什么是groupby
以下为对DataFrame对象按A进行分组操作,图片来源。

内容

目的
DataFrame对象按照指定列["LNG","LAT"]分组计数,并将分组计数结果(包括指定列及计数值)写入csv文件中
过程
代码一:
import pandas as pd
def weekFlow():
path="./group_test.csv"
df=pd.read_csv(path,header=0,names=["DEVICE_ID","LNG","LAT"])
df_=df.groupby(["LNG","LAT"]).count()
print(df_)
df_.to_csv("./group_test_result.csv",header=False,index=False)
if __name__=="__main__":
weekFlow()
结果csv文件:
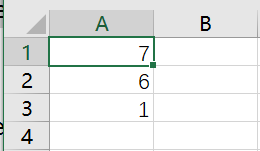
不是想要的~~
代码二(使用reset_index()):
import pandas as pd
def weekFlow():
path="./group_test.csv"
df=pd.read_csv(path,header=0,names=["DEVICE_ID","LNG","LAT"])
df_=df.groupby(["LNG","LAT"]).count().reset_index() #重置索引,原来的索引["LNG","LAT"]作为列保存下来,若设置drop=True,则原来的索引["LNG","LAT"]会丢掉
print(df_)
df_gp_head=df.groupby(["LNG","LAT"]).head(1) #取每组的第一个组成新DataFrame对象
df_gp_tail=df.groupby(["LNG","LAT"]).tail(1) #取每组的最后一个组成新DataFrame对象
df_.to_csv("./group_test_result.csv",header=False,index=False)
if __name__=="__main__":
weekFlow()
结果csv文件:

目的达成!!