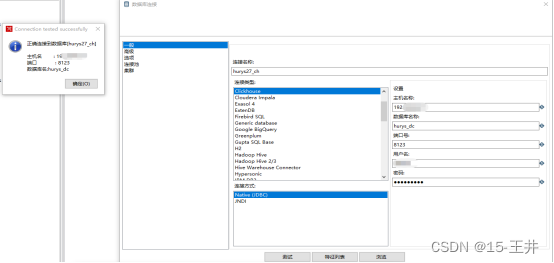
注意:低版本的kettle即使装ClickHouse驱动包后也不一定支持ClickHouse数据库连接(具体kettle从什么版本开始支持ClickHouse没测试过),只有高版本的kettle在安装ClickHouse驱动包后才支持ClickHouse数据库连接,因此这里使用的时最新的9.3.0版本
其实,kettle8.2版本也支持ClickHouse,这个亲测过
一、下载Kettle安装包和ClickHouse驱动包
1.Kettle安装包
直接在官网下载,由于kettle仅有高版本支持ClickHouse,所以我这边使用的最新的9.3.0版本
2.ClickHouse驱动包下载地址(借他人网盘链接一用)
https://pan.baidu.com/s/1iqGyXsTaQSCHEbjj7yX7AA 提取码: mvzd
二、将ClickHouse驱动包里的 clickhouse-plugins文件夹复制到 kettle 的 data-integration\plugins文件夹里
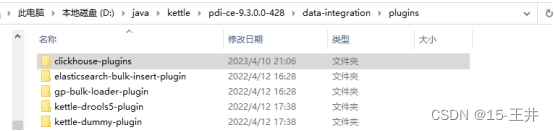
注意:clickhouse-plugins文件里就是自定义的jar包

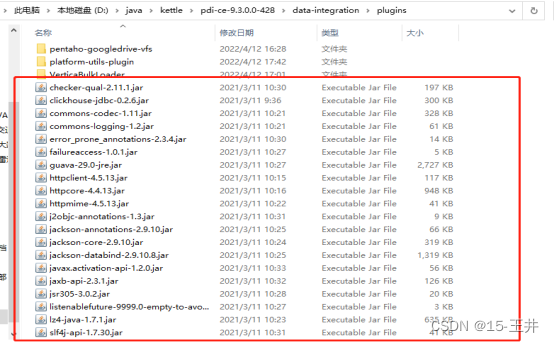
三、剪切ClickHouse驱动包里除了clickhouse-plugins文件之外的其他jar包
注意:如果不是剪切plugins文件夹里面ClickHouse的jar包,在kettle8.2版本里会影响kettle连接hive
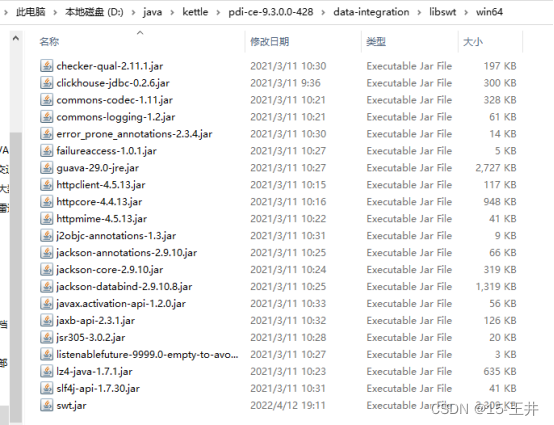
四、Jar包剪切好后粘贴到 kettle 的 data-integration\libswt\win64 目录下
五、启动kettle,连接数据库时就会发现可以连接ClickHouse数据库