作 者:崔家华
编 辑:李文臣
四、使用Sklearn构建Logistic回归分类器
开始新一轮的征程,让我们看下Sklearn的Logistic回归分类器!
官方英文文档地址:http://scikit-learn.org/dev/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
sklearn.linear_model模块提供了很多模型供我们使用,比如Logistic回归、Lasso回归、贝叶斯脊回归等,可见需要学习的东西还有很多很多。本篇文章,我们使用LogisticRegressioin。

1、LogisticRegression
让我们先看下LogisticRegression这个函数,一共有14个参数:

参数说明如下:
-
penalty:惩罚项,str类型,可选参数为l1和l2,默认为l2。用于指定惩罚项中使用的规范。newton-cg、sag和lbfgs求解算法只支持L2规范。L1G规范假设的是模型的参数满足拉普拉斯分布,L2假设的模型参数满足高斯分布,所谓的范式就是加上对参数的约束,使得模型更不会过拟合(overfit),但是如果要说是不是加了约束就会好,这个没有人能回答,只能说,加约束的情况下,理论上应该可以获得泛化能力更强的结果。
-
dual:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
-
tol:停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解。
-
c:正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
-
fit_intercept:是否存在截距或偏差,bool类型,默认为True。
-
intercept_scaling:仅在正则化项为"liblinear",且fit_intercept设置为True时有用。float类型,默认为1。
-
class_weight:用于标示分类模型中各种类型的权重,可以是一个字典或者'balanced'字符串,默认为不输入,也就是不考虑权重,即为None。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。举个例子,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。
-
那么class_weight有什么作用呢?
-
在分类模型中,我们经常会遇到两类问题:
-
1.第一种是误分类的代价很高。比如对合法用户和非法用户进行分类,将非法用户分类为合法用户的代价很高,我们宁愿将合法用户分类为非法用户,这时可以人工再甄别,但是却不愿将非法用户分类为合法用户。这时,我们可以适当提高非法用户的权重。
-
2. 第二种是样本是高度失衡的,比如我们有合法用户和非法用户的二元样本数据10000条,里面合法用户有9995条,非法用户只有5条,如果我们不考虑权重,则我们可以将所有的测试集都预测为合法用户,这样预测准确率理论上有99.95%,但是却没有任何意义。这时,我们可以选择balanced,让类库自动提高非法用户样本的权重。提高了某种分类的权重,相比不考虑权重,会有更多的样本分类划分到高权重的类别,从而可以解决上面两类问题。
-
random_state:随机数种子,int类型,可选参数,默认为无,仅在正则化优化算法为sag,liblinear时有用。
-
solver:优化算法选择参数,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear。solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
-
liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
-
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
-
newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
-
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
-
saga:线性收敛的随机优化算法的的变重。
-
总结:
-
liblinear适用于小数据集,而sag和saga适用于大数据集因为速度更快。
-
对于多分类问题,只有newton-cg,sag,saga和lbfgs能够处理多项损失,而liblinear受限于一对剩余(OvR)。啥意思,就是用liblinear的时候,如果是多分类问题,得先把一种类别作为一个类别,剩余的所有类别作为另外一个类别。一次类推,遍历所有类别,进行分类。
-
newton-cg,sag和lbfgs这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear和saga通吃L1正则化和L2正则化。
-
同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
-
从上面的描述,大家可能觉得,既然newton-cg, lbfgs和sag这么多限制,如果不是大样本,我们选择liblinear不就行了嘛!错,因为liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。郁闷的是liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。
-
max_iter:算法收敛最大迭代次数,int类型,默认为10。仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。
-
multi_class:分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
-
OvR和MvM有什么不同?
-
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
-
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
-
可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
-
verbose:日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
-
warm_start:热启动参数,bool类型。默认为False。如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。
-
n_jobs:并行数。int类型,默认为1。1的时候,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。为-1的时候,用所有CPU的内核运行程序。
累死我了....终于写完所有参数了。
除此之外,LogisticRegression也有一些方法供我们使用:

有一些方法和MultinomialNB的方法都是类似的,因此不再累述。
对于每个函数的具体使用,可以看下官方文档:http://scikit-learn.org/dev/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
同时,如果对于过拟合、正则化、L1范数、L2范数不了解的,可以看这位大牛的博客:http://blog.csdn.net/zouxy09/article/details/24971995
2、编写代码
了解到这些,我们就可以编写Sklearn分类器的代码了。代码非常短:
# -*- coding:UTF-8 -*-
from sklearn.linear_model import LogisticRegression
"""
函数说明:使用Sklearn构建Logistic回归分类器
Parameters:
无
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def colicSklearn():
frTrain = open('horseColicTraining.txt')#打开训练集
frTest = open('horseColicTest.txt')#打开测试集
trainingSet = []; trainingLabels = []
testSet = []; testLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[-1]))
for line in frTest.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
testSet.append(lineArr)
testLabels.append(float(currLine[-1]))
classifier = LogisticRegression
(solver='liblinear',max_iter=10).fit(trainingSet, trainingLabels)
test_accurcy = classifier.score(testSet, testLabels) * 100
print('正确率:%f%%' % test_accurcy)
if __name__ == '__main__':
colicSklearn()
运行结果如下:
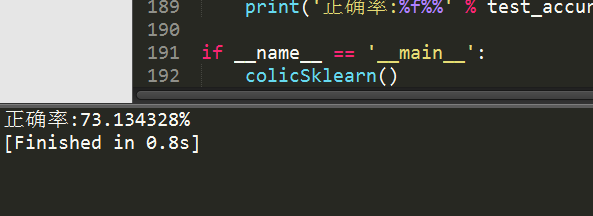
可以看到,正确率又高一些了。更改solver参数,比如设置为sag,使用随机平均梯度下降算法,看一看效果。你会发现,有警告了。

显而易见,警告是因为算法还没有收敛。更改max_iter=5000,再运行代码:

可以看到,对于我们这样的小数据集,sag算法需要迭代上千次才收敛,而liblinear只需要不到10次。
还是那句话,我们需要根据数据集情况,选择最优化算法。
五、总结
1、Logistic回归的优缺点
优点:
缺点:
2、其他
-
Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法完成。
-
改进的一些最优化算法,比如sag。它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批量处理。
-
机器学习的一个重要问题就是如何处理缺失数据。这个问题没有标准答案,取决于实际应用中的需求。现有一些解决方案,每种方案都各有优缺点。
-
我们需要根据数据的情况,这是Sklearn的参数,以期达到更好的分类效果。
-
下篇文章将讲解支持向量机SVM。
-
如有问题,请留言。如有错误,还望指正,谢谢!
PS: 如果觉得本篇本章对您有所帮助,欢迎关注、评论、赞!
本文出现的所有代码和数据集,均可在我的github上下载,欢迎Follow、Star:https://github.com/Jack-Cherish/Machine-Learning
参考文献:
本系列篇章:
Logistic回归实战篇之预测病马死亡率(一)
Logistic回归实战篇之预测病马死亡率(二)
Logistic回归实战篇之预测病马死亡率(三)
往期精彩文章推荐

数据挖掘中的利器--XGBoost理论篇
Scikit-learn实战之 SVM回归分析、密度估计、异常点检测
章神的私房菜之数据预处理
教你用python做文本分类
扫描燕哥微信号,
拉你进机器学习大牛群。
福利满满,名额已不多…

群里目前包括:
清华张长水教授,
清华顾险峰教授,
北大黄铁军教授,
西安电子科技大学焦李成教授,
新加坡南洋理工大学黄广斌教授,
北交李清勇教授
等等……
目前100000+人已关注我们微信公众号