《Weakly-Supervised Convolutional Neural Networks for Multimodal Image Registration》
摘要:在多模态图像配准的监督学习中,最基本的挑战之一是体素级空间对应的基值的缺乏。本工作描述了一种从包含在解剖标签中的高级对应信息中推断体素级变换的方法。我们认为,这种标签获取对比体素对应关系是比通过参考图像集更可靠和实用方式。典型的感兴趣的解剖标签可能包括实体器官、血管、导管、结构边界和其他指定的特别标志。提出的端到端卷积神经网络方法旨在训练过程中对单个图像对的多个标记对应结构进行对齐从而预测位移场,而仅使用未标记的图像对作为网络输入进行推理。我们强调了该策略的通用性,使用不同类型的解剖标签用于训练,这些标签不需要在所有训练图像对上可辨别。在推断,得到的三维可形变图像配准算法实时运行,是全自动的,不需要任何解剖标签或初始化。比较了几种网络结构变体,以配准来自前列腺癌患者的T2-weight磁共振图像和3D经直肠超声图像。在交叉验证实验中,来自76名患者的108对多模态图像经过高质量的解剖标签测试,得到的标记中心的目标配准误差中值为3.6 mm,前列腺的Dice中值为0.87。
关键字:医学图像配准;图像引导介入;卷积神经网络;弱监督学习;前列腺癌。
1、引言
多模态图像配准旨在对不同成像方式产生的医学图像进行空间对齐。在许多其他医学成像应用中,这用于minimally或none-invasive图像引导处理,一个常见的策略是量化pre-procedural图像 和 intra-procedural图像 融合复杂的诊断信息,通常被介入性需求进行限制,如可移植性、可访问性、时间分辨率,有限的视野和造影计或辐射计量控制。
经典的基于强度的图像队配准方法通常是基于图像相似度的优化,这是一种图像强度对应程度的度量指标(Hill et al., 2001)。然而,在许多介入性应用中,设计一个用于临床足够鲁棒的多模态相似度指标是一个挑战。潜在的困难包括:1)不同的物理获取过程可能会在相同解剖结构不对应的成像结构之间产生统计相关性,这违反了大多数基于强度的相似性度量的基本假设之一(Zollei et al., 2003);2)在intra-procedural图像在空间和时间上是变化,部分是依赖用户(Noble, 2016),用简单的统计属性或基于信息理论的度量来总结是复杂的。3)由于术中时间的限制,不能使用更好的成像质量,因为它通常需要大量的成像或处理时间,以及使用计算密集型方法,如穷举全局优化。
基于特征的图像配准方法在自动提取特征时也面临着相似的挑战。人为选择用于配准的解剖特征依赖于用户,而且往往成本高昂,甚至在手术中不可行,但可以说,在许多intra-procedural应用中,多模态图像配准仍然是最可靠的方法(Viergever et al., 2016)。半自动化或辅助医学图像分割以支持配准是一个有前途的研究方向(Wang et al., 2017),但它还没有在快速发展的介入应用中显示出临床价值。
在这项工作中,我们着重于介入性多模态图像配准的一个应用范例,即将pre-procedural多参数磁共振(MR)图像配准到前列腺癌患者的intra-procedural经直肠超声(TRUS)图像中(Pinto et al.,2011;Rastinehad et al., 2014;Siddiqui et al., 2015)。多参数磁共振成像(Dickinson et al., 2011),包括超极化成像的最新发展(Wilson和Kurhanewicz, 2014)和基于扩散加权成像的计算方法(Panagiotaki et al., 2015),在诊断和演示方面显示出良好的结果。在包括英国在内的一些国家,这已经被推荐为标准临床路径的一部分(Vargas et al., 2016)。在intra-procedural方面,TRUS成像通常用于指导大多数靶向活检和局部治疗,但它在区分癌组织和健康环境方面的价值是有限。融合MR和TRUS图像,可以在TRUS-guided过程中对低至中等风险疾病可以准确的检测、定位和治疗(Valerio et al., 2015)。然而,像大多数其他超声引导的医疗处理,这代表了在没有鲁棒的图像相似性度量上,已被证明一个典型的例子。例如,在解剖学上不同的成像结构,如前列腺inner-outer腺分离、解理面称为外科包膜,定义在TRUS上的图像(Ethan j .Halpern 2008)和在MR图像上可以看到中心边缘的带状边界,在两种类型的图像中表现出相似的特征,因此具有很强的统计相关性。这将导致使用大多数(不是全部)建立的基于强度的相似性度量和相关的配准方法的错误对齐。(Rueckert et al., 1999)。
为了缓解配准应用中基于强度和特征的方法带来的上述问题,提出了一类模型-图像融合方法(Hu et al., 2012;Khallaghi et al.,2015; van de Ven et al., 2015; Wang et al., 2016a),其中MR图像获得的前列腺运动模型自动或半自动与腺体包膜表面对齐。这些方法有两个局限性。首先,特定对象成对配准要求从两个图像中提取相应的特征。我们之前认为,从两幅图像中唯一可以得到的前列腺共同特征是包膜表面,而根据具体情况可以找到特定的标志物以进行验证(Hu, 2013)。事实上,在上面提到的大多数算法中,腺的边界都是要匹配的感兴趣特征。其次,部分由于稀疏特征的可用性的结果,需要某种形式的运动先验来约束非刚性配准方法(De Silva et al., 2017; Hu et al., 2015,2011;Khallaghi et al., 2015;Wang et al., 2016b)。运动模型的学习高度依赖于应用,通常不能推广到其他医疗应用或相同应用的不同成像协议,如病理病例或不同手术器械的干预。
监督表示学习(Bengio et al., 2013),特别是使用卷积神经网络的方法(LeCun et al., 2013),具有优化回归网络中医学图像表示的潜力,该网络可以预测给定图像之间的空间对应关系,而无需人工图像特征工程或基于强度的相似性度量。然而,用于学习相应的体素级基准感非常缺乏,并且在大多数情况下,不可能可靠地从医学图像数据中获得。学习相似性度量的其他方法,例如(Simonovsky et al., 2016),也需要非平凡的基准标签,而且据我们所知,还没有人提出用于MR和超声图像配准。已经提出了几种方法来获取大量用于训练的伪基准变换,例如来自模拟的方法(Krebs et al., 2017; Miao et al., 2016; Sokooti et al., 2017),现有配准方法(Rohe et al., 2017)或手动刚性配准(Liao et al., 2017)。最近提出的基于机器学习的图像配准方法依赖于图像相似性驱动的无监督学习(Cao et al., 2017; de Vos et al., 2017; Wu et al., 2013;Yang et al., 2017)这意味着这些方法继承了经典的基于强度的图像配准算法的关键缺陷。
我们认为用解剖学知识进行标注的高层次的对应结构的可靠的更具有实用性。这样的标签可以用来在成对的图像中突出它们之间相同的器官和边界、病理区域,以及在两个图像中出现的其他解剖结构、形态或生理特征,也可以作为弱标签来训练对低水平体素对应的预测。此外,只有从所有图像对中不一致地获得的特定对象标记也有助于找到详细的体素对应关系,特别是从介入数据中。例如,钙化点和水基囊肿的空间分布是因人而异的(参见图1)。虽然在许多对中很容易识别,但它们大多用于验证目的(Hu et al., 2012;van de Ven et al., 2013; Wang et al., 2016a)。在这项工作中,我们介绍了一个新的框架,使用这些解剖标签和全图像体素强度作为训练数据,使一个全自动的,形变的图像配准,在推理过程中只需要未标记的图像数据。
我们的前期工作的初步结果在摘要中被展示(Hu et al., 2018)。我们总结了本文中所描述的提升:1)第2.1节给出了弱监督图像配准框架的详细方法描述;2)第2.2节描述了一种用于弱监督配准网络训练的高效多尺度Dice;3)在不使用第2.3节中提出的全局仿射子网络的情况下,提出了一种新的内存有效网络结构;4)第4节对不同的网络变化和经典的成对配准算法进行了严格的分析比较,并对结果进行了显著的改进。


2、方法
2.1 弱监督图像配准框架
给定N对训练的moving- 和fixed的图像
和fixed的图像 其中
其中 ,在
,在 对图像对中,
对图像对中, 对的moving
对的moving  和fixed
和fixed 标记对应着对应的解剖区域,
标记对应着对应的解剖区域, 。我们用神经网络训练来预测体素对应关系,用稠密位移场(dense displacement field,DDF)
。我们用神经网络训练来预测体素对应关系,用稠密位移场(dense displacement field,DDF) 表示,作为一个弱监督学习问题,在N个训练图像上,最大限度的功能函数表明期望标签相似性:
表示,作为一个弱监督学习问题,在N个训练图像上,最大限度的功能函数表明期望标签相似性:
 ---------------------------------------(1)
---------------------------------------(1)
其中,内部求和表示图像级标签相似性,在图像对标签的label-level相似性平均度量。在本文中,通过计算fixed label  和空间形变warped moving label
和空间形变warped moving label  之间的相似性计算,位移
之间的相似性计算,位移 通过参数化
通过参数化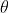 的神经网络预测,描述在图2中。网络训练旨在通过超参
的神经网络预测,描述在图2中。网络训练旨在通过超参 加权平衡最小化负功能函数和正则形变
加权平衡最小化负功能函数和正则形变 惩罚非平滑位移:
惩罚非平滑位移:
![\hat{\theta} = arg{min}_\theta[-J(x^A, x^B, l^A, l^B; \theta) + a \cdot \Omega (u)]](https://private.codecogs.com/gif.latex?%5Chat%7B%5Ctheta%7D%20%3D%20arg%7Bmin%7D_%5Ctheta%5B-J%28x%5EA%2C%20x%5EB%2C%20l%5EA%2C%20l%5EB%3B%20%5Ctheta%29%20+%20a%20%5Ccdot%20%5COmega%20%28u%29%5D) ---------------------(2)
---------------------(2)
正如引言中所提到的,我们强调这样的损失并没有包含任何基于强度的相似项,而在我们的应用中这些相似项被证明是不可靠的。在训练过程中,我们使用标准随机K-minibatch梯度下降优化(Goodfellow et al., 2016),这需要对每个minibatch中的添加梯度进行无偏估计 。通过数量可变的标签和简化实现避免minibatch梯度的非平凡的计算,我们提出构建这样一个梯度估计的两阶段采样: 在第一阶段K对图像均匀采样,然后在第二阶段对与前一阶段图像对相关的单标签对进行均匀采样。使用这种方法,每个minibatch包含同等数量的
。通过数量可变的标签和简化实现避免minibatch梯度的非平凡的计算,我们提出构建这样一个梯度估计的两阶段采样: 在第一阶段K对图像均匀采样,然后在第二阶段对与前一阶段图像对相关的单标签对进行均匀采样。使用这种方法,每个minibatch包含同等数量的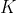 图像标签对,
图像标签对, 被评估。鉴于第一阶段采样图像对,让我们考虑
被评估。鉴于第一阶段采样图像对,让我们考虑 作为
作为 在第二阶段梯度估计的条件期望在标签对采样。与第一阶段期望
在第二阶段梯度估计的条件期望在标签对采样。与第一阶段期望![E_1[\cdot ]](https://private.codecogs.com/gif.latex?E_1%5B%5Ccdot%20%5D) 在图像对,它可以表明minibatch梯度
在图像对,它可以表明minibatch梯度 第二阶段聚类抽样无偏计算:
第二阶段聚类抽样无偏计算:
![E(\frac{\widehat{\partial J}}{\partial \theta} ) = E_1[E_2(\frac{\widehat{\partial J}}{\partial \theta} )] = E_1[E_2(\frac{1}{K}\sum_{k=1}^{K}(\frac{\widehat{\partial J_k}}{\partial \theta} ))]= E_1[\frac{1}{K}\sum_{k=1}^{K}E_2(\frac{\widehat{\partial J_k}}{\partial \theta} )]= E_1[\frac{1}{K}\sum_{k=1}^{K}\frac{\partial J_k}{\partial \theta} ]=\frac{\partial J}{\partial \theta}](https://private.codecogs.com/gif.latex?E%28%5Cfrac%7B%5Cwidehat%7B%5Cpartial%20J%7D%7D%7B%5Cpartial%20%5Ctheta%7D%20%29%20%3D%20E_1%5BE_2%28%5Cfrac%7B%5Cwidehat%7B%5Cpartial%20J%7D%7D%7B%5Cpartial%20%5Ctheta%7D%20%29%5D%20%3D%20E_1%5BE_2%28%5Cfrac%7B1%7D%7BK%7D%5Csum_%7Bk%3D1%7D%5E%7BK%7D%28%5Cfrac%7B%5Cwidehat%7B%5Cpartial%20J_k%7D%7D%7B%5Cpartial%20%5Ctheta%7D%20%29%29%5D%3D%20E_1%5B%5Cfrac%7B1%7D%7BK%7D%5Csum_%7Bk%3D1%7D%5E%7BK%7DE_2%28%5Cfrac%7B%5Cwidehat%7B%5Cpartial%20J_k%7D%7D%7B%5Cpartial%20%5Ctheta%7D%20%29%5D%3D%20E_1%5B%5Cfrac%7B1%7D%7BK%7D%5Csum_%7Bk%3D1%7D%5E%7BK%7D%5Cfrac%7B%5Cpartial%20J_k%7D%7B%5Cpartial%20%5Ctheta%7D%20%5D%3D%5Cfrac%7B%5Cpartial%20J%7D%7B%5Cpartial%20%5Ctheta%7D)
我们总结了图2所示框架的几个优点。首先,计算moving标签形变与fixed标签之间的模态无关的相似度,两者都不作为网络的输入。因此,在推理阶段,即实际配准阶段,并不需要它们。第二,不同类型的标签样本可以被喂给训练,而不需要一致的数量或类型被标记的解剖结构;而且每个图像对可能使用非常多的标签,而不会增加内存使用量。第三,moving和fixed图像是神经网络的唯一输入,不需要定义一个显式的基于强度的图像相似度度量,该度量必须针对不同的模态对进行裁剪。匹配强度模式将被训练为优化潜在标签对应的网络学习。第四,可以加入不同的正则化项,如弯曲能(Rueckert et al., 1999),L1- or位移梯度的L2范数(Fischer和Modersitzki, 2004; Kumar and Dass,2009; Vishnevskiy et al., 2017),附加为网络架构的约束。
2.2 用于测量标签相似性的多尺度Dice
在图像配准的情况下,直接使用基于Dice、Jaccard和交叉熵的二值解剖标签之间的经典重叠度量不适合测量标签相似性。例如,当两个前景对象不重叠时,它们不考虑空间信息。它们都趋近于极值,对象之间的距离不变。我们的初步工作报告使用交叉熵与基于再加权反距离变换的启发式标签平滑方法(Hu et al., 2018)。由于距离变换在每次迭代中既不能微分,也不能有效计算,因此通过插值预计算的标签映射来近似变形的标签。

在这里,我们提出了一种基于多尺度Dice的替代标签相似性度量方法。软概率Dice(Milletari et al., 2016) 在医学图像分割任务中被证明对类不平衡不那么敏感(Sudre et al., 2017). 两个标签
在医学图像分割任务中被证明对类不平衡不那么敏感(Sudre et al., 2017). 两个标签 和
和 ,
,![a_i,b_i\in[0,1]](https://private.codecogs.com/gif.latex?a_i%2Cb_i%5Cin%5B0%2C1%5D) 之间在如下给定:
之间在如下给定:
 ---------------------------------------(4)
---------------------------------------(4)
其中 是
是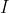 图像体素。在最小的训练彼此中给定的二值标签对
图像体素。在最小的训练彼此中给定的二值标签对
 ,为了更好的捕捉标签对之间的空间信息,提出了多尺度Dice,定义如下:
,为了更好的捕捉标签对之间的空间信息,提出了多尺度Dice,定义如下:
 --------------------------------------(5)
--------------------------------------(5)
其中 是一个标准差为
是一个标准差为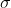 各向同性的3D高斯滤波器。在本文中,尺度
各向同性的3D高斯滤波器。在本文中,尺度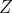 设置为7,
设置为7, 在mm。
在mm。 是否等同于用狄拉克Dirac delta函数进行滤波,意味着一个未过滤二进制标签在原来的规模也包括当平均值。图3为解剖标签的多尺度滤波示意图。所提出的基于高斯滤波的多尺度损失度量是可微的,如果需要,可以在非刚性扭曲和必要的数据扩充后实时有效地进行评估。
是否等同于用狄拉克Dirac delta函数进行滤波,意味着一个未过滤二进制标签在原来的规模也包括当平均值。图3为解剖标签的多尺度滤波示意图。所提出的基于高斯滤波的多尺度损失度量是可微的,如果需要,可以在非刚性扭曲和必要的数据扩充后实时有效地进行评估。
为了便于比较,本文提出的多尺度方法还采用了负交叉熵的分类损失:
 ------------------------------------(6)
------------------------------------(6)
在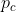 代表前景和背景之间的类概率类,
代表前景和背景之间的类概率类, 。在这种情况下,可以使用一个数值稳定的实现来裁剪极端输入概率。我们总结了在设计Eq(5)中提出的标签相似性度量时的几个技术考虑:1)它具有惩罚高可信度的二元预测的效果,类似于标签平滑正则化方法(Pereyra et al,. 2017; Szegedy et al., 2016);2)从分类的角度来看,它进一步改善了训练中基于体素样本的前景类和背景类之间的梯度平衡,减少了期望类概率之间的差异(Lawrence等,2012);3) 它提供了来自解剖标签的非饱和梯度,特别是那些体积较小的,因为在较大的尺度上高方差空间平滑;4)利用递归和可分卷积核进行计算是非常有效的。
。在这种情况下,可以使用一个数值稳定的实现来裁剪极端输入概率。我们总结了在设计Eq(5)中提出的标签相似性度量时的几个技术考虑:1)它具有惩罚高可信度的二元预测的效果,类似于标签平滑正则化方法(Pereyra et al,. 2017; Szegedy et al., 2016);2)从分类的角度来看,它进一步改善了训练中基于体素样本的前景类和背景类之间的梯度平衡,减少了期望类概率之间的差异(Lawrence等,2012);3) 它提供了来自解剖标签的非饱和梯度,特别是那些体积较小的,因为在较大的尺度上高方差空间平滑;4)利用递归和可分卷积核进行计算是非常有效的。
2.3 网络结构

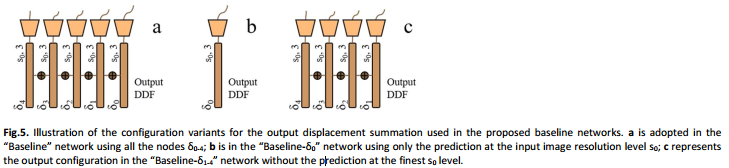
见我们的初步工作(Hu et al., 2018), 一个全局子网络预测一个仿射变换可以结合共同训练局部子网络预测 局部DDF,为了克服实际困难的传播形变的梯度规范少的支持标签数据。在这项工作中,我们描述了一个新的架构,利用一个单一的网络预测在和不同的分辨率水平上来位移求和。较低级别的位移总和提供了全局信息,与全局子网络的信息类似,但是全局子网络没有大量的内存使用。这些方法将在第3.2节中进行比较。
根据我们之前的工作(Ghavami et al., 2018)和现有的学习光流的技术(Ilg et al., 2017)将前列腺从TRUS图像中分割出来,将网络设计为4个下采样块,4个上采样块的三维卷积神经网络。见图4,网络比U-Net更紧密连接提出了图像分割(Ronneberger et al ., 2015),也有更少的内存需求,包括三种类型的先前提议基于残余综合的快捷径,1)四个求和跳过层简化整个网络在不同的分辨率水平(Yu et al., 2017), 2)八个标准残差网络捷径方式求和功能映射在两个序列卷积层(He et al., 2016),在转置-卷积层上加4个三线性加性上采样层(Wojna et al., 2017)
在计算机视觉任务(He et al., 2016; Huang et al., 2016; Leeet al., 2015; Szegedy et al.,2015)和医学图像分析(Dou et al., 2017; Garcia-Peraza-Herrera et al., 2017; Gibson et al., 2017a)。除了上面描述的完全应用的残差捷径方式外,我们还将基于求和的跳跃层引进到不同分辨率级别 的位移空间中。在Fig.4下方的视图;每一方up-sampling块延伸到一个节点的位移预测trilinear-up-sampled在
的位移空间中。在Fig.4下方的视图;每一方up-sampling块延伸到一个节点的位移预测trilinear-up-sampled在 层上被加数
层上被加数 ,额外的卷积后层添加到一个偏差项,没有batch normalisation或标准非线性激活。这些被加数,输出DDF的规模,然后添加到被加数
,额外的卷积后层添加到一个偏差项,没有batch normalisation或标准非线性激活。这些被加数,输出DDF的规模,然后添加到被加数 在输入图像分辨率级别
在输入图像分辨率级别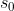 ,预测单个输出DDF。
,预测单个输出DDF。
物理参数化的全局转换,如刚性和仿射模型,对网络初始化很敏感,就像训练空间变压器网络一样(Jaderberg, 2015)。在较小程度上,预测位移的配准网络也存在同样的问题。这些求和节点的设计允许使用零均值进行随机初始化,并且允许卷积权值和偏差(在位移跳跃层上)与初始DDFs的受控大小进行小的变化,从而使扭曲的标签生成有意义的初始梯度。三线性采样提供了线性卷积之间的有界非线性激活。
所述的加性位移跳跃层计算效率更高,而且可能更容易训练,相比于在不同级别组合位移或连接扭曲的输入图像(Ilg et al., 2017;Yu et al., 2016),两者都需要重新采样。值得注意的是,所描述的四个位移跳跃层是由网络上采样级别决定的,因此与上述2.2节中描述的标签相似性度量的尺度选择无关,该节评估了相对于单个输出DDF的损失。
如图4所示,第一个特征图从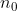 初始通道开始,向下采样块依次增加一倍通道数和减半特征图大小,向上采样正好相反。每个块由两个卷积和批量归一化(BN)层与整流线性单元(relu)组成。通过最大池(maxpool)和转置卷积(deconv)层分别实现了3D下采样和上采样,它们的步长都是2。除了第一个卷积层使用了7×7×7个核,所有的卷积层都有3×3×3个核,以保证有足够的接受域。
初始通道开始,向下采样块依次增加一倍通道数和减半特征图大小,向上采样正好相反。每个块由两个卷积和批量归一化(BN)层与整流线性单元(relu)组成。通过最大池(maxpool)和转置卷积(deconv)层分别实现了3D下采样和上采样,它们的步长都是2。除了第一个卷积层使用了7×7×7个核,所有的卷积层都有3×3×3个核,以保证有足够的接受域。
3 实验
3.1 数据
在SmartTarget®临床试验中,共获得76例患者的108对t2加权的MR和TRUS图像(Donaldson等,2017)。每个患者最多有三个图像数据集,这是由于他进入的多个程序,即活检和治疗,或根据治疗试验方案在开始和结束时获得的多个超声体(“SmartTarget:活检”,2015年,“SmartTarget治疗”,2014年)。使用标准的临床超声设备(HIVISION Preirus, Hitachi Medical Systems Europe),配备双平面(C41L47RP)经会阴探头,范围57 - 112在每个病例中,通过旋转数字超直线步进器来获得TRUS帧(D&K Technologies GmbH, Barum, Germany)获得的,所记录的相对角度覆盖了前列腺的大部分。这些旁矢状面的片随后被用来重建笛卡尔坐标下的三维体块(Hu et al., 2017)。将MR和TRUS图像重采样至各向同性体素0.8×0.8×0.8 mm3后,再用单位方差强度将其归一化为零均值。
从这些患者中,共有834对相应的解剖标志被贴上两个医学成像研究人员和研究生使用内部voxel-painting工具的原始图像数据,都验证了第二观察家包括放射学家顾问和高级研究员。作为试验方案的一部分,获取了MR图像上的前列腺切片(Donaldson et al,2017)。TRUS图像上的腺体分割是基于原始TRUS切片上的前列腺自动轮廓进行手工编辑的(Ghavami et al., 2018)。除所有病例均有完整的腺体分割外,其标志包括:顶点、基底、尿道、可见病变、腺体交界处、腺体分区分隔、输精管和精囊,以及其他患者特异性的点标志,如钙化、充满液体的囊肿(如图1、图3所示)。本研究中使用的标签对包括108(12.9%)对腺分割,213(25.5%)顶点或底部对, 214(25.7%)相对应的结构区域边界,尿道37例(4.4%),262个(31.4%)特定病例感兴趣的钙化沉积物和囊肿等,平均体积为0.39±0.21立方厘米和[0.13, 18.0] cm3范围,不包括腺分割。地标的标注过程耗时200多个小时。以二值掩模表示的解剖标签被重新分组为相关MR或TRUS图像的大小和分辨率,并被重新分组为训练(见第2.1节)和验证(见第3.3节)的交叉验证方案
3.2 实施和网络训练
上述方法在TensorFlow™(Abadi et al., 2016)中实现,使用三线性重采样模块和NiftyNet中开源代码改编的3D图像增强层(Gibson et al., 2017b)。实验报告的所有网络的重新实现都可以作为NiftyNet (NiftyNet.io)的一部分使用。在每次训练迭代之前,通过随机仿射变换对每个图像-标签对进行变换,以增加数据。每个网络都用12GB NVIDIA®Pascal™TITAN Xp通用图形处理单元(GPU) 在高性能计算集群上运行48小时。
3.2.1 建议的基线网络和变体
如果不广泛搜索和完善超参数,可能会系统地低估所报告的泛化错误,从学习开始就使用Adam优化器对经验配置的“基准”网络进行了训练。初始化学习率10-5,最小批量为4,四个全尺寸图像标签组合。形变正则化权重设置为 ,弯曲能量和多尺度Dice之间的差值,如第2节所述。未使用重量衰减。初始特征图的通道数量设置为
,弯曲能量和多尺度Dice之间的差值,如第2节所述。未使用重量衰减。初始特征图的通道数量设置为 。使用Xavier初始化程序(Glorot)为所有网络参数分配了初始值
。使用Xavier初始化程序(Glorot)为所有网络参数分配了初始值
和Bengio,2010年),但最终位移预测层允许控制初始输出,如本节2.3所述。对于本文所报告的结果,这些卷积核和偏差参数被初始化为零。我们指的是经过这些超参数训练的网络称为“基准”网络,用于与使用不同参数的网络进行比较超参数。除了比较的每个超参数外,这些配置在下面均保持不变网络。
比较了提出的“基线”网络损耗函数的两种变体,用2.2节(“Baseline- msCE”)中描述的多尺度交叉熵代替多尺度Dice,或者用位移梯度的平均L2范数代替弯曲能量(“Baseline-L^2”)。
虽然在Eq.(5)中提出的标签相似度度量的优点之一是需要实时计算时的计算效率,但是在训练之前预先计算高斯滤波标签可能会进一步加速训练。因此,我们训练了一个基线网络,该网络使用在不同尺度上预先过滤的标签图(“baseline - prefilt”),而Dice指标在训练期间直接在重新采样的多尺度标签映射上进行评估。
为了验证所提出的网络架构,“Baseline”网络仅在预测位移σ0为输入图像分辨率级别s0 ,即在分辨率级别s1-4时无位移求和δ1-4(“Baseline-δ0”,如图5b)。 这类似于我们的初步工作中提出的“ Local-Net”(Hu et al., 2018)。 此外,以前的工作建议,最好不要在最佳水平上预测正规化位移(Dosovitskiy et al., 2015)。 因此,“Baseline”网络也接受了所有位移求和的训练,除了级别为s0的那个。位移加总到输出上的水平s1-4(“Baseline-δ1-4”,如图5c所示)。 对于两个网络,下采样块和上采样块保持不变。
3.2.2 与以前的网络比较(Hu et al., 2018)
提出了如图6所示的“ Global-Net”,以使用相同的学习框架预测仿射变换详见第2.1节。提出了一个“Composite-Net”来组成“Global-Net”和“LocalNet”的输出DDF,如图7所示。 (Hu et al,. 2018)中描述了比较的“ Global-Net”和“ Composite-Net”的详细信息。由于数据集和相关的培训策略的差异,直接与先前报告的数值结果进行比较可能是不公平的。例如,本文报道的结果基于实质上更多的解剖学标记由第二个观察者(在第3.1节中进行了说明)进行了验证,但没有使用频率较低的“低置信度”标签(Hu et al., 2018)。为了直接比较不同的网络体系结构,使用与“Baseline”网络相同的多尺度Dice对“ Global-Net”和“ CompositeNet”进行了重新训练,起始学习率较小,为10-6以避免其他方式经常遇到的差异(由于输出位移对仿射参数的敏感性)。24GBNVIDIA®Quadro™P6000 GPU卡用相同的小批量大小训练“ Composite-Net”需要12GB以上GPU内存的。


3.3 交叉验证
...