一、faceRecognition接口说明
/*******************************************************************
** 函数名: faceRecognition
** 函数描述: 人脸识别
** 参数: [int] recognitionPic: 识别的照片,[int] targetFaceIndex: 目标匹配照片索引值
** 返回: 失败返回-1,成功返回0
** 注意:
********************************************************************/
int faceRecognition(char *recognitionPic, int targetFaceIndex)
{
Mat srcImg, targetImg, compImage;
IplImage* faceImage;
int predict = 0;
char cmd[100] = {0};
/* 加载人脸检测器 */
CascadeClassifier cascade;
if(!cascade.load(cascadeName))
{
printf("[cwr] load CascadeClassifier fail\n");
return -1;
}
//model = createEigenFaceRecognizer(0, SIMILAR_VALUE);
model = createEigenFaceRecognizer();
if (0 != access(TRAIN_XML, F_OK)) {
trainPicture();
}
model->load(TRAIN_XML);
srcImg = imread(recognitionPic);
faceImage = detectFace(srcImg, cascade);
if (faceImage == NULL) return -1;
Mat cutImage(faceImage, 1);
resize(cutImage, compImage, Size(DEFAULT_CUT_SIZE_W, DEFAULT_CUT_SIZE_H), ZOOM_SCALE, ZOOM_SCALE);//对人脸进行缩放,并且设置成特定分辨率
imwrite(savePicture, compImage);
/* 开始人脸比对 */
#if 0
imshow("compare", compImage);
waitKey(0);
#endif
int predictLabel = -1;
double predictConfidence = 0.0;
model->predict(compImage, predictLabel, predictConfidence);
printf("[cwr] predictLabel = %d\n", predictLabel);
printf("[cwr] predictConfidence = ");
cout<<predictConfidence<<endl;
//predict = model->predict(compImage);
//printf("[cwr] faceRecognition return predict: %d\n", predict);
#if 1
if (predictLabel == targetFaceIndex && predictConfidence <= SIMILAR_VALUE) {
printf("[cwr] Face recognition successful\n");
s_faceRecognitionSuc++;
} else {
printf("[cwr] Face recognition fail\n");
s_faceRecognitionFail++;
}
#endif
printf("[cwr] Face recognition success total cnt = %d, Face recognition fail total cnt = %d, Detect face fail total cnt = %d\n", s_faceRecognitionSuc, s_faceRecognitionFail, s_delectFaceFail);
return 0;
}
1.1 Mat
(1)什么是Mat
矩阵的英文释义matrix,因此延伸出Mat这个缩写,Mat类简单理解为存放图片数据的容器。
在计算机内存中,数字图像以矩阵的形式存储和运算,比如,在MatLab中,图像读取之后对应一个矩阵,在OpenCV中,同样也是如此。数字图像存储时,我们存储的是图像每个像素点的数值,对应的是一个数字矩阵。
【照片是以矩阵的方式存储】
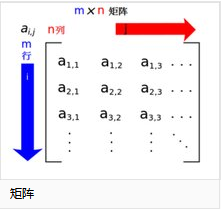
灰度图像的像素数据就是一个矩阵,矩阵的行对应图像的高(单位为像素),矩阵的列对应图像的宽(单位为像素),矩阵的元素对应图像的像素,矩阵元素的值就是像素的灰度值。
灰度图像就是黑白照片,所以opencv操作图像都需要先转化为灰度照片来提高速度。
灰度值,我自己的理解应该就是黑白之前的差异,亮或者暗,这两者关系。
图像灰度值 灰度值与像素值的关系 - bingqingsuimeng的专栏 - CSDN博客 https://blog.csdn.net/bingqingsuimeng/article/details/64440699
Mat类的组成,由两部分数据组成:矩阵头(包含矩阵尺寸、存储方法、存储地址等)和一个指向存储所有像素值的矩阵(根据所选存储方法的不同,矩阵可以是不同的维数)的指针。
1.2 IplImage
在OpenCV中IplImage是表示一个图像的结构体,也是从OpenCV1.0到目前最为重要的一个结构;
在之前的图像表示用IplImage,而且之前的OpenCV是用C语言编写的,提供的接口也是C语言接口。
Mat是后来OpenCV封装的一个C++类,用来表示一个图像,和IplImage表示基本一致,但是Mat还添加了一些图像函数;
IplImage转Mat
IplImage* faceImage;
Mat cutImage(faceImage, 1);
1.3 opencv常用图像处理函数
(1)resize函数说明
void resize(InputArray src, OutputArray dst, Size dsize, double fx=0, double fy=0, int interpolation=INTER_LINEAR );
参数说明:
src:输入,原图像,即待改变大小的图像;
dst:输出,改变大小之后的图像,这个图像和原图像具有相同的内容,只是大小和原图像不一样而已;
dsize:输出图像的大小。如果这个参数不为0,那么就代表将原图像缩放到这个Size(width,height)指定的大小;如果这个参数为0,那么原图像缩放之后的大小就要通过下面的公式来计算:
dsize = Size(round(fx*src.cols), round(fy*src.rows)) cols列 rows行
其中,fx和fy就是下面要说的两个参数,是图像width方向和height方向的缩放比例。
fx:width方向的缩放比例,如果它是0,那么它就会按照(double)dsize.width/src.cols来计算;
fy:height方向的缩放比例,如果它是0,那么它就会按照(double)dsize.height/src.rows来计算;
interpolation:这个是指定插值的方式,图像缩放之后,肯定像素要进行重新计算的,就靠这个参数来指定重新计算像素的方式,有以下几种:
INTER_NEAREST - 最邻近插值
INTER_LINEAR - 双线性插值,如果最后一个参数你不指定,默认使用这种方法
INTER_AREA - resampling using pixel area relation. It may be a preferred method for image decimation, as it gives moire’-free results. But when the image is zoomed, it is similar to the INTER_NEAREST method.
INTER_CUBIC - 4x4像素邻域内的双立方插值
INTER_LANCZOS4 - 8x8像素邻域内的Lanczos插值
【感觉最后一个参数都不用设置】
resize(img, dst, Size(300, 200), 0.3, 0.3);//将原图比例缩放0.3 并且分辨率设置为300 200
缩放就是按照原图的分辨率进行缩放。如果Size已经设置分辨率了,就没必要设置缩放比例了。优先会设置分辨率。
但是如果是打算图片按比例缩小,最简单的方法就是调整比例。resize(img, dst, Size(), 0.3, 0.3) Size()直接内部参数为空就好。
保存指定的分辨率直接resize(img, dst, Size(300, 200), 1, 1) 在Size()内部设置自己想要的参数即可。
使用注意事项:
- dsize和fx/fy不能同时为0,要么你就指定好dsize的值,让fx和fy空置直接使用默认值,就像
resize(img, imgDst, Size(30,30));
要么你就让dsize为0,指定好fx和fy的值,比如fx=fy=0.5,那么就相当于把原图两个方向缩小一倍!
- 至于最后的插值方法,正常情况下使用默认的双线性插值就够用了。
几种常用方法的效率是:最邻近插值>双线性插值>双立方插值>Lanczos插值;
但是效率和效果成反比,所以根据自己的情况酌情使用。
- 正常情况下,在使用之前dst图像的大小和类型都是不知道的,类型从src图像继承而来,大小也是从原图像根据参数计算出来。但是如果你事先已经指定好dst图像的大小,那么你可以通过下面这种方式来调用函数:
resize(src, dst, dst.size(), 0, 0, interpolation);
OpenCV图像中的x,y;width,height;cols,rows
x:横坐标
y:纵坐标
width:宽度
height:高度
cols:代表有多少列,其实就是x
rows:代表有多少行,其实就是y

(2)imwrite
1、filename:需要写入的文件名,会自己创建(像imwrite(“1.jpeg”,src);这样)
2、img:要保存的图像
3、params:表示为特定格式保存的参数编码
注意:你要保存图片为哪种格式,就带什么后缀。
(3)imshow
Displays an image in the specified window. 在特定的窗口上显示图像。
C++: void imshow(const string& winname, InputArray image)
Parameters:
winname – Name of the window. 窗口名称。
image – Image to be shown. 要显示的图像。
(4)imread
API详解:
原型:Mat imread(const string& filename, int flags = 1) ;
参数1:需要载入图片的路径名,例如“C:/daima practice/opencv/mat3/mat3/image4.jpg”
参数2:加载图像的颜色类型。默认为1. 若为0则灰度返回,若为1则原图返回。
flags = -1:imread按解码得到的方式读入图像
flags = 0:imread按单通道的方式读入图像,即灰白图像
flags = 1:imread按三通道方式读入图像,即彩色图像
(5) waitKey
waitKey(x);
第一个参数: 等待x ms,如果在此期间有按键按下,则立即结束并返回按下按键的
ASCII码,否则返回-1
如果x=0,那么无限等待下去,直到有按键按下
另外,在imshow之后如果没有waitKey语句则不会正常显示图像。
1.4 人脸检测
(1)CascadeClassifier
这个叫级联分类器。用于opencv人脸检测。
cascade.load(cascadeName) 对级联分类器进行初始化。
只需要初始化CascadeClassifier级联分类器,通过加载xml文件(人脸检测器),级联分类器可以根据xml来支持不同的识别效果。

有识别眼睛、身体等。
常用的一些成员说明,具体可以查看源码/opencv-2.4.10/modules/objdetect/doc/cascade_classification.rst
定义以及函数解释都在源码中注明了
class CV_EXPORTS_W CascadeClassifier
{
public:
CV_WRAP CascadeClassifier();
//从文件中加载级联分类器
CV_WRAP CascadeClassifier(const String& filename);
~CascadeClassifier();
//检测级联分类器是否被加载
CV_WRAP bool empty() const;
//从文件中加载级联分类器
CV_WRAP bool load( const String& filename );
//从FileStorage节点读取分类器
CV_WRAP bool read( const FileNode& node );
/** 检测输入图像中不同大小的对象。检测到的对象以矩形列表的形式返回。
参数:
image: 包含检测对象的图像的CV_8U类型矩阵
objects: 矩形的向量,其中每个矩形包含被检测的对象,矩形可以部分位于原始图像之外
scaleFactor: 指定在每个图像缩放时的缩放比例
minNeighbors:指定每个候选矩形需要保留多少个相邻矩形
flags:含义与函数cvHaarDetectObjects中的旧级联相同。它不用于新的级联
minSize:对象最小大小,小于该值的对象被忽略。
maxSize:最大可能的对象大小,大于这个值的对象被忽略
该函数与TBB库并行
*/
CV_WRAP void detectMultiScale( InputArray image,
CV_OUT std::vector<Rect>& objects,
double scaleFactor = 1.1,
int minNeighbors = 3, int flags = 0,
Size minSize = Size(),
Size maxSize = Size() );
/**
detectMultiScale重载函数
参数:
image:包含检测对象的图像的CV_8U类型矩阵
objects: 矩形的向量,其中每个矩形包含被检测的对象,矩形可以部分位于原始图像之外
numDetections: 对应对象的检测编号向量。一个物体被探测到的次数是相邻的被积极分类的矩形的数量,这些矩形被连接在一起形成物体
scaleFactor: 指定在每个图像缩放时的缩放比例
minNeighbors:指定每个候选矩形需要保留多少个相邻矩形
flags:含义与函数cvHaarDetectObjects中的旧级联相同。它不用于新的级联
minSize:对象最小大小,小于该值的对象被忽略。
maxSize:最大可能的对象大小,大于这个值的对象被忽略
*/
CV_WRAP_AS(detectMultiScale2) void detectMultiScale( InputArray image,
CV_OUT std::vector<Rect>& objects,
CV_OUT std::vector<int>& numDetections,
double scaleFactor=1.1,
int minNeighbors=3, int flags=0,
Size minSize=Size(),
Size maxSize=Size() );
/**
detectMultiScale重载函数,此函数允许您检索分类的最终阶段决策确定性
为此,需要将' outputRejectLevels '设置为true,并提供' rejectLevels '和' levelWeights '参数。
对于每一个结果检测,‘levelWeights’将在最后阶段包含分类的确定性。
这个值可以用来区分强分类和弱分类。
具体使用示例代码
Mat img;
vector<double> weights;
vector<int> levels;
vector<Rect> detections;
CascadeClassifier model("/path/to/your/model.xml");
model.detectMultiScale(img, detections, levels, weights, 1.1, 3, 0, Size(), Size(), true);
cerr << "Detection " << detections[0] << " with weight " << weights[0] << endl;
*/
CV_WRAP_AS(detectMultiScale3) void detectMultiScale( InputArray image,
CV_OUT std::vector<Rect>& objects,
CV_OUT std::vector<int>& rejectLevels,
CV_OUT std::vector<double>& levelWeights,
double scaleFactor = 1.1,
int minNeighbors = 3, int flags = 0,
Size minSize = Size(),
Size maxSize = Size(),
bool outputRejectLevels = false );
CV_WRAP bool isOldFormatCascade() const;
CV_WRAP Size getOriginalWindowSize() const;
CV_WRAP int getFeatureType() const;
void* getOldCascade();
CV_WRAP static bool convert(const String& oldcascade, const String& newcascade);
void setMaskGenerator(const Ptr<BaseCascadeClassifier::MaskGenerator>& maskGenerator);
Ptr<BaseCascadeClassifier::MaskGenerator> getMaskGenerator();
Ptr<BaseCascadeClassifier> cc;
};
(2)detectMultiScale
调用分类器内部的成员函数detectMultiScale(多尺度检测)
参数1:image–待检测图片,一般为灰度图像加快检测速度;
参数2:objects–被检测物体的矩形框向量组;
参数3:scaleFactor–表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
参数4:minNeighbors–表示构成检测目标的相邻矩形的最小个数(默认为3个),每一个人脸至少要检测到多少次才算是真的人脸。
如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,
这种设定值一般用在用户自定义对检测结果的组合程序上;
参数5:flags–要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为
CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,因此这些区域通常不会是人脸所在区域;决定是缩放分类器来检测,还是缩放图像。
参数6、7:minSize和maxSize用来限制得到的目标区域的范围。表示人脸的最大最小尺寸。
参数3设置测试情况,参考网上的,目测没啥卵用。:
传1.1:400张测试图片识别率为85.3%。
传1.2:400张测试图片识别率为78.7%。
传1.05: 400张测试图片识别率为94.0%。
#define CV_HAAR_DO_CANNY_PRUNING 1 //这个值告诉分类器跳过平滑(无边缘)区域
#define CV_HAAR_SCALE_IMAGE 2 //这个值告诉分类器不要缩放分类器,而是缩放图像
#define CV_HAAR_FIND_BIGGEST_OBJECT 4 //告诉分类器只返回最大的目标
#define CV_HAAR_DO_ROUGH_SEARCH 8 //它只能和上面一个参数一起使用,告诉分类器在任何窗口,只要第一个候选者被发现则结束搜寻。
在OpenCV的安装目录下的sources文件夹里的data文件夹里可以看到,文件夹的名字“haarcascades”、“hogcascades”和“lbpcascades”分别表示通过“haar”、“hog”和“lbp”三种不同的特征而训练出的分类器:即各文件夹里的文件。"haar"特征主要用于人脸检测,“hog”特征主要用于行人检测,“lbp”特征主要用于人脸识别。
(3)rect
如果创建一个Rect对象rect(100, 50, 50, 100),那么rect会有以下几个功能:
rect.area(); //返回rect的面积 5000
rect.size(); //返回rect的尺寸 [50 × 100]
rect.tl(); //返回rect的左上顶点的坐标 [100, 50]
rect.br(); //返回rect的右下顶点的坐标 [150, 150]
rect.width(); //返回rect的宽度 50
rect.height(); //返回rect的高度 100
rect.contains(Point(x, y)); //返回布尔变量,判断rect是否包含Point(x, y)点
通过faces.size()来判断是否检测到人脸,返回0说明未检测到人脸,返回1表示检测到一个人脸。依次类推,通过该参数返回判断检测到的人脸个数。
1.5 人脸识别
(1)FaceRecognizer
人脸识别的类FaceRecognizer
class FaceRecognizer : public Algorithm
{
public:
//! virtual destructor
virtual ~FaceRecognizer() {}
// Trains a FaceRecognizer.
virtual void train(InputArray src, InputArray labels) = 0;
// Updates a FaceRecognizer.
virtual void update(InputArrayOfArrays src, InputArray labels);
// Gets a prediction from a FaceRecognizer.
virtual int predict(InputArray src) const = 0;
// Predicts the label and confidence for a given sample.
virtual void predict(InputArray src, int &label, double &confidence) const = 0;
// Serializes this object to a given filename.
virtual void save(const string& filename) const;
// Deserializes this object from a given filename.
virtual void load(const string& filename);
// Serializes this object to a given cv::FileStorage.
virtual void save(FileStorage& fs) const = 0;
// Deserializes this object from a given cv::FileStorage.
virtual void load(const FileStorage& fs) = 0;
// Sets additional information as pairs label - info.
void setLabelsInfo(const std::map<int, string>& labelsInfo);
// Gets string information by label
string getLabelInfo(const int &label);
// Gets labels by string
vector<int> getLabelsByString(const string& str);
};
(2)opencv Ptr
OpenCV中使用的智能指针。类似于std::smart_ptr,但是在OpenCV中可以用Ptr轻松管理各种类型的指针。
//可以用Ptr ptr代替MyObjectType* ptr,MyObjectType可以是C的结构体或C++的类,
智能指针有空再研究吧。
OpenCV笔记(Ptr) - fireae - 博客园 https://www.cnblogs.com/fireae/p/3684915.html
C++11中智能指针的原理、使用、实现 - wxquare - 博客园 https://www.cnblogs.com/wxquare/p/4759020.html
(3)目前支持的三种算法
Eigenfaces 特征脸createEigenFaceRecognizer()
Fisherfaces createFisherFaceRecognizer()
LocalBinary Patterns Histograms局部二值直方图 createLBPHFaceRecognizer()
(4)predict的用法
方法1:
int predict = 0;
predict = model->predict(compImage);
将照片传入predict接口,会返回训练照片中最接近的照片标签值。train(images,labels);labels这个容器包含了所有训练照片的标签。
通过返回的标签值与自己预设司机的标签进行比对,如果不一样就显示人脸识别失败。
方法2:
通过阀值设定来控制人脸识别准确度。
在创建人脸识别算法的过程中也可以将阀值传递进去
model = createEigenFaceRecognizer(0, SIMILAR_VALUE);
这样的话predict接口就不会返回有效数据。

如果创建过程中不添加。

之后可以通过对返回的predictLabel和predictConfidence进行判断是否人脸识别成功。
int predictLabel = -1;
double predictConfidence = 0.0;
model->predict(compImage, predictLabel, predictConfidence);
if (predictLabel == targetFaceIndex && predictConfidence <= SIMILAR_VALUE) {
cout<<"[cwr] Face recognition successful"<<endl;
s_faceRecognitionSuc++;
} else {
cout<<"[cwr] Face recognition fail"<<endl;
s_faceRecognitionFail++;
}
官网说明
FaceRecognizer — OpenCV 2.4.13.7 documentation https://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_api.html#facerecognizer-predict

FaceRecognizer::predict
C++: int FaceRecognizer::predict(InputArray src) const = 0
C++: void FaceRecognizer::predict(InputArray src, int& label, double& confidence) const = 0
Predicts a label and associated confidence (e.g. distance) for a given input image.
The suffix const means that prediction does not affect the internal model state, so the method can be safely called from within different threads.
The following example shows how to get a prediction from a trained model:
using namespace cv;
// Do your initialization here (create the cv::FaceRecognizer model) ...
// ...
// Read in a sample image:
Mat img = imread("person1/3.jpg", CV_LOAD_IMAGE_GRAYSCALE);
// And get a prediction from the cv::FaceRecognizer:
int predicted = model->predict(img);
Or to get a prediction and the associated confidence (e.g. distance):
using namespace cv;
// Do your initialization here (create the cv::FaceRecognizer model) ...
// ...
Mat img = imread("person1/3.jpg", CV_LOAD_IMAGE_GRAYSCALE);
// Some variables for the predicted label and associated confidence (e.g. distance):
int predicted_label = -1;
double predicted_confidence = 0.0;
// Get the prediction and associated confidence from the model
model->predict(img, predicted_label, predicted_confidence);