先上代码:
# 2020/3/27,中国,CN,82213,184,75122,3301,3790
# 2020/3/27,英国,GB,14579,0,150,759,13670
# 2020/3/27,日本,JP,1507,0,359,51,1097
# 2020/3/27,美国,US,86012,0,753,1301,83958
# 2020/3/27,韩国,KR,9332,0,4528,139,4665
# 导入库
import csv
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('hjptest4data.csv')
list = data.values.tolist()
# print(data)
# print(list)
# print(list[0])
for i in range(0,5):
print(i)
print(list[i])
print(list[i][0])
x = ['中国','英国','日本','美国','韩国']
confirmed = [0,0,0,0,0]#累计
dead = [0,0,0,0,0]#
cured = [0,0,0,0,0]
current = [0,0,0,0,0]
for i in range(0,5):
confirmed[i] = list[i][1]
dead[i] = list[i][4]
cured[i] = list[i][3]
current[i] = list[i][5]
print( confirmed[i] ,
dead[i] ,
cured[i] ,
current[i] )
plt.bar(x, current, align="center", color="r", label="现存确诊人数")
plt.bar(x, dead, align="center", bottom=current, color="g", label="死亡")
for i in range(0, len(current)):
dead[i] = dead[i] + current[i]
plt.bar(x, cured, align="center", bottom=dead, color="b", label="治疗人数")
plt.xlabel("国家")
plt.ylabel("累计确诊人数")
plt.ylim(1500,87000)
plt.legend()
#plt.savefig(r'hjp1.jpg')
plt.show()
#注意地方就是在设置第三类数据的底部,应该是第一类加第二类作底部:
#plt.bar(x, y2, align="center", bottom=y1, color="#F6C555", label="中立")
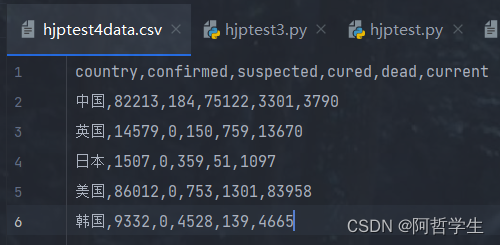
数据文档:
结果图:

这里日本的柱形图看不到是因为数据问题相对来说日本的数量太小了。也不知道收集数据的人有没有搞错,按题目来就是这样了。
这里主要是通过pandas库预处理一下数据,其实就是读取数据,然后通过matplotlib进行图像呈现。而使用Pandas库进行数据可视化时,常用的参数有: 1.kind 可视化图的种类: 'line' : 折线图 (默认) 'bar ' : 柱状图 'barh' : 水平柱状图 'hist' : 直方图 'area' : 面积图 'pie ' : 饼状图 2.figsize 画布尺寸 3.title 标题 4.grid 是否显示格子线条 5.legend 是否显示图例 6.stacked 是否堆积 7.marker 绘图中数据点的类型。
plt.bar(x, cured, align="center", bottom=dead, color="b", label="治疗人数")
需要注意的地方就是好像这里这个bottom=dead这个参数就是你需要确定你到底需要把那个数放下面,那个作为底依次递增上去。