本博客对应于 B 站尚硅谷教学视频 尚硅谷数据湖Iceberg实战教程(尚硅谷&Apache Iceberg官方联合推出),为视频对应笔记的相关整理。
1. Iceberg简介
1.1 概述
为了解决数据存储和计算引擎之间的适配的问题,Netflix 开发了 Iceberg,2018 年 11 月 16 日进入 Apache 孵化器,2020 年 5 月 19 日从孵化器毕业,成为 Apache 的顶级项目。
Iceberg 是一个面向海量数据分析场景的开放表格式(Table Format)。表格式(Table Format)可以理解为元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件之上。
1.2 特性
1.2.1 数据存储、计算引擎插件化
Iceberg 提供一个开放通用的表格式(Table Format)实现方案,不和特定的数据存储、计算引擎绑定。目前大数据领域的常见数据存储(HDFS、S3…),计算引擎(Flink、Spark…)都可以接入 Iceberg。
在生产环境中,可选择不同的组件搭使用。甚至可以不通过计算引擎,直接读取存在文件系统上的数据。
1.2.2 实时流批一体
Iceberg 上游组件将数据写入完成后,下游组件及时可读,可查询。可以满足实时场景。并且 Iceberg 同时提供了流/批读接口、流/批写接口。可以在同一个流程里,同时处理流数据和批数据,大大简化了ETL链路。
1.2.3 数据表演化(Table Evolution)
Iceberg 可以通过 SQL 的方式进行表级别模式演进。进行这些操作的时候,代价极低。不存在读出数据重新写入或者迁移数据这种费时费力的操作。
比如在常用的 Hive 中,如果我们需要把一个按天分区的表,改成按小时分区。此时,不能再原表之上直接修改,只能新建一个按小时分区的表,然后再把数据 Insert 到新的小时分区表。而且,即使我们通过 Rename 的命令把新表的名字改为原表,使用原表的上次层应用,也可能由于分区字段修改,导致需要修改 SQL,这样花费的经历是非常繁琐的。
1.2.4 模式演化(Schema Evolution)
Iceberg 支持下面几种模式演化:
-
ADD:向表或者嵌套结构增加新列
-
Drop:从表中或者嵌套结构中移除一列
-
Rename:重命名表中或者嵌套结构中的一列
-
Update:将复杂结构(struct, map<key, value>,list)中的基本类型扩展类型长度, 比如 tinyint 修改成 int.
-
Reorder:改变列或者嵌套结构中字段的排列顺序
Iceberg 保证模式演化(Schema Evolution)是没有副作用的独立操作流程,一个元数据操作, 不会涉及到重写数据文件的过程。具体的如下:
-
增加列时候,不会从另外一个列中读取已存在的的数据
-
删除列或者嵌套结构中字段的时候,不会改变任何其他列的值
-
更新列或者嵌套结构中字段的时候,不会改变任何其他列的值
-
改变列列或者嵌套结构中字段顺序的时候,不会改变相关联的值
在表中,Iceberg 使用唯一 ID 来定位每一列的信息。新增一个列的时候,会新分配给它一个唯一 ID,并且绝对不会使用已经被使用的ID。
使用名称或者位置信息来定位列的, 都会存在一些问题,比如使用名称的话,名称可能会重复, 使用位置的话,不能修改顺序并且废弃的字段也不能删除。
1.2.5 分区演化(Partition Evolution)
Iceberg 可以在一个已存在的表上直接修改,因为 Iceberg 的查询流程并不和分区信息直接关联。
当我们改变一个表的分区策略时,对应修改分区之前的数据不会改变,依然会采用老的分区策略,新的数据会采用新的分区策略,也就是说同一个表会有两种分区策略,旧数据采用旧分区策略,新数据采用新新分区策略,在元数据里两种分区策略相互独立,不重合。
在查询数据的时候,如果存在跨分区策略的情况,则会解析成两个不同执行计划,如 Iceberg 官网提供图所示:
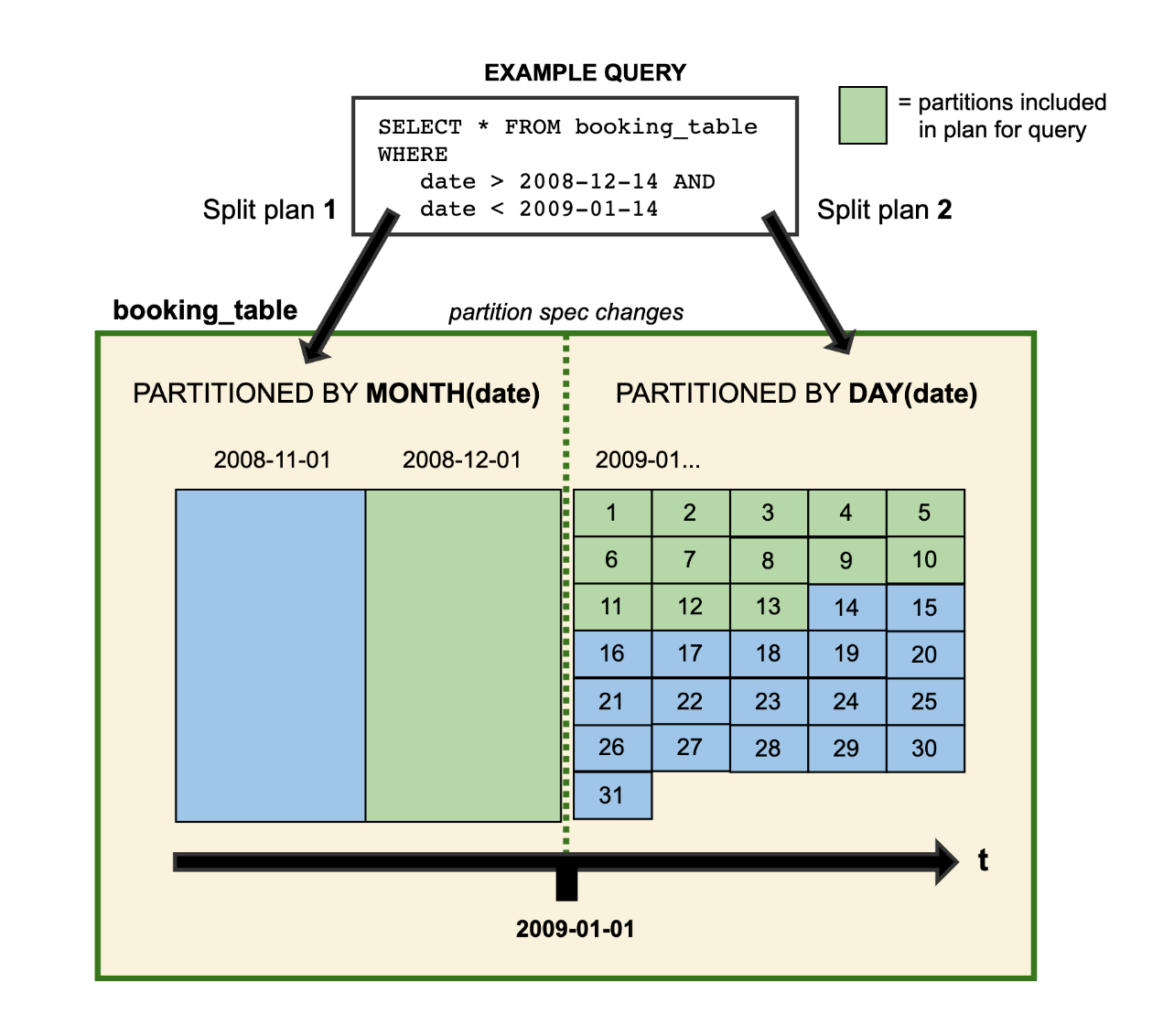
图中 booking_table 表 2008 年按月分区,进入 2009年 后改为按天分区,这两中分区策略共存于该表中。
借助 Iceberg 的隐藏分区(Hidden Partition),在写 SQL 查询的时候,不需要在 SQL 中特别指定分区过滤条件,Iceberg 会自动分区,过滤掉不需要的数据。
Iceberg 分区演化操作同样是一个元数据操作, 不会重写数据文件。
1.2.6 列顺序演化(Sort Order Evolution)
Iceberg 可以在一个已经存在的表上修改排序策略。修改了排序策略之后,旧数据依旧采用老排序策略不变。往Iceberg里写数据的计算引擎总是会选择最新的排序策略,但是当排序的代价极其高昂的时候, 就不进行排序了。
1.2.7 隐藏分区(Hidden Partition)
Iceberg 的分区信息并不需要人工维护,它可以被隐藏起来。不同于其他类似 Hive 的分区策略,Iceberg 的分区字段/策略(通过某一个字段计算出来),可以不是表的字段和表数据存储目录也没有关系。在建表或者修改分区策略之后,新的数据会自动计算所属于的分区。在查询的时候同样不用关心表的分区是什么字段/策略,只需要关注业务逻辑,Iceberg 会自动过滤不需要的分区数据。
正是由于 Iceberg 的分区信息和表数据存储目录是独立的,使得 Iceberg 的表分区可以被修改,而且不涉及到数据迁移。
1.2.8 时间旅行查询(Time Travel)
Iceberg 提供了查询表历史某一时间点数据镜像(snapshot)的能力。通过该特性可以将最新的SQL逻辑,应用到历史数据上。
1.2.9 支持事务(ACID)
Iceberg 通过提供事务(ACID)的机制,使其具备了 upsert 的能力并且使得边写边读成为可能,从而数据可以更快的被下游组件消费。通过事务保证了下游组件只能消费已 commit 的数据,而不会读到部分甚至未提交的数据。
1.2.10 基于乐观锁的并发支持
Iceberg 基于乐观锁提供了多个程序并发写入的能力并且保证数据线性一致。
1.2.11 文件级数据剪裁
Iceberg 的元数据里面提供了每个数据文件的一些统计信息,比如最大值,最小值,Count 计数等等。因此,查询 SQL 的过滤条件除了常规的分区,列过滤,甚至可以下推到文件级别,大大加快了查询效率。
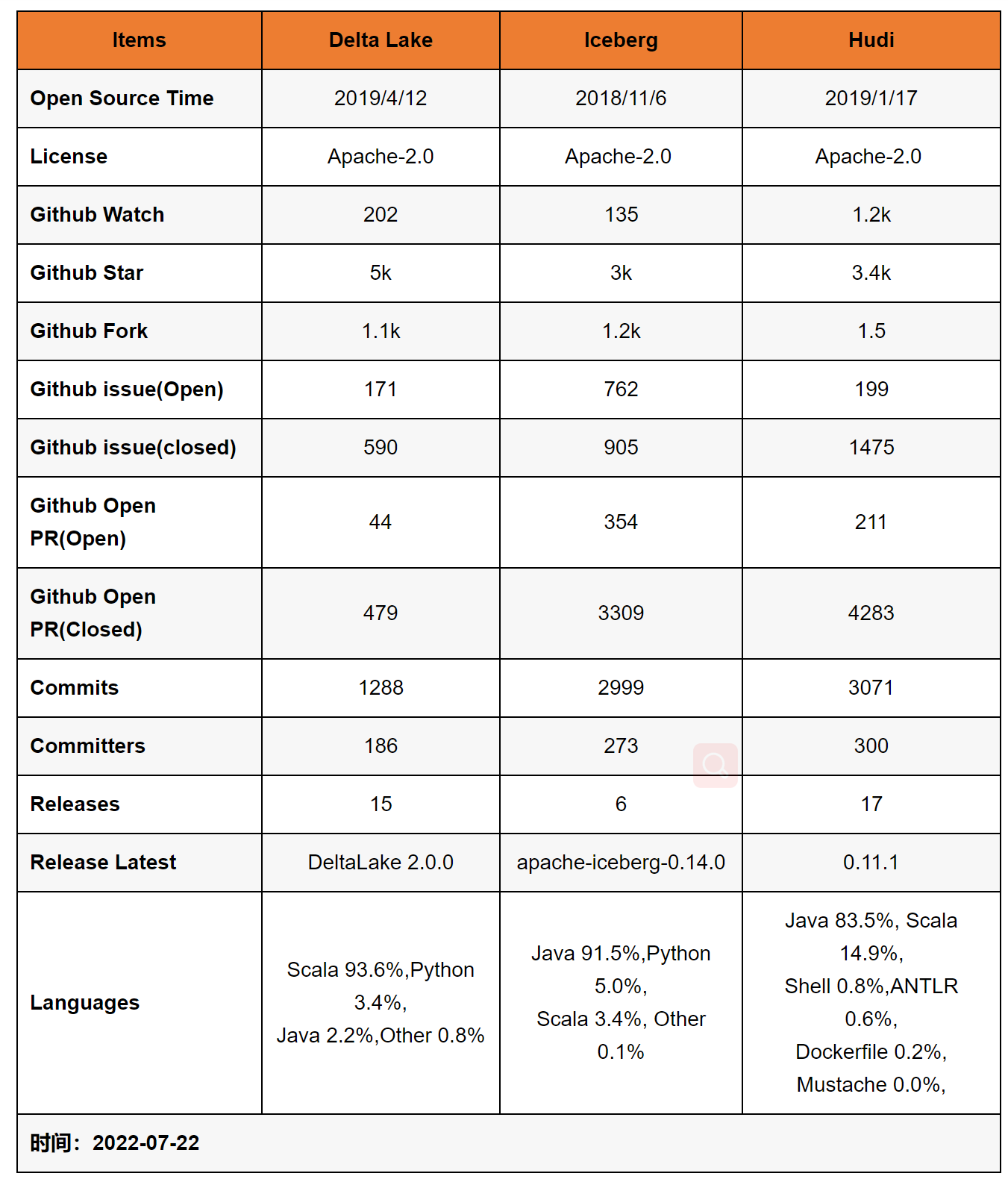
1.3 其他数据湖框架的对比

2. 存储结构

2.1 数据文件 data files
数据文件是 Apache Iceberg 表真实存储数据的文件,一般是在表的数据存储目录的 data 目录下,如果我们的文件格式选择的是 parquet,那么文件是以 .parquet 结尾。
例如:00000-0-atguigu_20230203160458_22ee74c9-643f-4b27-8fc1-9cbd5f64dad4-job_1675409881387_0007-00001.parquet 就是一个数据文件。
Iceberg 每次更新会产生多个数据文件(data files)。
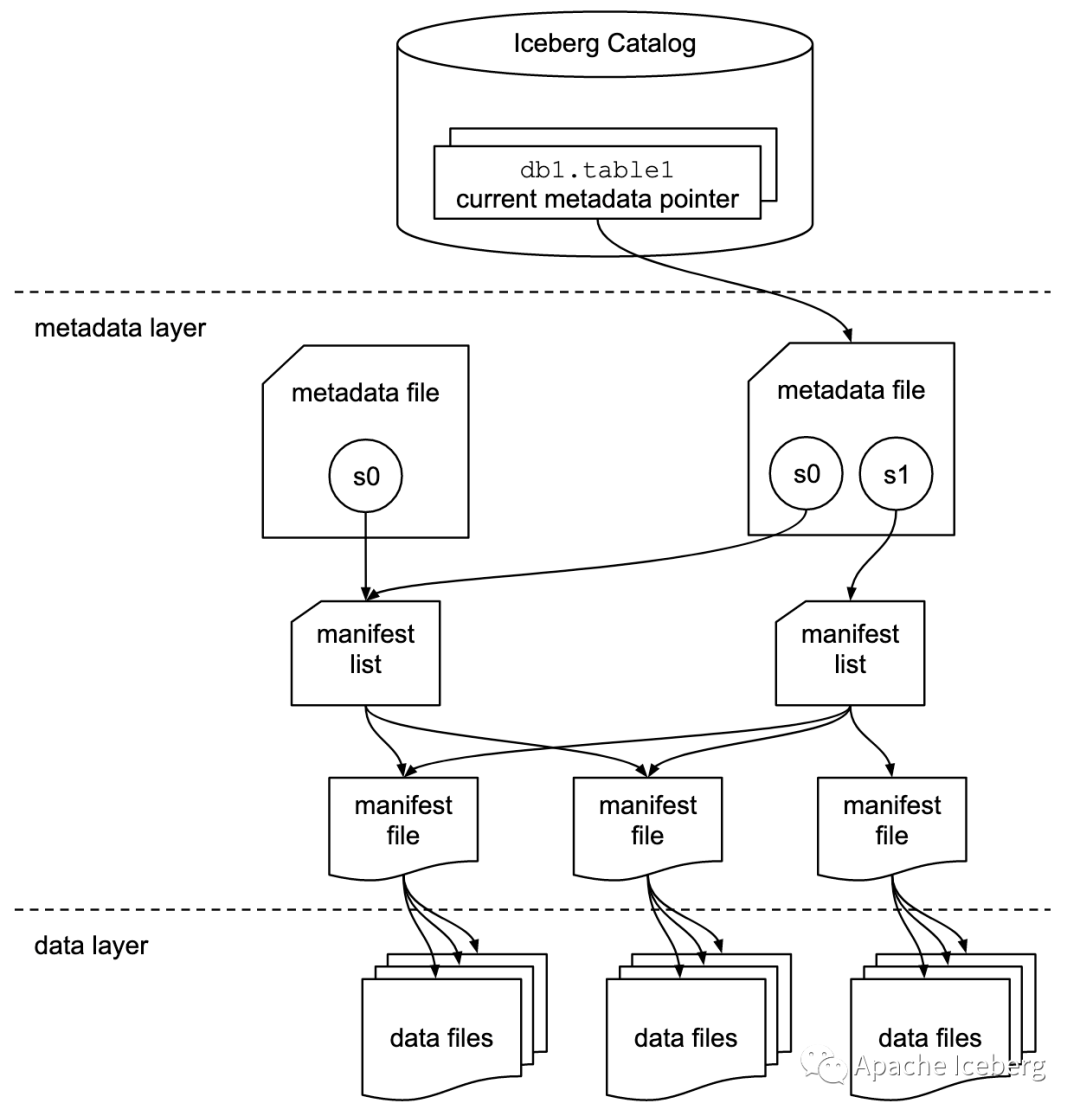
2.2 表快照 Snapshot
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有 data file 列表。data file 存储在不同的 manifest file 里面,manifest file 存储在一个 Manifest list文 件里面,而一个 Manifest list 文件代表一个快照。
2.3 清单列表 Manifest list
manifest list 是一个元数据文件,列出构建表快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是 Manifest file 列表,每个 Manifest file 占据一行。每行中存储了 Manifest file 的路径、其存储数据文件(data files)的分区范围,增加了几个数文件、删除了几个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
例如:snap-6746266566064388720-1-52f2f477-2585-4e69-be42-bbad9a46ed17.avro 就是一个 Manifest List 文件。
2.4 清单文件 Manifest file
Manifest file 也是一个元数据文件,它列出组成快照(snapshot)的数据文件(data file)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
Manifest file 是以 avro 格式进行存储的,以 .avro 后缀结尾,例如:52f2f477-2585-4e69-be42-bbad9a46ed17-m0.avro。
3. 与 Hive集成
3.1 环境准备
-
Hive 与 Iceberg 的版本对应关系如下
| 官方推荐 Hive 版本 |
Hive 版本 |
Iceberg 版本 |
| 2.3.8 |
2.x |
0.8.0-incubating – 1.1.0 |
| 3.1.2 |
3.x |
0.10.0 – 1.1.0 |
Iceberg 与 Hive 2 和 Hive 3.1.2/3 的集成,支持以下特性:
-
上传 jar 包,拷贝到 Hive 的 auxlib 目录中
mkdir auxlib
cp iceberg-hive-runtime-1.1.0.jar /opt/module/hive/auxlib
cp libfb303-0.9.3.jar /opt/module/hive/auxlib
-
修改 hive-site.xml,添加配置项
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/opt/module/hive/auxlib</value>
</property>
使用 TEZ 引擎注意事项:
-
Hive 版本 >=3.1.2,需要 TEZ 版本 >=0.10.1
-
指定 tez 更新配置:
<property>
<name>tez.mrreader.config.update.properties</name>
<value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value>
</property>
-
从 Iceberg 0.11.0 开始,如果 Hive 使用 Tez 引擎,需要关闭向量化执行:
<property>
<name>hive.vectorized.execution.enabled</name>
<value>false</value>
</property>
-
启动HMS服务
-
启动 Hadoop
3.2 创建和管理 Catalog
Iceberg 支持多种不同的 Catalog 类型,例如:Hive、Hadoop、亚马逊的 AWS Glue 和自定义 Catalog。
根据不同配置,分为三种情况:
-
没有设置 iceberg.catalog,默认使用 HiveCatalog
-
设置 iceberg.catalog 的类型,使用指定的 Catalog 类型,如下表格:
| 配置项 |
说明 |
| iceberg.catalog.<catalog_name>.type |
Catalog 的类型: hive, hadoop, 如果使用自定义 Catalog,则不设置 |
| iceberg.catalog.<catalog_name>.catalog-impl |
Catalog 的实现类, 如果上面的 type 没有设置,则此参数必须设置 |
| iceberg.catalog.<catalog_name>. |
Catalog 的其他配置项 |
-
设置 iceberg.catalog=location_based_table,直接通过指定的根路径来加载 Iceberg 表。
3.1.1 默认使用 HiveCatalog
CREATE TABLE iceberg_test1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
INSERT INTO iceberg_test1 values(1);
查看 HDFS 可以发现,表目录在默认的 hive 仓库路径下。
3.1.2 指定 Catalog 类型
-
使用 HiveCatalog
set iceberg.catalog.iceberg_hive.type=hive;
set iceberg.catalog.iceberg_hive.uri=thrift://hadoop1:9083;
set iceberg.catalog.iceberg_hive.clients=10;
set iceberg.catalog.iceberg_hive.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hive;
CREATE TABLE iceberg_test2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');
INSERT INTO iceberg_test2 values(1);
-
使用 HadoopCatalog
set iceberg.catalog.iceberg_hadoop.type=hadoop;
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hadoop;
CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');
INSERT INTO iceberg_test3 values(1);
3.1.3 指定路径加载
如果 HDFS 中已经存在 iceberg 格式表,我们可以通过在 Hive 中创建 Icerberg 格式表指定对应的 location 路径映射数据。
CREATE EXTERNAL TABLE iceberg_test4 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');
3.3 基本操作
3.3.1 创建表
-
创建外部表
CREATE EXTERNAL TABLE iceberg_create1 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create1;
-
创建内部表
CREATE TABLE iceberg_create2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create2;
-
创建分区表
CREATE EXTERNAL TABLE iceberg_create3 (id int,name string)
PARTITIONED BY (age int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';
describe formatted iceberg_create3;
Hive 语法创建分区表,不会在 HMS 中创建分区,而是将分区数据转换为 Iceberg 标识分区。这种情况下不能使用 Iceberg 的分区转换,例如:days(timestamp),如果想要使用 Iceberg 格式表的分区转换标识分区,需要使用 Spark 或者 Flink 引擎创建表。
3.3.2 修改表
只支持 HiveCatalog 表修改表属性,Iceberg 表属性和 Hive 表属性存储在 HMS 中是同步的。
ALTER TABLE iceberg_create1 SET TBLPROPERTIES('external.table.purge'='FALSE');
3.3.3 插入表
支持标准单表 INSERT INTO 操作
INSERT INTO iceberg_create2 VALUES (1);
INSERT INTO iceberg_create1 select * from iceberg_create2;
在 HIVE 3.x 中,INSERT OVERWRITE 虽然能执行,但其实是追加。
3.3.4 删除表
DROP TABLE iceberg_create1;
4. 与 Spark SQL集成
4.1 环境准备
4.1.1 安装 Spark
-
Spark 与 Iceberg 的版本对应关系如下
| Spark 版本 |
Iceberg 版本 |
| 2.4 |
0.7.0-incubating – 1.1.0 |
| 3.0 |
0.9.0 – 1.0.0 |
| 3.1 |
0.12.0 – 1.1.0 |
| 3.2 |
0.13.0 – 1.1.0 |
| 3.3 |
0.14.0 – 1.1.0 |
-
上传并解压 Spark 安装包
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
mv /opt/module/spark-3.3.1-bin-hadoop3 /opt/module/spark-3.3.1
-
配置环境变量
sudo vim /etc/profile.d/my_env.sh
export SPARK_HOME=/opt/module/spark-3.3.1
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile.d/my_env.sh
-
拷贝 iceberg 的 jar 包到 Spark 的 jars 目录
cp /opt/software/iceberg/iceberg-spark-runtime-3.3_2.12-1.1.0.jar /opt/module/spark-3.3.1/jars
4.1.2 启动 Hadoop
(略)
4.2 Spark 配置 Catalog
Spark 中支持两种 Catalog 的设置:hive 和 hadoop,Hive Catalog 就是 Iceberg 表存储使用 Hive 默认的数据路径,Hadoop Catalog 需要指定 Iceberg 格式表存储路径。
下面修改 spark 的默认配置文件
vim spark-defaults.conf
4.2.1 Hive Catalog
将下面的代码配置到 spark-defaults.conf 文件中
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://hadoop1:9083
4.2.2 Hadoop Catalog
将下面的代码配置到 spark-defaults.conf 文件中
spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoop
spark.sql.catalog.hadoop_prod.warehouse = hdfs://hadoop1:8020/warehouse/spark-iceberg
4.3 SQL 操作
4.3.1 创建表
use hadoop_prod;
create database default;
use default;
CREATE TABLE hadoop_prod.default.sample1 (
id bigint COMMENT 'unique id',
data string)
USING iceberg;
-
PARTITIONED BY (partition-expressions) :配置分区
-
LOCATION ‘(fully-qualified-uri)’ :指定表路径
-
COMMENT ‘table documentation’ :配置表备注
-
TBLPROPERTIES (‘key’=‘value’, …) :配置表属性
对 Iceberg 表的每次更改都会生成一个新的元数据文件(json文件)以提供原子性。默认情况下,旧元数据文件作为历史文件保存不会删除。
如果要自动清除元数据文件,在表属性中设置 write.metadata.delete-after-commit.enabled=true。这将保留一些元数据文件(直到元数据文件版本数量超过 write.metadata.previous-versions-max),并在每个新创建的元数据文件之后删除旧的元数据文件。
-
创建分区表
-
分区表
CREATE TABLE hadoop_prod.default.sample2 (
id bigint,
data string,
category string
)
USING iceberg
PARTITIONED BY (category)
-
创建隐藏分区表
CREATE TABLE hadoop_prod.default.sample3 (
id bigint,
data string,
category string,
ts timestamp
)
USING iceberg
PARTITIONED BY (bucket(16, id), days(ts), category)
支持的转换有:
-
years(ts):按年划分
-
months(ts):按月划分
- **days(ts) **或 date(ts):等效于 dateint 分区
-
hours(ts) 或 date_hour(ts):等效于dateint和hour分区
- **bucket(N, col)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)