之前的文章可以看这里
深度强化学习主流算法介绍(一):DQN系列
相关论文在这里

开始介绍DPG之前,先回顾下DQN系列
DQN直接训练一个Q Network 去估计每个离散动作的Q值,使用时选择Q值大的动作去执行(贪婪策略)
DQN可以处理每个离散的动作,对于连续动作空间上,虽然可以细分步长转化为更多的离散动作来做,但效果不好且训练成本倍增,由此学者们想到了Policy Gradient 确定策略梯度。
一、PG Policy Gradient

策略梯度算法是一种更为直接的方法,它让神经网络直接输出策略函数 π(s),即在状态s下应该执行何种动作。对于非确定性策略,输出的是这种状态下执行各种动作的概率值,即如下的条件概率
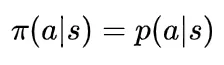
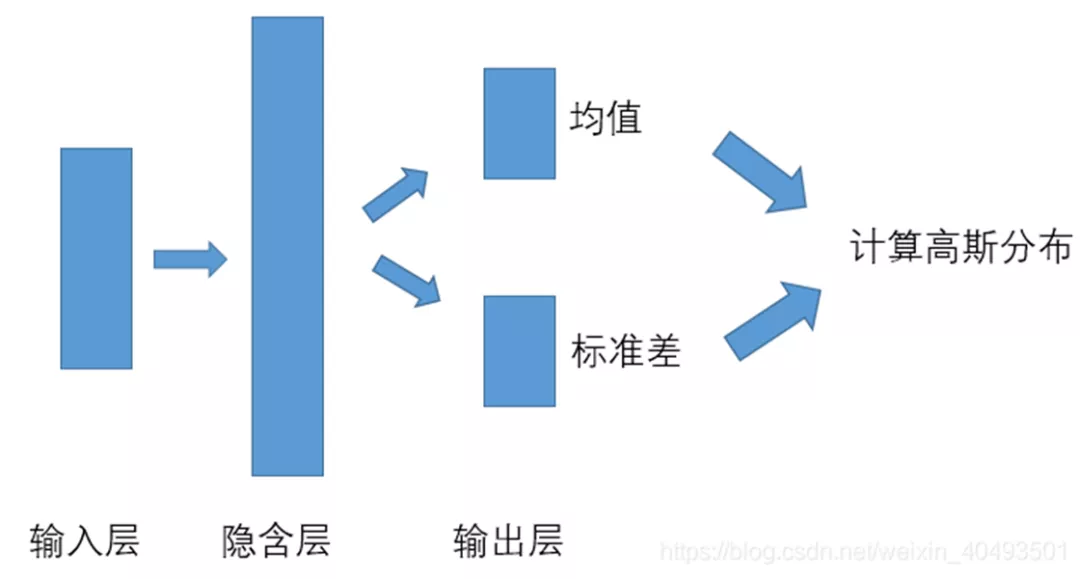
对于连续性动作来说,一般使用随机高斯策略,网络的输入是智能体当前状态,网络的输出的高斯策略的均值和标准差,网络是一个拟合网络。
无论是连续动作还是离散动作,在使用PG时,必须先弄清下面公式,离散动作和连续动作最大的不同就在于

连续动作PG算法网络模型如下
二、DPG Deterministic Policy Gradient Algorithms确定性策略梯度算法
DPG是最早的一篇文章,主要从理论的角度提出了一种deterministic、off-policy的policy gradient算法,并给出了policy gradient的计算公式和参数更新方法。
DQN在DPG后一年发表,主要是解决了用神经网络拟合Q函数(也就是action-value函数)导致的训练不稳定的问题。在DQN出现之前,神经网络被认为是不适合做Q函数的近似的,而DQN则使得这个“不可能”成为了现实。
在这两个work的基础上,DDPG结合了DPG和DQN,也就是将DQN中用来拟合Q函数的神经网络用在了DPG的框架中,并加入了batch normalization的trick,形成了一套真正可用的、基于深度神经网络的(这也是DDPG名字中Deep的来源)的DPG算法。


相对于stochastic function随机函数,用deterministic function确定函数表示policy有其优点和缺点。
优点就是,从理论上可以证明,deterministic policy的梯度就是Q函数梯度的期望,这使得deterministic方法在计算上比stochastic方法更高效;
但缺点也很明显,对于每个state,下一步的action是确定的。这就导致只能做exploitation而不能做exploration。
这可能也是为什么policy gradient一开始就采用stochastic算法的原因。为了解决不能做exploration的问题,DPG采用了off-policy的方法。也就是说,采样的policy和待优化的policy是不同的:其中采样的policy是stochastic的,而待优化的policy是deterministic的。采样policy的随机性保证了充分的exploration。
详细地说DPG公式如下


一句话说就是:用确定性的策略来选择每次的动作,即给定当前状态可以通过函数确定该做什么动作
三、AC 行动者评论家(Actor-Critic)框架
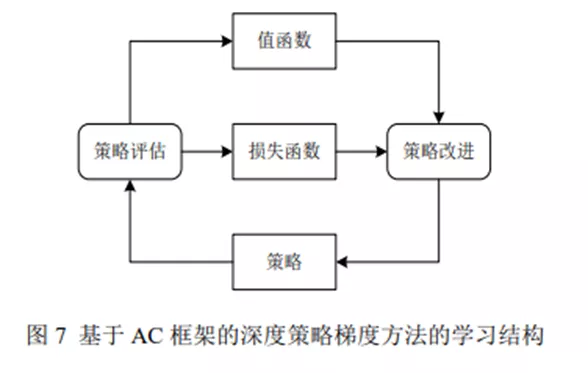

有一点像生成对抗网络GAN的感觉,对抗网络和强化学习的AC框架,都是采用两个网络(Adversarial hebavior)的双层优化算法。
AC框架 在每次actor做完动作后,critic对其进行评价并引导改进方向,两边同时都在学习
四、soft target update(软更新)
算是一个技巧,在更新参数的时候,不是同步更新(这样训练不稳定),也不是像DQN那样设置时间间隔更新,而是每步以小步长进行更新,称为软更新。

五、DDPG (Deep DPG) 深度确定策略梯度
集DPG和DQN之大成者——DDPG
在DQN的loss function中:
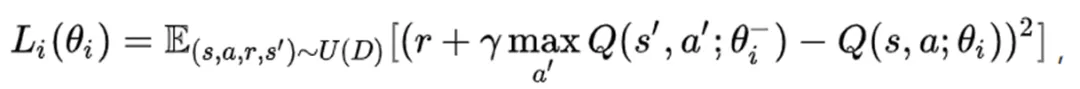
有一个求最大value的action的操作。如果action space非常大,甚至是连续的action space(例如实数空间),那么这个求最大的操作是不可能完成的。即使是将连续的space离散化,也会导致非常低的算法效率。而DPG的policy gradient则没有上述的寻找最大化的操作

所以将两者优势结合起来,并运用刚刚提到的AC框架,actor探索,critic修正,既避免了找最大化的过程,能有较强的探索能力。
详细的算法过程如下

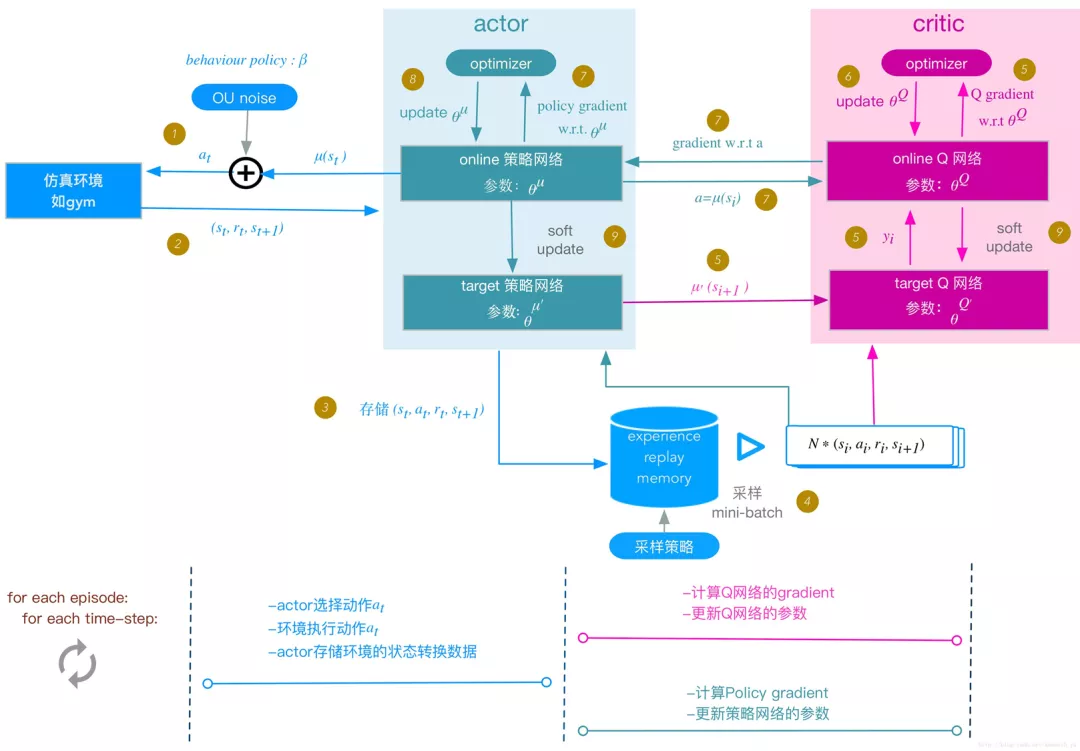
DDPG 算法中的 actor 和 critic 都使用两个网络:online network 和 target network。


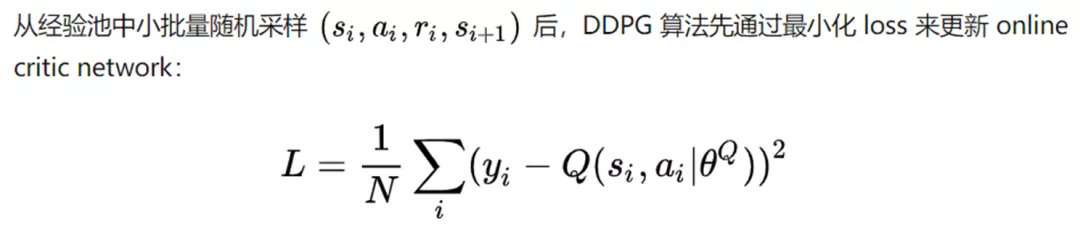

一句话说就是:结合DQN和DDPG,利用AC框架,actor在确定性策略得到动作的同时,加入噪声保证探索能力,并用critic进行评价修正
六、TD3 Twin Delay DDPG

简而言之就是用两个评论家,选小的作为评价结果,避免Q值高估
七、A3C :Asynchronous Advantage Actor-Critic 异步的优势行动者评论家算法
具体地,A3C 算法利用 CPU 多线程的功能并行、异步地执行多个 agent.
因此在任意时刻,并行 的 agent 都将会经历许多不同的状态,去除了训练 过程中产生的状态转移样本之间的关联性.因此这种低消耗的异步执行方式可以很好地替代经验回放机制. 一个critic多个actor和复制的环境进行交互
降低了随机策略梯度算法估计Q值的难度
缺陷:不是任何时刻 action 都会影响 state的转移
八、A2C Advantage Actor-Critic
A2C是A3C的同步、确定版本;这也是为什么要把A3C的第一个”A“(”异步“)去掉。
在A3C中,每个演员独立地与(保存)全局参数(的服务器)进行交互,因此有时不同线程中的演员将使用不同版本的策略,因此累积更新的方向将不是最优的。
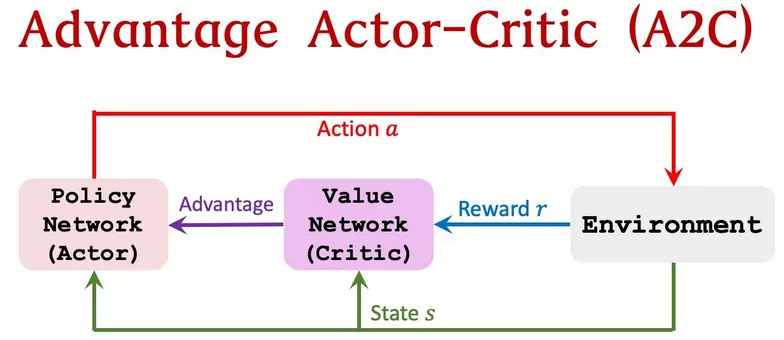
为了解决上述执行策略不一致问题,A2C中引入协调器,在更新全局参数之前等待所有并行的演员完成其工作,那么在下一次迭代中并行的演员将均执行同一策略。同步的梯度更新使得训练过程更加耦合因而有可能使得算法具有更快的收敛速度。
A2C已被证明在能够实现与A3C相同或更好的性能的同时,更有效地利用GPU,并且能够适应更大的批量大小。
总结:
DPG系列是利用基于策略的方法,直接尝试找到当前状态下的最佳策略,并在DDPG中引入AC框架和软更新技巧,这两者在后续的算法中基本算是标配了。
在处理连续动作空间问题的时候,虽然可以细分成离散动作强行用DQN,但还是推荐用现成的连续动作空间的算法。
DDPG算是连续动作的入门算法,如果擅长调参用TD3,不擅长的话可以用后续将要介绍的的PPO或者SAC。