1.简介
Hive是由Facebook开源的一款数据分析工具,主要用来进行数据提取,转换和加载(ETL)。
Hive数据存储是基于Hadoop中的HDFS,它没有自己的存储系统,也没有专门的数据存储格式,它最大的魅力在于用户只需要专注于编写SQL,Hive帮用户把SQL转换为MapReduce程序完成对数据的分析。Hive自动将用户编写的SQL转换为MapReduce程序,处理位于HDFS上的结构化数据。Hive软件本身承担的是HQL语法解析编译称为MapReduce的功能职责。
Hive优点:
-
简易性: 提供了类SQL查询语言(HQL),避免开发人员编写MapReduce任务程序代码。
-
可扩展性: 底层基于Hadoop,扩展性比较好。
-
延展性: 支持自定义函数来解决内置函数无法实现的功能。
Hive缺点:
-
Hive SQL表达能力有限: SQL无法表达迭代式算法,以及数据挖掘方面的需求。
-
计算效率一般: Hive底层默认生成MapReduce任务,计算效率一般,但稳定性高。
Hive的底层计算引擎默认是MapReduce,从Hive 3.x版本开始,官方建议使用Tez或者Spark引擎提高Hive的计算性能。
在开始接触Hive时,可以把Hive当成数据库来使用,这样便于理解。但是Hive实际上是一个数据仓库,Hive侧重的数据分析,而不是增删改查功能,它不支持修改和删除操作。
其它主流的OLAD离线引擎如Impala,Kylin,功能对比如下:
| 名称 |
计算引擎 |
计算性能 |
稳定性 |
数据规模 |
SQL支持程度 |
| Hive |
MapReduce |
中 |
高 |
TB |
HQL |
| Impala |
自研MPP |
高 |
低 |
TB |
兼容HQL |
| Kylin |
MapReduce/Spark |
高 |
高 |
TB和PB |
SQL |
2.架构分析
Hive整个体系架构都是构建在Hadoop之上的,Hive的元数据被存储在MySQL中,普通数据被存储在HDFS中,SQL语句在底层被转化为MapReduce任务,最终在YARN上执行。
架构图
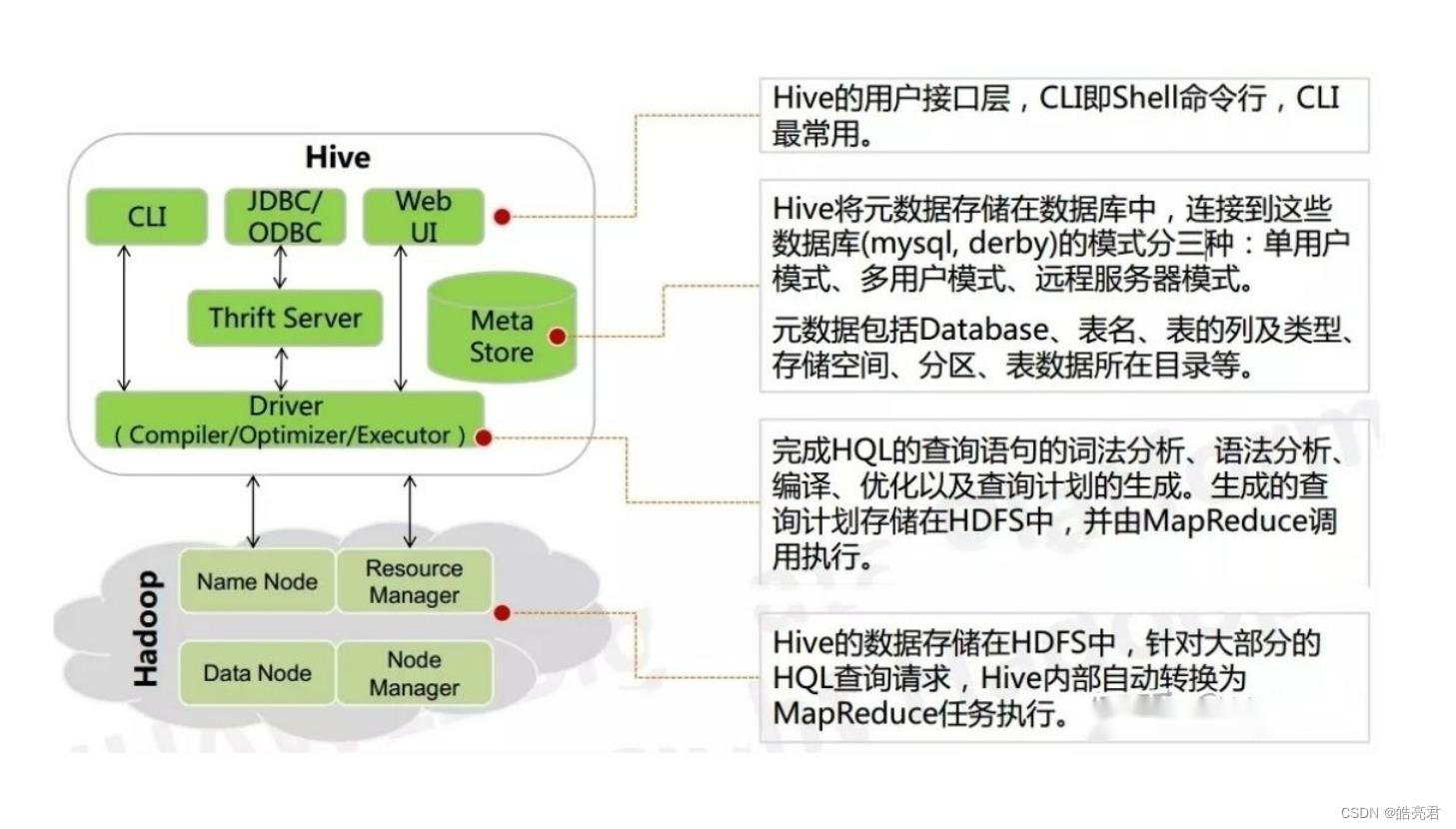
说明如下:
- 用户接口: CLI,JDBC/ODBC和Web UI,Hive支持多种客户端交互。
- Driver: 包含编译器,优化器和执行器。可以完成Hive SQL的词法分析,语法分析,编译优化,以及查询计划的生成,属于Hive中的核心组件。
- Metastore: 一个存储系统,主要负责存储Hive中的元数据。
3.环境准备
Hive相当于Hadoop集群的客户端工具,在安装使用的时候不一定需要放到Hadoop集群节点中,可以放在任意一个Hadoop集群的客户端节点上。
下载地址: 点我跳转,本文使用的版本是3.1.2,
hive和hadoop版本映射关系如下。
| hive版本 |
支持的hadoop版本 |
| 1.x |
1.x,2.x |
| 2.x |
2.x |
| 3.x |
3.x |
3.1.上传文件到服务器上面的/home/soft目录下并解压
tar -zxvf /home/soft/apache-hive-3.1.2-bin.tar.gz
3.2.进入hive配置文件目录
cd /home/soft/apache-hive-3.1.2-bin/conf
3.3.复制配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
3.3.1.修改hive-env.sh配置文件
vi hive-env.sh
#设置jdk环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.x86_64/jre
#设置hadoop环境变量
export HADOOP_HOME=/home/soft/hadoop-3.2.4
#设置hive环境变量
export HIVE_HOME=/home/soft/apache-hive-3.1.2-bin
3.3.2.修改hive-site.xml配置文件
修改一下对应配置属性中的value内容
- hive.exec.local.scratchdir: :临时数据 143行
- hive.downloaded.resources.dir: 下载的资源文件存储路径 148行
- hive.metastore.db.type: 元数据库的类型,这里我们使用mysq 443行。
- ConnectionPassword: 数据库密码 568行
- ConnectionURL: 数据库连接信息 584行
- ConnectionDriverName: 数据库的驱动,我的是mysql8用的com.mysql.cj.jdbc.Drive 1102行
- ConnectionUserName: 数据库用户名1126行
- hive.querylog.location: 查询日志存储路径 1846行
vi hive-site.xml
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive/scratchdir</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive/resources</value>
</property>
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.239.128:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=GMT%2b8&characterEncoding=utf8&connectTimeout=100 0&socketTimeout=5000&autoReconnect=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive/querylog</value>
</property>
需要3215行 hive.txn.xlock.iow属性对应的清空,要不然会报下面错误。

3.3.上传mysql驱动包到hive安装目录的lib目录下
使用mysql数据库版本和驱动包版本要对应上

3.4.修改hadoop集群配置
vi /home/soft/hadoop-3.2.4/etc/hadoop/core-site.xml
在配置文件中新增下面2个属性
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
修改完一台机器的配置,同步更新到集群上的其它节点然后重启hadoop集群
3.4.初始化hive数据库
需要提前先建好数据库。
/home/soft/apache-hive-3.1.2-bin/bin/schematool -dbType mysql -initSchema

上面报错是Hive和Hadoop使用的guava.jar版本不一样导致的,删除低版本的那个,把高本版复制过去然后重新执行上面的命令。
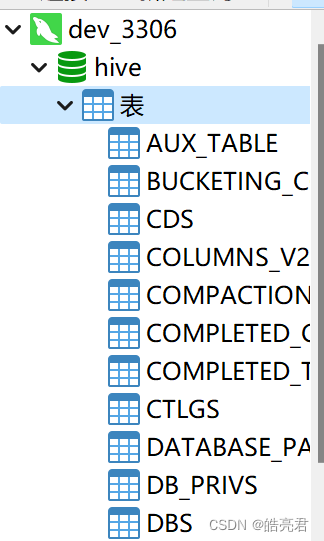
执行完可以看到命令行打印了下面语句表示初始化成功了,连接数据库可以发现hive库多了几十张表。

4.使用客户端工具操作hive
使用hive脚本进入客户端终端。
如果出现下图的异常需要关闭hdfs的安全模式。
hadoop dfsadmin -safemode leave

4.1.数据库操作
4.1.1.查看数据库列表
show databases;
4.1.2.切换数据库
切换default数据库,default是Hive的默认数据库对应hdfs上的一个目录,默认是 "/user/hive/warehouse"这个目录。
use default;
4.1.3.创建数据库
create database test;
4.1.4.删除数据库
drop database test;
4.2.DDL操作
4.2.1.创建表
create table test(id int);
查看当前数据库中所有的表名。
show tables;

查看表结构信息: desc 表名。
desc test;
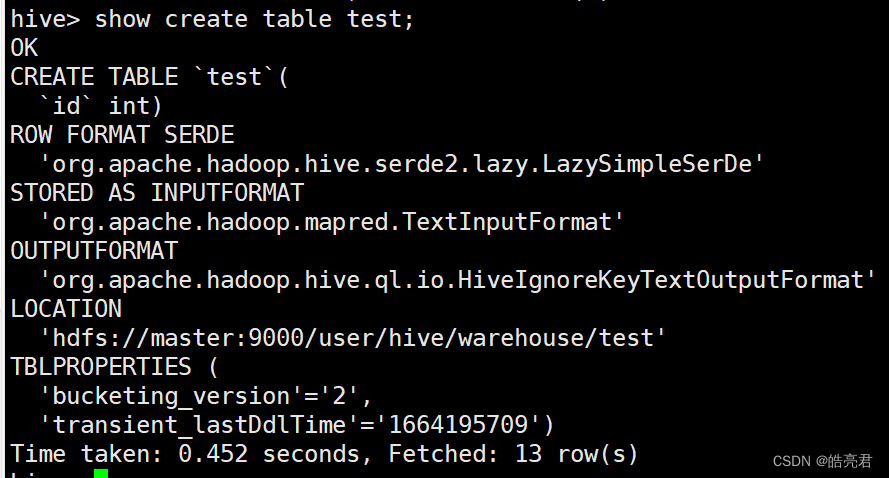
查看表的创建信息: show create table 表名。
show create table test;
4.2.2.导入数据到hive表中。
创测试数据
vi /home/soft/apache-hive-3.1.2-bin/test.data
1
2
3
4
把宿主机/home/soft/apache-hive-3.1.2-bin/data/目录下的test.data导入到test表中。
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/test.data' into table test;
查看表数据
select * from test;
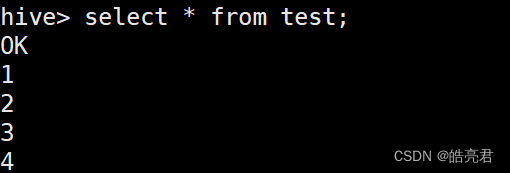
Hive也支持使用insert命令向表中插入数据,但是这种方式一般在测试时使用,在实际工作中都是使用load这种方式加载数据。
此时是全表扫描,所以Hive底层没有产生MapReduce任务。如果是复杂的SQL则会产生MapReduce任务。
4.2.3.指定列和行分隔符创建表
在实际工作中,表中会有多个列,所以创建表时需要指定对应的数据中列和行分隔符。
- fields terminated by ‘\t’ : 指定列分隔符为空格
- lines terminated by ‘\n’ : 指定行分隔符为换行(默认是\n可以不显示写)
第一列要设置为string类型,要不然导入数据后会出现NULL值。
create table student(
id string,
name string,
birthday date
) row format delimited
fields terminated by '\t';
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/student.data
11 逆天而行 1995-12-24
22 纵横天下 1996-12-24
33 穷凶极恶 1997-12-24
将student.data文件加载到student表中
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/student.data' into table student;
查看student表中的数据。
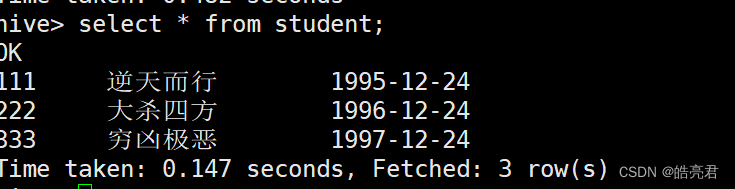
4.2.4.数据类型
基本数据类型
| 数据类型 |
包含 |
| 数值类型 |
TINYINT,SMALLINT,INT/INTEGER,BIGINT (重小到大排序) |
| 浮点类型 |
FLOAT,DOUBLE,DECIMAL |
| 日期类型 |
TIMESTAMP,DATE |
| boor类型 |
BOOLEAN (true,false) |
| 字符串类型 |
STRING,VARCHAR,CHAR (中文字符串建议使用STRING,要不然会出现乱码问题) |
基本数据类型在4.2.3中已使用过就不过多描述了。
复合数据类型
| 数据类型 |
格式 |
描述 |
| ARRAY |
ARRAY<data_type> |
存储长度可变的数组 |
| MAP |
MAP<k_type,v_type> |
类似于Java的HashMap存储多组K-V数据 |
| STRUCE |
STRUCE<col_name:data_type,…> |
存储固定数量的K-V数据 |
4.2.4.1.array数组
- 通过collection items terminated by指定元素之间的分隔符
建表语句:
创建科目表存储科目信息
create table subject(
gradeId string,
subjectList array<string>
) row format delimited
fields terminated by '\t'
collection items terminated by ',';
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/subject.data
1 数学,语文
2 数学,语文,英语
将文件加载到subject表中
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/subject.data' into table subject;
查看subject表数据。
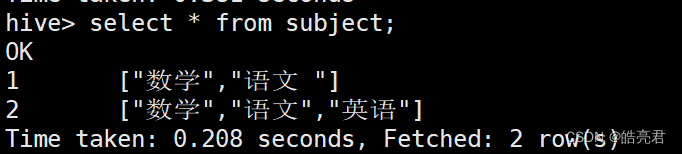
查看第3个科目名称,ARRAY数据类型的下标是从0开始,如果指定下标数据不存在则会返回NULL

4.2.4.2.map哈希表
- 在建表语句中指定map的K-V数据类型
- 通过collection items terminated by指定元素之间的分隔符
- 通过map keys terminated by指定K-V之间的分割符
创建成绩表存储学生成绩
建表语句:
create table studentScore(
name string,
scores map<string,int>
) row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/studentScore.data
zhangsan chinese:90,math:90
lijunming chinese:95,math:100,english:99
将文件加载到studentScore表中
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/studentScore.data' into table studentScore;
查看所有数据

查看学生的语文和数学成绩
select name,scores['chinese'],scores['math'] from studentScore;

4.2.4.3.struct结构化数据
类似于关系型数据mysql中的一行数据。
- 在建表的时候需要指定struct类型的字段中需要存储固定数量的K-V类型元素名称和类型。
- 通过collection items terminated by指定元素之间的分隔符
- 在数据存储的时候只需要存储元素的V即可
创建成绩表存储学生语文和数学成绩。
建表语句:
create table studentScore2(
name string,
scores struct<chinese:int,math:int>
)row format delimited
fields terminated by '\t'
collection items terminated by ',';
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/studentScore2.data
zhangsan 90,90
lijunming 95,100
将文件加载到studentScore2表中
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/studentScore2.data' into table studentScore2;
查看所有数据
select * from studentScore2;
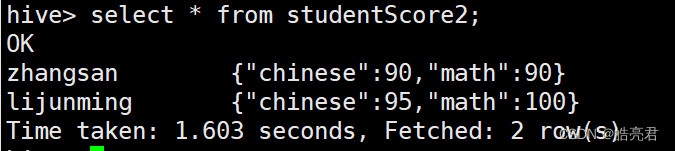
查看学生的数学成绩
select name,scores.math from studentScore2;

4.3.表的类型
4.3.1.内部表
- 内部表也称受控表,它是Hive默认表类型,表数据默认存储在HDFS的/user/hive/warehouse目录下。
- 在向内部表中加载数据时,通过load命令加载数据时,数据会被移动到warehouse目录下
4.3.2.外部表
- 建表语句中包含External关键字是外部表。
- 外部表的定义和表中数据的生命周期互相不约束,表中数据只是表对HDFS上的某个目录引用,在删除表的时候,只是删除引用,表中的数据依旧还存在HDFS上。
- 通过external声明创建的是外部表
- 通过location 设置外部表存储在HDFS上的目录
建表语句:
create external table external_table(
key string
) location '/data/external';
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/external_table.data
test
admin
将文件中数据加载到external_table表中
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/external_table.data' into table external_table;
查看表中数据,然后删除表,通过show tables查看到表确定在hive中删除了。
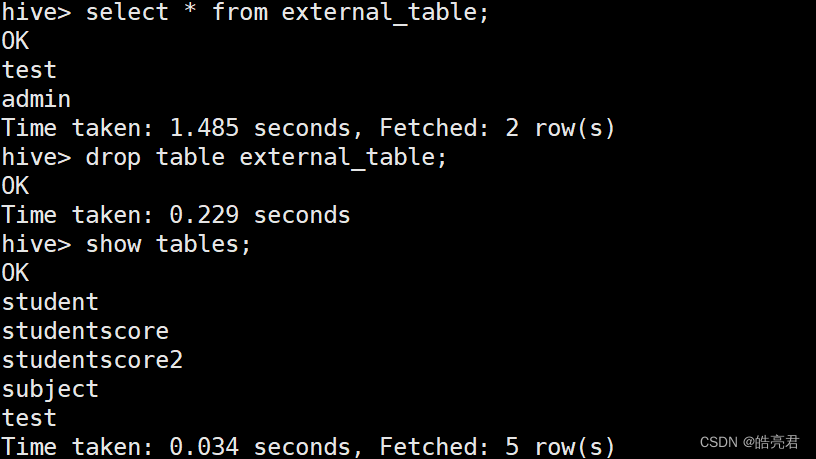
在hdfs中查看/data/external目录可以看到数据还在。

在实际工作中Hive中的表95%以上的数据都是外部表,都是通过Flume这种日志采集工具提取采集到HDFS中,此时使用Hive的外部表可以直接关联里面的数据。
4.3.3.分区表
分区表在实际应用场景比较场景。
假设企业中的Web服务器每天产生一个日志文件,Flume把日志数据采集到HDFS中的同一个目录下,如果要查询某一天的数据,则Hive默认会对所有文件都扫描一遍,然后过滤出需要查询的那一天数据,类似于mysql中sql查询全表扫描不走索引,数据量小影响不大,当数据量级别上去后效率特别低。
我们可以让Hive查询时根据要查询的日期直接定位对应目录,如果分区是根据天作为分区字段,这样根据条件查询效率提升了(日志文件个数N-1)倍。
分区表可以细分为内部分区表和外部分区表,主要区别在于建表语句中的external关键字。
外部分区表使用
在实际工作中,99%的表都是外部分区表。
- 通过partitioned by指定分区的字段和类型(不需要显示在建表语句中声明)
- 通过load加载数据的时候需要通过 **partition(分区字段=‘分区名称’)**指定分区
- 查询的sql中指定where条件 分区字段=‘分区名称’
建表语句:
create external table external_par(
id string,
name string
)partitioned by(dt string)
row format delimited
fields terminated by '\t'
location '/data/external_par/';
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/external_par.data
1 test
2 admin
将文件中数据加载到external_par中分区中
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/external_par.data' into table external_par partition(dt='2022-09-27');
查询时候根据分区名称查询
select * from external_par where dt='2022-09-27';

在实际工作中会遇到数据已经通过Flume采集到HDFS的指定目录下了,如果不关联是查询不到数据的。此时需要讲HDFS中数据和Hive中的外部分区表进行关联。
关联分区命令如下
alter external_par add partition(dt='2022-09-26') location '/data/external_par/dt=2022-09-26'
4.3.4.桶表
桶表是对数据进行哈希取值,然后放到不同的文件中存储,在物理层面每个桶和表分区的概念一样。
例如针对中国人口,有些省份人口相对较少,如果使用分区表就不会导致数据分配不均匀。这样查询的效率会因为数据倾斜问题导致计算效率低,应该使用桶表解决这个应用场景。
应用场景不多,就不再此文描述了。
4.4.视图
Hive也有类似于mysql的视图功能,主要目的也是用来降低查询的复杂度。
创建视图:
create view sv as select id,name from student;
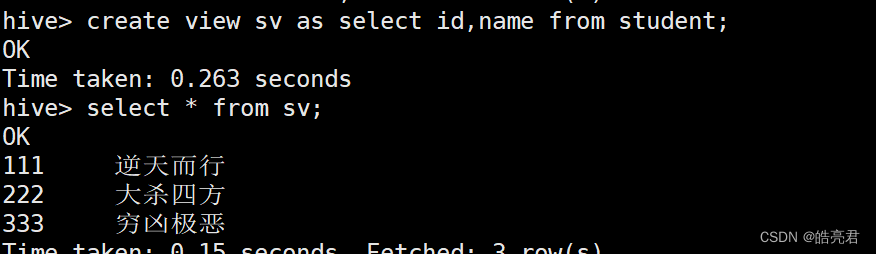
查看视图结构和查看表结构一样都是使用desc命令
desc sv;

4.5.高级函数
查看hive支持的函数
show functions;
mysql中支持的函数Hive大部分都支持,在Hive中可以直接使用,并且Hive的函数比MySQL还要多。

下面以分组排序取Top这个场景需要使用Hive以下两个函数。
- ROW_NUMBER():对数据编号,编号从1开始。
- OVER(): 把数据划分到一个窗口内,然后对窗口内的数据进行分区和排序和操作。
示例需求: 统计学生考试语文和数学考试成绩中前3名学生信息。
测试数据如下:
vi /home/soft/apache-hive-3.1.2-bin/data/student_score_order.data
ljm chinese 90
ljm math 100
zs chinese 100
zs math 90
ls chinese 95
ls math 95
ww chinese 80
ww math 80
建表语句如下:
create table student_score(
name string,
sub string,
score int
)row format delimited
fields terminated by '\t';
向表中加载数据
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/student_score.data' into table student_score;
统计单科排名前3的学生
select * from(
select *,row_number() over(partition by sub order by score desc) as num from student_score
) s where s.num<=3;
结果如下,由于查询条件涉及高级函数所以能看到下图圈出的日志打印了MapReduce任务日志。

| 排序函数名称 |
描述 |
| row_number() |
正常排序,上图使用的此函数 |
| rank() |
跳跃排序,当出现两条记录行号是一样的,下一个行号递增N(重复次数),此时如果有,两个100分会出现两个并列第1名,没有第2名,下一个是第3名。 |
| dense_rank() |
当出现两条记录行号是一样的,下一个行号递增1,此时如果有两个100分会出现两个并列第1名,下一个是第2名。 |
4.6.排序语句
在mysql中只有order by 语句,在Hive中有以下几种
| 关键字 |
描述 |
| order by |
和mysql一样对查询结果进行全局排序。 |
| sort by |
可以实现局部排序。对于多个Reduce任务,只保证每个Reducer任务内部数据是有序的。 |
| distribute by |
分区(控制Map任务的数据输出如何划分到Reduce中),只会进行分区不会排序,经常和sort by组合使用以实现先分区后排序的功能。 |
| cluster by |
sort by + distribute by组合 |
添加测试数据
vi /home/soft/apache-hive-3.1.2-bin/data/numbers.data
1
3
1
4
5
4
2
6
创建表结构
create table numbers(
number int
);
导入测试数据
load data local inpath '/home/soft/apache-hive-3.1.2-bin/data/numbers.data' into table numbers;
4.6.1.动态设置reduce的任务数量为2然后测试sort by
set mapreduce.job.reduces=2;
select number from numbers sort by number;
执行结果可以看见数据已经局部排序了。

4.6.2.动态设置reduce的任务数量为2然后测试distribute by
set mapreduce.job.reduces=2;
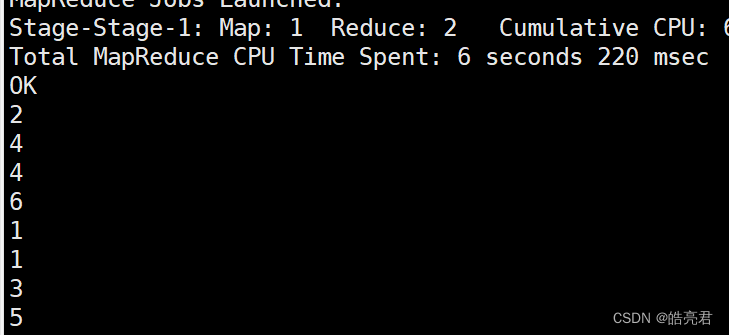
select number from numbers distribute by number;
执行结果可以看见数据已经分组了但是没排序。

4.6.3.动态设置reduce的任务数量为2然后测试distribute by + sort by
默认是升序,可以使用desc设置降序
set mapreduce.job.reduces=2;
select number from numbers distribute by number sort by number desc;
重执行结果可以看出数据已经分区并且降序了。

4.6.4.动态设置reduce的任务数量为2然后测试cluster by
cluster by只能支持升序,如果要是有降序指定通过4.6.3.组合命令
set mapreduce.job.reduces=2;
select number from numbers cluster by number;
重执行结果可以看出数据和4.6.3效果是一样的,唯一区别是4.6.3使用的是降序。
【Hadoop生态圈】其它文章如下,后续会继续更新。