输入的单词集合构建成字典树,对于棋盘上的任意位置(i,j)只有在字典树存在从字符a到字符b的边的时候,我们才能在棋盘上找到a-b的路径,
注意:
回溯过程,每次只需要判断新增单元格的字母是否是上一个单元格对应前缀树结点的子结点即可。

from collections import defaultdict
class TrieNode:
def __init__(self):
self.children = defaultdict(TrieNode)
self.word = ""
def insert(self, word):
node = self
for ch in word:
node = node.children[ch]
node.word = word
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
trie = TrieNode()
for word in words:
trie.insert(word)
print(trie.children)
print( "b" in trie.children['o'].children)
m,n = len(board),len(board[0])
directions = [(0,1),(0,-1),(1,0),(-1,0)]
def dfs(x, y, node):
ch = board[x][y]
if ch not in node.children:
return
child = node.children[ch]
if child.word!="":
res.add(child.word)
if child.children:
board[x][y] = '#'
for dire in directions:
new_x = x + dire[0]
new_y = y + dire[1]
if 0<= new_x < m and 0 <= new_y < n and board[new_x][new_y]!="#":
dfs(new_x, new_y, child)
board[x][y] = ch
res = set()
for i in range(m):
for j in range(n):
dfs(i,j,trie)
return list(res)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)