Python爬虫—王者荣耀(最详细)
首先来到王者荣耀的首页

点击游戏壁纸进去,就会看到这些图片,大致看了一下,是我们想要的东西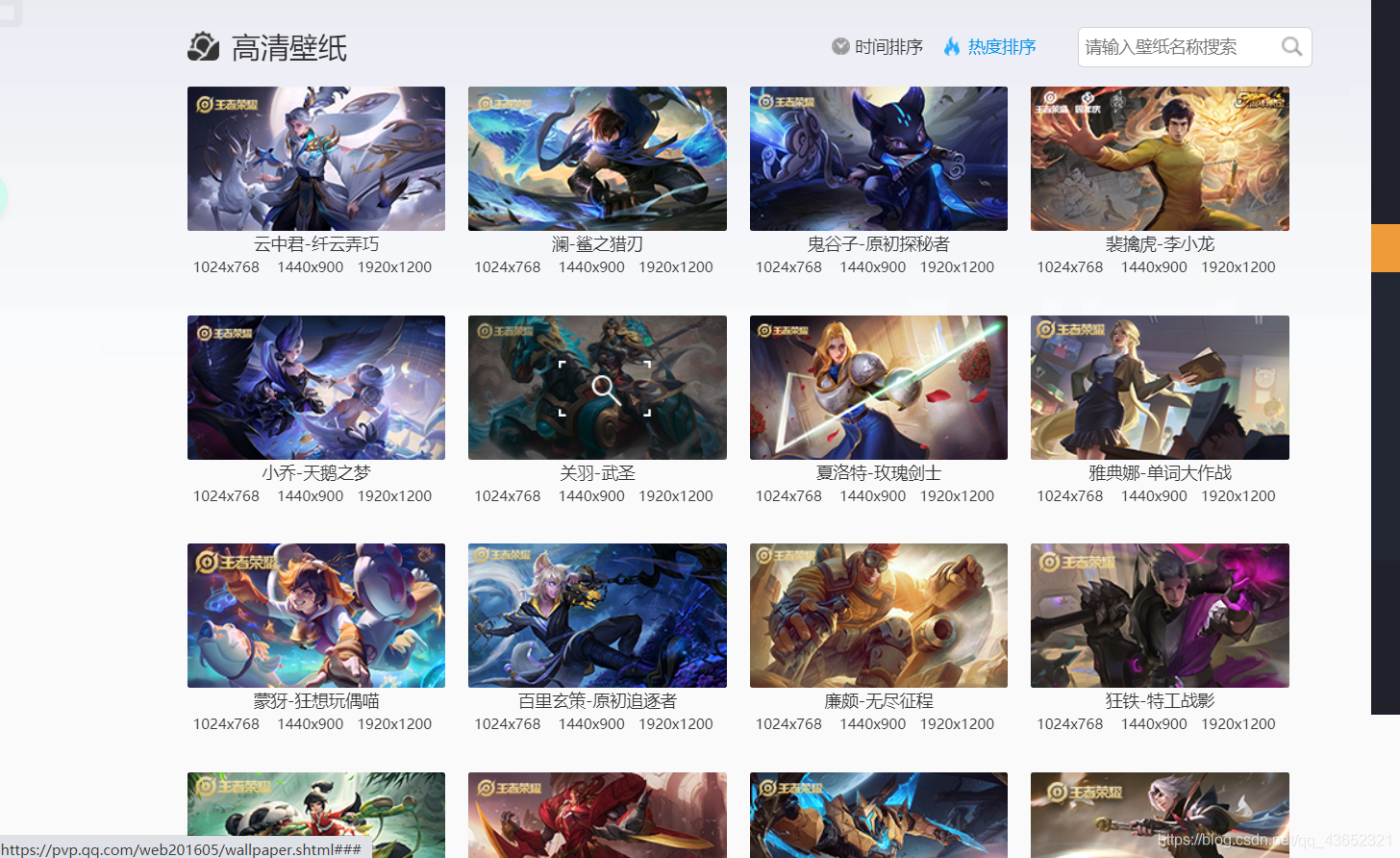
点开图片看看能不能找到什么规律

可以看见每张图下面都有六个分辨率的选项,我们点两个进去看看

19201080的点开,图片很清晰。我们再点一个其他分辨率的

这个是1024768的
我们来看一下url的区别在哪里
1920*1080的url:http://shp.qpic.cn/ishow/2735120117/1606814547_84828260_690_sProdImgNo_6.jpg/0
1024*768的url:http://shp.qpic.cn/ishow/2735120117/1606814546_84828260_690_sProdImgNo_2.jpg/0
其实不难看出,区别在于一个是sProdImgNo_6另一个是sProdImgNo_2
那么他们有什么规律呢?
我们再回去看一下网页

19201080的位置是第五个
1024768的位置是第一个
sProdImgNo_6在5的位置上
sProdImgNo_2在1的位置上
那么?sProdImgNo_1是什么东西呢?我们去看看

sProdImgNo_1也是一张图,不过分辨率更小了,这样就有个规律了

不过一张是远远不够的,我们要全部图片的规律和链接
既然找到了东西,我们就可以开分析一下网页了,来找找数据源在哪里,按F12

经过一番的查找,我们可以看到这个文件中有一堆json数据,且很像存放图片的地方

复制这个链接,我们打开看看
看到的应该是这样的

一堆不知名的东西,很头疼
但是你可以安装一个浏览器插件,来让它变得更“好看”
它的名字就是 JSON-handle
安装好之后,你再打开网页就是这样的了

是不是就好看多了,看起来也更加清晰了
但是你会发现还是一堆乱七八糟的
为什么呢?因为它用了UrlEncode编码
不过我们有办法让它解码,让我们看得懂它

先随便点一个乱码,然后单击右上角的deURL,就变成我们可以看懂的了
逐一去看看,发现的确是我们要的东西,而且这次就不=只是一张图的链接了,是一页的数据,都在里面

当你的数据找到位置了,现在差不多就可以开始写代码了
import re
import time
import requests
from urllib import parse
import threading
headers = {
'cookie':'',
'user-agent':'',
}
start = time.time()
try:
count = 0
countPage = 23
for page in range(0, countPage):
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={0}&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171049106997163594523_1606960309787&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1606960310077'.format(
page)
response =requests.get(url, headers=headers, timeout= 3)
if response.status_code == 200:
html = response.text
nameList = re.findall(r'"sProdName":(.*?),', html)
urlList = re.findall(r'"sProdImgNo_6":(.*?),', html)
if page == 1:
cPage = re.findall(r'"iTotalPages":(.*?),', html)
cPage = ''.join(cPage).replace('"','')
countPage = int(cPage)
print('\n第{0}页\n'.format(page+1))
for name, url in zip(nameList, urlList):
name = parse.unquote(name).replace('"', '')
url = parse.unquote(url).replace('"', '')[:-3]+ '0'
print('{0}、{1} 已获取!\n'.format((count+1),name))
fileName = name+ '.jpg'
with open('./pic/' + fileName, 'wb') as file:
img_url = requests.get(url)
if img_url.status_code ==200:
file.write(img_url.content)
count = count+ 1
print('获取结束\n本次获取{0}页,{1}张图片!'.format(countPage, count))
except KeyboardInterrupt:
print('非正常退出')
finally:
print('\n本次总耗时{0:.2f}秒\t相当于{1:.2f}分钟'.format((time.time() - start), (time.time() - start) / 60))
这样我们就可以开始运行了

仅供参考学习
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)