题目来源:2020年研究生数学建模竞赛B题
小编第一次做研究生的竞赛题目。我的整体感受,首当其冲的是,关于题的描述很多。每一个题的页数都有好几页。
说下关于B题(汽油辛烷值建模)的思考。就B题的难易程度来说,这个题太容易了。不论从数据量,还是解题思路,与其它题相比,该题显得有些突兀。对于一个数据分析题来说,数据量只有325条。这个数据量实在是有些捉襟见肘。对于解题思路,该题的解题思路简单常规,容易下手。对于参赛的同学来讲,这是一个好消息。以下是小编在做B题时的思路或者感悟,主要针对预测辛烷值损失。
1. 数据预处理
在做预测前,数据预处理是不可或缺的。本题明确指出,通过对附件3(样本编号285号和313号样本原始数据)预处理,来替代附件1中的相应样本编号的数据。此外,题目给出了预处理的方法。其实,我们可以不去重新加工这两个样本编号的数据,认为它们是异常值,直接删除即可。这并不会影响后期的预测的。325个样本,少两个又能怎样。
到这里,我们不能认为数据预处理就结束了。还有323个样本的数据需要去除异常值的。对应这些异常值,小编不建议用均值或者其它替代,直接删除即可。小编对判断剩余的323个样本中的异常值的标准及操作如下:
(1)超过给定范围的值,直接删除其所在行;
(2)根据均值标准差,删除该范围之外的值所在行。
2. 特征选择
对应特征选择,可以用基于统计的方法(如:皮尔森系数、F值等)或者基于模型的方法(如:决策树、随机森林等)。需要注意的是,不可以用主成分分析(PCA)来做。原因是第四问要求优化操作变量,如果我们用了PCA,那么我们就无法知道所选出的特征名字了,这样的话,问题四就不好解答了。
小编用的是F值来做的,python的sklearn中有这个方法,核心代码如下:
# 用F值选择30个特征from sklearn.feature_selection import SelectKBest, f_regressionselector = SelectKBest(f_regression, k=30)selector.fit_transform(train_X, train_y)
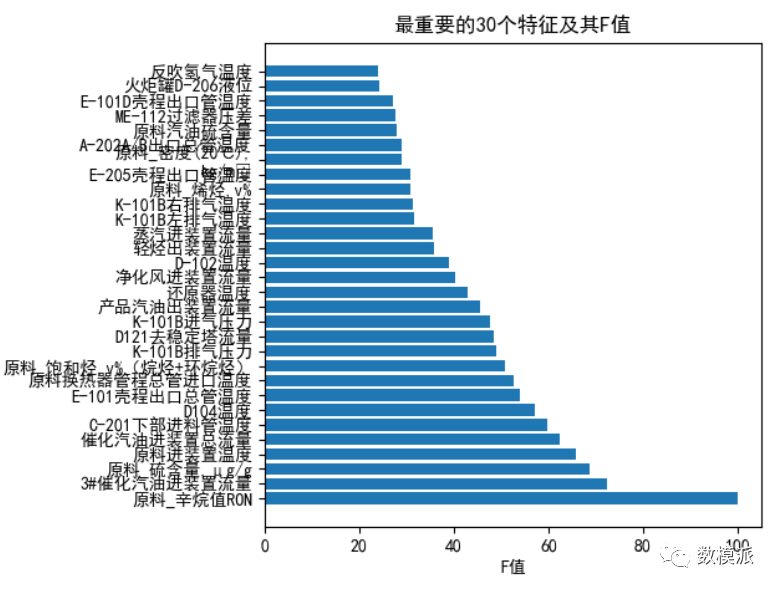
图1 特征选择
3. 辛烷值损失预测
对应预测模型,小编使用的是决策树,预测效果是理想的。对应回归问题,评价模型的指标有一般使用这两个:均方误差(MSE)和决定系数。与MSE相比,更能评价模型的优劣,它越接近1,预测模型越好。
小编在做辛烷值损失预测时,最初是把辛烷值损失值作为标签的。这样做的结果是模型的为负值。显然预测模型是极差的。后来,小编把产品的辛烷值作为标签再预测。此时,可以达到0.8,这表明预测模型是我们想要的。预测的结果如图2所示。
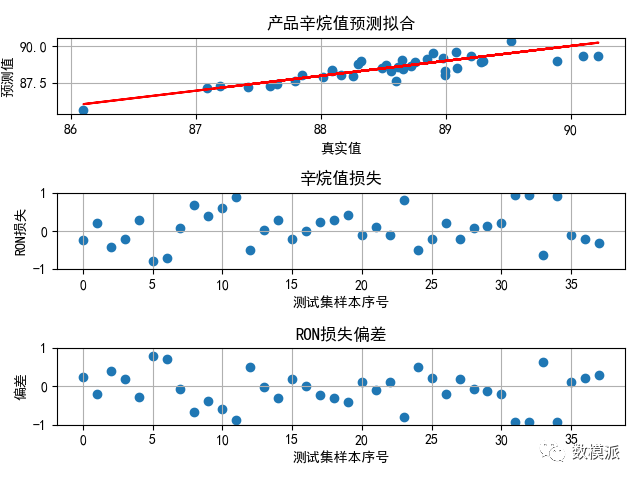
图2 产品辛烷值预测
对于回归预测的结果分析,除了给出模型的和MSE外,我们还需要给出有预测值和真实值组成的点是否分布在y=x直线附近(图2上)和预测值与真实值的偏差图(图2中)。对于图2(下),只是本题需要的。因为我们没有直接预测辛烷值损失值,而是通过原料辛烷值减去产品辛烷值得到的,所以我们需要通过图2(下)来判断下间接得到辛烷值损失值的效果是否符合我们的预期。从这三幅图来看,进一步验证了我们的模型是优秀的。
这里我想说,对于图2上,一定要画成散点,不要画出直线图。折现图即丑陋,又不直观,还不专业。
这期内容就说这么多,下期在分享小编的经验~
--end--
点击【在看】【分享】,助力小编推广~