版本更新知识:ES--删除映射类型-爱码网
1、Index索引,包含了一堆有相似数据结构的文档数据,一个索引包含很多document,一个索引就代表一类相似或者相同的document。索引简单来说就相对于关系型数据库的库。
2、Type类型,每个索引里可以有一个或者多个type,type是index的一个逻辑分类,例如建立电影的索引,电影可以分为多个type:科幻type、喜剧 type、魔幻type等等。每个type下的document中的field可能是不一样的。类型简单来说就相对于关系型数据库的表。
3、Document文档是信息的基本单元,一个document相当于一条数据,是可以被索引的,文档是以JSON的格式表现的。文档相对于关系型数据库的行。
4、Field字段,document由多个field组成,不同类型的document里面同名的field一定具有相同的类型。
5、setting设置,可以理解为管理这个index的一些重要属性的,比如分片(shard)和副本(replica),它决定这个索引库最终的配置形态。初学者的话,可以只用管这三个配置参数即可:
-
number_of_shards: 是设置的分片数,设置之后无法更改!
-
refresh_interval: 是设置es缓存的刷新时间,如果写入较为频繁,但是查询对实时性要求不那么高的话,可以设置高一些来提升性能。可以更改
-
number_of_replicas : 是设置该索引库的副本数,建议设置为1以上。
6、mapping映射,可以理解为关系型数据库的表结构,指定字段的类型。初学者可以先只用关心text、keyword、byte、short、integer、long、float、double、boolean、date这几个字段,其中text和keyword都是string类型,选择区分很简单,需要进行分词用text,不需要并且进行排序或聚合的可以用keyword。
7、shard分片,分片是一个单一的Lucene实例。这个是由Elasticsearch管理的比较底层的功能。索引是指向主分片和副本分片的逻辑空间。对于使用,只需要指定分片的数量,其他不需要做过多的事情。在开发使用的过程中,我们对应的对象都是索引,Elasticsearch会自动管理集群中所有的分片,当发生故障的时候,一个Elasticsearch会把分片移动到不同的节点或者添加新的节点。
-
主分片(primary shard):每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
-
副本分片(replica shard):每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的:
1、增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。 2、提高性能:当查询的时候可以到主分片或者副本分片中进行查询。默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
8、分片设置很重要!一个index指定了分片之后是无法修改的,因此在设置分片的时候一定要事前做好规划
9、ES的内存设置
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
-
当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给lucene。
-
当机器内存大于64G时,遵循以下原则:
a. 如果主要的使用场景是全文检索, 那么建议给ES Heap分配 4~32G的内存即可;其它内存留给操作系统, 供lucene使用(segments cache), 以提供更快的查询性能。
b. 如果主要的使用场景是聚合或排序, 并且大多数是numerics, dates, geo_points 以及not_analyzed的字符类型, 建议分配给ES Heap分配 4~32G的内存即可,其它内存留给操作系统,供lucene使用(doc values cache),提供快速的基于文档的聚类、排序性能。
c. 果使用场景是聚合或排序,并且都是基于analyzed 字符数据,这时需要更多的 heap size, 建议机器上运行多ES实例,每个实例保持不超过50%的ES heap设置(但不超过32G,堆内存设置32G以下时,JVM使用对象指标压缩技巧节省空间),50%以上留给lucene。
10、查询优化
-
query_string 或 multi_match的查询字段越多, 查询越慢。可以在mapping阶段,利用copy_to属性将多字段的值索引到一个新字段,multi_match时,用新的字段查询。
-
日期字段的查询, 尤其是用now 的查询实际上是不存在缓存的,因此, 可以从业务的角度来考虑是否一定要用now, 毕竟利用query cache 是能够大大提高查询效率的。
-
查询结果集的大小不能随意设置成大得离谱的值, 如query.setSize不能设置成 Integer.MAX_VALUE, 因为ES内部需要建立一个数据结构来放指定大小的结果集数据。
-
尽量避免使用script,万不得已需要使用的话,选择painless & experssions 引擎。一旦使用script查询,一定要注意控制返回,千万不要有死循环,因为ES没有脚本运行的超时控制,只要当前的脚本没执行完,该查询会一直阻塞。
11、正排索引与倒排索引
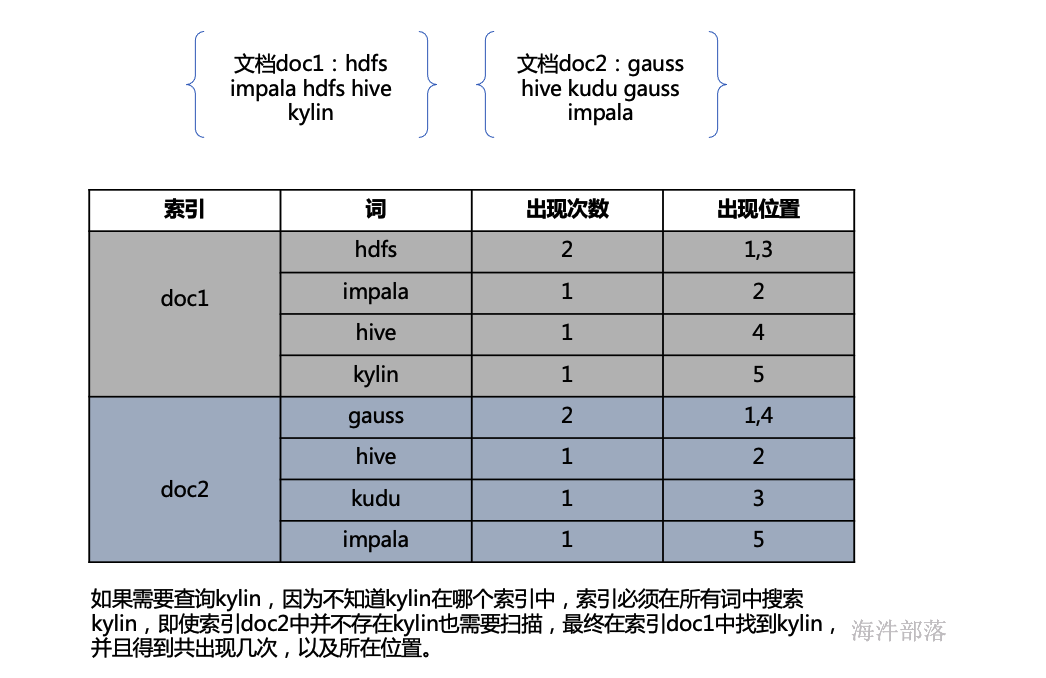
12、 什么是动态映射
动态映射时Elasticsearch的一个重要特性: 不需要提前创建iindex、定义mapping信息和type类型, 你可以 直接向ES中插入文档数据时, ES会根据每个新field可能的数据类型, 自动为其配置type等mapping信息, 这个过程就是动态映射(dynamic mapping),说明: 动态映射虽然方便, 可并不直观, 为了个性化自定义相关设置, 可以在添加文档之前, 先创建index和type, 并配置type对应的mapping, 以取代动态映射.
true | false boolean
1234 long
123.4 float
2018-10-10 date
"hello world" text
12345
13、开启dynamic mapping动态映射策略
策略 功能说明
true 开启 —— 遇到陌生字段时, 进行动态映射
false 关闭 —— 忽略遇到的陌生字段
strict 遇到陌生字段时, 作报错处理
映射策略设置在properties同一层,默认最外层的dynamic是开启的,如果内层的properties没有定义dynamic,默认用外层的。
14、开启dynamic mapping动态映射策略
对于date类型的数据, Elasticsearch有其默认的识别策略, 比如"yyyy-MM-dd". 存在这种情况:
① 第一次添加文档时, 某个field是类似"2018-01-01"的值, 其类型就动态映射成date; ② 后期再次添加文档, 该field是类似"hello world"的值, ES就会因为类型不匹配而报错.
为解决这一问题, 可以手动关闭某个type的date_detection; 如果不需要关闭, 建议手动指定这个field为date类型. 示例如下:
PUT blog_user/_mapping/_doc
{
"date_detection": false
}
15、在type中自定义动态映射模板
(1) 在type中定义动态映射模板(dynamic mapping template) —— 把所有的String类型映射成text和keyword类型:
先删除已有的blog_user索引: DELETE blog_user, 再执行下述命令:
PUT blog_user
{
"mappings": {
"_doc": {
"dynamic_templates": [
{
"en": { // 动态模板的名称
"match": "*_en", // 匹配名为"*_en"的field
"match_mapping_type": "string",
"mapping": {
"type": "text", // 把所有的string类型, 映射成text类型
"analyzer": "english", // 使用english分词器
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
]
}
}
}
这里的match_mapping_type的类型支持 [object, string, long, double, boolean, date, binary], 若使用text将抛出错误信息。
16、[过期]在index中自定义默认映射模板 _default mapping - 默认映射模板是类似于全局变量的存在, 对当前配置的索引起作用.
默认映射模板在Elasticsearch 6.x版本中已经不再支持, 因为6.0版本开始, 每个索引只能有一个类型, 因此默认模板没有存在的意义了.
17、ES分词器,之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了。
ES内置了多种分词器,standard分词器是默认分词器,按词拆分、小写;simple分词器:按非字母拆分,小写,过滤非字母;wihtespace分词器:按空格分词。IK分词器是推荐较多的中文分词器,支持粗力度和细粒度分词,需要安装插件使用。
-
如果未安装ik分词器,那么,你如果写 "analyzer": "ik_max_word",那么程序就会报错,因为你没有安装ik分词器
-
如果你安装了ik分词器之后,你不指定分词器,不加上 "analyzer": "ik_max_word" 这句话,那么其分词效果跟你没有安装ik分词器是一致的,也是分词成每个汉字,和添加字段类型一个级别,每个字段都可以定义。
-
一些热词,自定义的词,ik是不会收录的,这时候我们需要自定义扩展。 比如:王者荣耀。 分词的效果如下,显然是不满足我们需求的,这时候就需要自定义。
18、ES生命周期 链接:ES索引的生命周期管理_没文化取名很难的博客-CSDN博客_es生命周期管理
ES索引的生命周期管理 介绍 ES可用于索引日志类数据,在此场景下,数据是源源不断地被写入到索引中。为了使索引的文档不会过多,查询的性能更好,我们希望索引可以根据大小、文档数量或索引已创建时长等指标进行自动回滚,可以自定义将超过一定时间的数据进行自动删除。ES为我们提供了索引的生命周期管理来帮助处理此场景下的问题。
索引的生命周期分为四个阶段:HOT->WARM->COLD->DELETE。
HOT为必须的阶段外,其他为非必须阶段,可以任意选择配置。在日志类场景下不需要WARN和COLD阶段,下文只配置了HOT与DELETE阶段。
PUT _ilm/policy/datastream_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_docs" : 1
}
}
},
"delete": {
"min_age": "30s",
"actions": {
"delete": {}
}
}
}
}
}
创建一个名为“datastream_policy“的策略,包含HOT和DELETE阶段。
另外,hot->actions->rollover还支持其他维度的控制,比如:
"max_size": "50GB"//最大容量
"max_age": "30d"//最大天数
配合配置索引模板使用:
PUT _template/datastream_template
{
"index_patterns": ["datastream-*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "datastream_policy", //引用周期策略名
"index.lifecycle.rollover_alias": "datastream"
}
}