协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定用户
u
u
u 和用户
v
v
v ,令
N
(
u
)
N(u)
N(u) 表示用户
u
u
u 曾经有过正反馈的物品集合,令
N
(
v
)
N(v)
N(v) 为用户
v
v
v 曾经有过正反馈的物品集合。则可以通过计算余弦相似度简单地计算
u
u
u 和
v
v
v 的兴趣相似度:
w
u
v
=
∣
N
(
u
)
∩
N
(
v
)
∣
∣
N
(
u
)
∪
N
(
v
)
∣
w_{uv} = \frac{|N(u)\cap{N(v)|}}{\sqrt{|N(u)\cup{N(v)|}}}
wuv=∣N(u)∪N(v)∣∣N(u)∩N(v)∣
如图,
A
A
A、
B
B
B、
C
C
C、
D
D
D 为用户,
a
a
a、
b
b
b、
c
c
c、
d
d
d、
e
e
e 为物品。
利用余弦相似度公式计算他们之间的兴趣相似度分别为:
w
A
B
=
∣
{
a
,
b
,
d
}
∩
{
a
,
c
}
∣
∣
{
a
,
b
,
d
}
∣
∣
{
a
,
c
}
∣
=
1
6
w_{AB} = \frac{|{\{ a,b,d\}}\cap\{{a,c}\}|}{\sqrt{|\{a,b,d\}|\,\,|\{a,c\}}|}=\frac{1}{\sqrt{6}}
wAB=∣{a,b,d}∣∣{a,c}∣∣{a,b,d}∩{a,c}∣=61
w
A
C
=
∣
{
a
,
b
,
d
}
∩
{
b
,
e
}
∣
∣
{
a
,
b
,
d
}
∣
∣
{
b
,
e
}
∣
=
1
6
w_{AC} = \frac{|{\{ a,b,d\}}\cap\{{b,e}\}|}{\sqrt{|\{a,b,d\}|\,\,|\{b,e\}}|}=\frac{1}{\sqrt{6}}
wAC=∣{a,b,d}∣∣{b,e}∣∣{a,b,d}∩{b,e}∣=61
w
A
C
=
∣
{
a
,
b
,
d
}
∩
{
c
,
d
,
e
}
∣
∣
{
a
,
b
,
d
}
∣
∣
{
c
,
d
,
e
}
∣
=
1
3
w_{AC} = \frac{|{\{ a,b,d\}}\cap\{{c,d,e}\}|}{\sqrt{|\{a,b,d\}|\,\,|\{c,d,e\}}|}=\frac{1}{3}
wAC=∣{a,b,d}∣∣{c,d,e}∣∣{a,b,d}∩{c,d,e}∣=31 但事实上,很多用户相互之间并没有对同样的物品产生过行为,即
∣
N
(
u
)
∩
N
(
v
)
∣
=
0
|N(u)\cap{N(v)}|=0
∣N(u)∩N(v)∣=0 。
因此换一种思路,我们可以首先计算出
∣
N
(
u
)
∩
N
(
v
)
∣
≠
0
|N(u)\cap{N(v)}|≠0
∣N(u)∩N(v)∣=0 的用户对
(
u
,
v
)
(u,v)
(u,v) ,然后再对这种情况除以分母
∣
N
(
u
)
∪
N
(
v
)
∣
\sqrt{{|N(u)\cup{N(v)|}}}
∣N(u)∪N(v)∣ 。
为此,可以首先建立
物
品
−
>
用
户
物品->用户
物品−>用户 的倒排表。令稀疏矩阵
C
[
u
]
[
v
]
=
∣
N
(
u
)
∩
N
(
v
)
∣
C[u][v]=|N(u)\cap{N(v)}|
C[u][v]=∣N(u)∩N(v)∣ 。因此,可以遍历倒排表中每个物品对应的用户列表,将用户列表中的两两用户对应的
C
[
u
]
[
v
]
C[u][v]
C[u][v] 同时加
1
1
1,最终就可以得到所有用户之间不为
0
0
0 的
C
[
u
]
[
v
]
C[u][v]
C[u][v]。
代码实现如下:
defUserSimilarity(train):# 建立倒排表
item_users =dict()for u, items in train.items():for i in items.keys():if i notin item_users:
item_users[i]=set()
item_users[i].add(u)# 修改相似度矩阵
C =dict()
N =dict()for i, users in item_users.items():for u in users:
N[u]+=1for V in users:if u == v:continue
C[u][v]+=1# 计算相似度矩阵
W =dict()for u, related_users in C.items():for V, cuv in related_users.items():
W[u][v]= cuv / math.sqrt(N[u]* N[v])return W
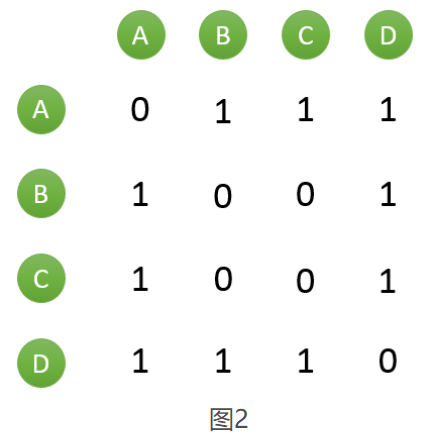
以上图的用户行为解释上述算法。首先,需要建立
物
品
−
>
用
户
物品->用户
物品−>用户 的倒排表(如图1)。然后建立一个
4
×
4
4×4
4×4 的用户相似度矩阵
W
W
W,对于物品
a
a
a,将
W
[
A
]
[
B
]
W[A][B]
W[A][B] 和
W
[
B
]
[
A
]
W[B][A]
W[B][A] 加
1
1
1,对于物品
b
b
b,将
W
[
A
]
[
C
]
W[A][C]
W[A][C] 和
W
[
C
]
[
A
]
W[C][A]
W[C][A] 加
1
1
1,以此类推(如图2)。扫描完所有物品后,我们可以得到最终的
W
W
W 矩阵。 此处
W
W
W 是余弦相似度中的分子部分,将
W
W
W 除以分母即可得到最终的用户兴趣相似度(如图3)。
得到用户之间的兴趣相似度后,
U
s
e
r
C
F
UserCF
UserCF 算法会给用户推荐和他兴趣最相似的
K
K
K 个用户喜欢的物品。以下公式度量了
U
s
e
r
C
F
UserCF
UserCF 算法中用户
u
u
u 对物品
i
i
i 的感兴趣程度:
p
(
u
,
i
)
=
∑
v
∈
S
(
u
,
K
)
∩
N
(
i
)
w
u
v
r
v
i
p(u,i)=\displaystyle \sum_{v\in{S(u,K)\cap{N(i)}}}w_{uv}r_{vi}
p(u,i)=v∈S(u,K)∩N(i)∑wuvrvi
K是
U
s
e
r
C
F
UserCF
UserCF 算法的一个重要参数
其中,
S
(
u
,
K
)
S(u,K)
S(u,K) 包含和用户
u
u
u 兴趣最接近的
K
K
K 个用户,
N
(
i
)
N(i)
N(i) 是对物品
i
i
i 有过行为的用户集合,
w
u
r
w_{ur}
wur 是用户
u
u
u 和用户
v
v
v 的兴趣相似度,
r
v
i
r_{vi}
rvi 代表用户
v
v
v 对物品
i
i
i 的兴趣,因为使用的是单一行为的隐反馈数据(否则使用评分等指标),所以所有的
r
v
i
=
1
r_{vi}=1
rvi=1。
评分可以经过归一化处理
代码如下:
defRecommend(user, train, W):
rank =dict()
interacted_items = train[user]for v, wuv insorted(W[u].items, key=itemgetter(1), reverse=True)[0:K]:for i, rvi in train[v].items:if i in interacted_items:# 过滤互动过的项目continue
rank[i]+= wuv * rvi
return rank
利用上述
U
s
e
r
C
F
UserCF
UserCF 算法,可以给上述图1、2、3的用户
A
A
A 进行推荐。选取
K
=
3
K=3
K=3,用户
A
A
A 对物品
c
c
c、
e
e
e 没有过行为,因此可以把这两个物品推荐给用户
A
A
A。相似用户则是
B
B
B、
C
C
C、
D
D
D,他们喜欢过并且
A
A
A 没有喜欢过的物品有
c
c
c、
e
e
e。根据
U
s
e
r
C
F
UserCF
UserCF 算法,用户
A
A
A 对物品
c
c
c、
e
e
e 的兴趣是:
p
(
A
,
c
)
=
w
A
B
×
1
+
w
A
D
×
1
=
1
6
+
1
9
=
0.7416
p(A,c)=w_{AB} ×1+ w_{AD} ×1= \frac{1}{\sqrt{6}}+\frac{1}{\sqrt{9}}=0.7416
p(A,c)=wAB×1+wAD×1=61+91=0.7416
p
(
A
,
e
)
=
w
A
C
×
1
+
w
A
D
×
1
=
1
6
+
1
9
=
0.7416
p(A,e)=w_{AC}×1+ w_{AD} ×1= \frac{1}{\sqrt{6}}+\frac{1}{\sqrt{9}}=0.7416
p(A,e)=wAC×1+wAD×1=61+91=0.7416
用户相似度计算的改进:
两个用户对冷门物品采取过同样的行为比热门物品更能说明他们兴趣的相似度。因此,为了防止热门物品的影响,提出如下公式计算用户的兴趣相似度:
w
u
v
=
∑
i
∈
N
(
u
)
∩
N
(
v
)
1
l
o
g
1
+
∣
N
(
i
)
∣
∣
N
(
u
)
∣
∣
N
(
v
)
∣
w_{uv}=\frac{\displaystyle \sum_{i\in{N(u)\cap{N(v)}}}\frac{1}{log1+|N(i)|}}{\sqrt{|N(u)||N(v)|}}
wuv=∣N(u)∣∣N(v)∣i∈N(u)∩N(v)∑log1+∣N(i)∣1
上述公式通过
1
l
o
g
1
+
∣
N
(
i
)
∣
\frac{1}{log1+|N(i)|}
log1+∣N(i)∣1 惩罚了用户
u
u
u 和用户
v
v
v 共同兴趣列表中热门物品对他们相似度的影响。
基于上述用户相似度公式的算法记为
U
s
e
r
−
I
I
F
User-IIF
User−IIF 算法。
代码如下:
defUserSimilarity(train):# 建立倒排表
item_users =dict()for u, items in train.items():for i in items.keys():if i notin item_users:
item_users[i]=set()
item_users[i].add(u)# 统计相似度矩阵
C =dict()
N =dict()for i, users in item_users.items():for u in users:
N[u]+=1for v in users:if u == v:continue
C[u][v]+=1/ math.1og(1+len(users))# 计算相似度矩阵
W =dict()for u, related_users in C.items():for v, cuv in related.users.items():
W[u][v]= cuv / math.sqrt(N[u]* N[v])return W