(1)问题:

在此使用k近邻算法实现一个简单分类器。
其中model.xls表样式如下表1所示:
表1:model.xls数据表
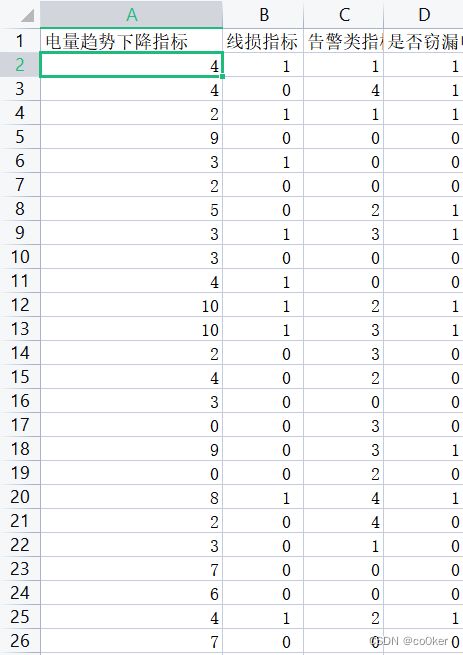
分析:①数据存放在model.xls中,需要利用panda数据,对数据进行切片为指标和结果。
②切片后的数据类型为dataframe类型,需要转换为列表才能对数据进行处理。
③利用sklearn.neighbors的KNeighborsClassifier实现一个简单的k近邻分类器。
④利用该k近邻分类器对原指标数据进行预测。
⑤计算出分类器的准确率。
代码如下:
import pandas as pd #导入数据分析库Pandas
from sklearn.neighbors import KNeighborsClassifier #导入k近邻分类器KNeighborsClassifier
inputfile = 'model.xls' #输入数据路径,需要使用Excel格式;
data = pd.read_excel(inputfile, header=None) #读入数据
#切出指标数据片,并转换为列表
datas_frame_index = data.iloc[1:292,0:3]
datas_list_index = datas_frame_index.values.tolist()
# print(datas_list_index)
#切出结果数据片,并转换为列表
datas_frame_result = data.iloc[1:292,3]
datas_list_result= datas_frame_result.values.tolist()
# print(datas_list_result)
x=datas_list_index #指标
y=datas_list_result #结果
neigh=KNeighborsClassifier(n_neighbors=5) #最近的五个点是哪类则归为哪类
neigh.fit(x,y) #放入原因和结果,构造k近邻分类器
predict_array =neigh.predict(datas_list_index) #对原指标数据进行预测
# print(predict_array)
# print(type(predict_array))
#计算分类器准确率
count = 0
for i in range(291):
# print(predict_array[i])
if predict_array[i]==datas_list_result[i]:
count = count + 1
rate_correct = count/291*100
print(f'分类器准确率为{rate_correct}%')
其中datas_list_index如下图1所示,datas_list_result如下图2所示:

图1 datas_list_index

图2 datas_list_result
运行结果截图,如下图3所示:
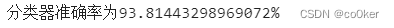
图3 运行结果