时间序列预测中的机器学习方法(二):线性回归(Linear Regression)
本文是“时间序列预测中的机器学习方法”系列文章的第二篇,如果您有兴趣,可以先阅读前面的文章:
【数据分析】利用机器学习算法进行预测分析(一):移动平均(Moving Average)
线性回归模型返回一个方程,该方程确定自变量和因变量之间的关系。
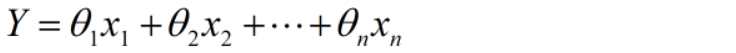
其中,x代表独立变量,θ代表的是权重。对于本文的股价预测问题,我们没有一组独立变量。我们只有日期,所以我们从日期列中提取诸如:日,月,年,星期一/星期五等特征,然后拟合线性回归模型。
本文的源数据和代码放在了我的GitHub上,需要的朋友可以自行下载:https://github.com/Beracle/02-Stock-Price-Prediction.git
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
导入数据。
df = pd.read_csv('NSE-TATAGLOBAL11.csv')
df.head()
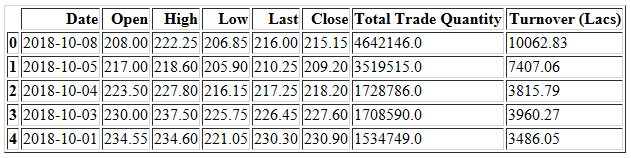
首先我们将日期设置为索引。为了不破坏原始数据,我们再定义一个新的数据集。
# setting the index as date
df['Date'] = pd.to_datetime(df.Date,format='%Y-%m-%d')
df.index = df['Date']
#creating dataframe with date and the target variable
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
我们利用add_datepart()函数对日期进行解析。没有安装fastai包可以使用pip install fastai进行安装,如果是在Jupyter环境中请使用!pip install fastai。
#create features
from fastai.tabular import add_datepart
add_datepart(new_data, 'Date')
new_data.drop('Elapsed', axis=1, inplace=True) #elapsed will be the time stamp
new_data
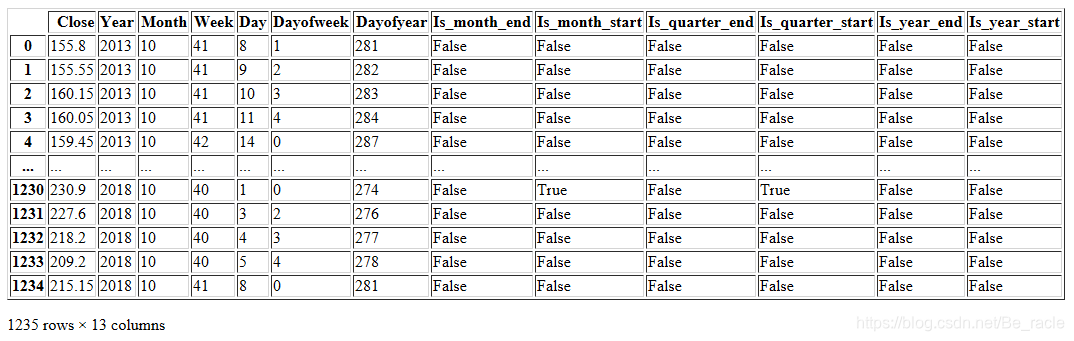
除此之外,我们可以添加自己认为与预测相关的功能。在本文中,我的假设是一周的第一天和最后几天对股票收盘价的影响可能比其他几天要大得多。因此,我创建了一个功能用来确定给定的一天是星期一/星期五,还是星期二/星期三/星期四。
如果星期几等于0或4,则列值将为1,否则为0。类似地,我们可以自由地创建多个要素。
new_data['mon_fri'] = 0
for i in range(0,len(new_data)):
if (new_data['Dayofweek'][i] == 0 or new_data['Dayofweek'][i] == 4): #如果是星期一或星期五,列值为1
new_data['mon_fri'][i] = 1
else:
new_data['mon_fri'][i] = 0
将数据分为训练集和预测集,以检查模型的性能。
#split into train and validation
train = new_data[:987]
valid = new_data[987:]
x_train = train.drop('Close', axis=1)
y_train = train['Close']
x_valid = valid.drop('Close', axis=1)
y_valid = valid['Close']
导入线性回归模型。请先通过pip或conda安装sklearn包。
#implement linear regression
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train,y_train)
通过“均方根误差”检验预测效果。
#make predictions and find the rmse
preds = model.predict(x_valid)
rmse = np.sqrt(np.mean(np.power((np.array(y_valid)-np.array(preds)),2)))
rmse

RMSE的值比我们之前用的“移动平均”方法得出的值高,这表明“线性回归”的效果较差。再通过绘图可以更直观地看出。
#plot
valid['Predictions'] = 0
valid['Predictions'] = preds
valid.index = new_data[987:].index
train.index = new_data[:987].index
plt.figure(figsize=(16,8))
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
plt.show()
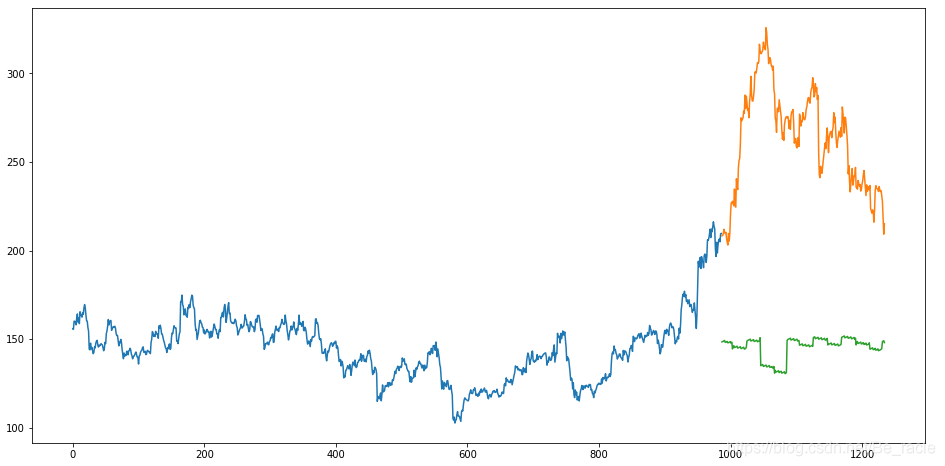
显然,用线性回归方法对本文的数据做预测也并不合适。