项目介绍
爬取2017年全国各省份的汽车销量情况(由于数据源的问题,不包含台湾省的数据情况),并且利用 pyecharts 可视化中国地图展示。
数据爬取网页链接:
http://www.daas-auto.com/newsDe/892.html
pyecharts 是Python制图一个功能非常强大的第三方库,不仅可以做简单的图表,还可以做世界地图,数据大屏等等,有兴趣的可以看一下官方文档。
https://pyecharts.org/#/zh-cn/intro
网页详情
查看页面情况,由于页面没有采用JavaScript编写,因此我们直接就采用requests库进行内容爬取。

老规矩,F12 查看网页源码情况:

在Network选择框中获取网页的请求头:
headers_ = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51"}
直接通过selecter选择器爬取想要的内容:
province = bs.select(" table > tbody > tr > td:nth-child(1)")
values = bs.select("table > tbody > tr > td:nth-child(2)")
代码
爬取数据代码
import requests
import re
from bs4 import BeautifulSoup
headers_ = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51"}
url = 'http://www.daas-auto.com/newsDe/892.html'
html = requests.get(url,headers = headers_)
bs = BeautifulSoup(html.text,"html.parser")
# print(bs)
province = bs.select(" table > tbody > tr > td:nth-child(1)")
values = bs.select("table > tbody > tr > td:nth-child(2)")
data = []
for pro,val in zip(province,values):
d = []
w = pro.text
#由于Map可视化中国地图中,对于各个省份的命名是有固定的格式的,
#因此我们要对爬取的省份名称进行处理一下,详细情况可以看上文提到的pyecharts官方文档
if w == "省份":
w = w.replace("省份","地区")
else:
w = w.replace("省","")
w = w.replace("市","")
w = w.replace("自治区","")
w = w.replace("广西壮族","广西")
w = w.replace("新疆维吾尔","新疆")
w = w.replace("宁夏回族","宁夏")
d.append(w)
if val.text != '销量(辆)':
d.append(int(val.text))
else:
d.append(val.text)
print(d)
data.append(d)
将爬取的数据保存到文档中
import xlwt #进行excel操作
#创建一个Excel数据表
word = xlwt.Workbook(encoding = 'utf-8', style_compression=0)
# 添加sheet表格,并允许重复修改
sheet = word.add_sheet('销量数据', cell_overwrite_ok=True)
for i in range(0, len(data)):
d = data[i]
for j in range(0, 2): #i,j均是从0开始的
sheet.write(i, j, d[j]) #第i+1行第j+1列,填入数据d[j]
word.save('销量数据.xls')
print("数据保存成功!")
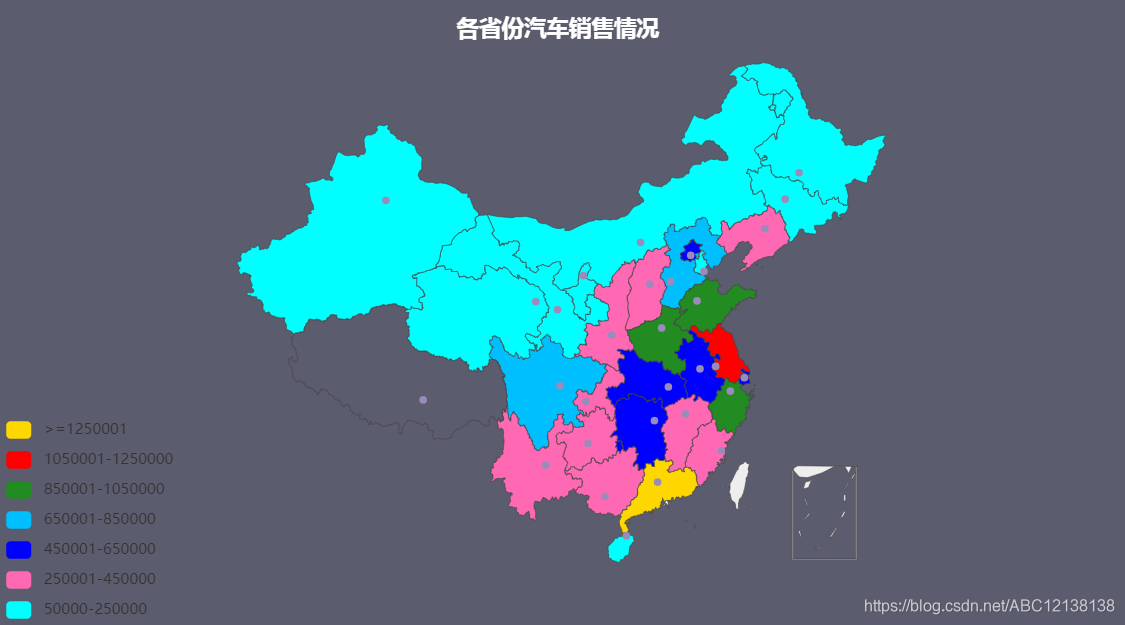
中国地图可视化
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
import pandas as pd
data = pd.read_excel("销量数据.xls")
# print(data['地区'])
# print(data['销量(辆)'])
datas = [(i, j) for i, j in zip(data['地区'], data['销量(辆)'])]
# 实例化一个Map对象
map_ = Map(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION))
# 地图 maptype="china"选择中国地图,data_pair=datas数据源
map_.add(series_name="销售数量", data_pair=datas, maptype="china")
# 设置系列配置项
map_.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不显示label
# 设置全局配置项
map_.set_global_opts(
title_opts=opts.TitleOpts(title="各省份汽车销售情况",
pos_left='40%',
pos_top='10'), # 调整title位置
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(
max_=1450000,
min_=50000,
is_piecewise=True,
pieces=[{"max": 250000, "min": 50000, "label": "50000-250000", "color": "#00FFFF"},
{"max": 450000, "min": 250001, "label": "250001-450000", "color": "#FF69B4"},
{"max": 650000, "min": 450001, "label": "450001-650000", "color": "#0000FF"},
{"max": 850000, "min": 650001, "label": "650001-850000", "color": "#00BFFF"},
{"max": 1050000, "min": 850001, "label": "850001-1050000", "color": "#228B22"},
{"max": 1250000, "min": 1050001, "label": "1050001-1250000", "color": "#FF0000"},
{"max": 1450000, "min": 1250001, "label": ">=1250001", "color": "#FFD700"}
] # 分段 添加图例注释和颜色
)
)
# 渲染在网页上 有交互性
map_.render('各省份汽车销售情况.html')
map_.render_notebook()
运行效果

上个星期都没有更新博文,五一假期后的第一天继续努力!
结束,拜拜!!!