目录
scikit-learn数据集API介绍
sklearn小数据集
sklearn大数据集
sklearn数据集的使用
数据集的划分
特征工程
特征抽取/特征提取
特征提取API
字典特征提取
文本特征提取
中文文本特征值抽取
停用词
中文文本特征值抽取分词处理
文本特征抽取TfidfVevtorizer
特征预处理
归一化
标准化
特征降维
降维
特征选择
过滤式
主成分分析(PCA)
what?
API
案例:探究用户对物品类别的喜好细分降维
步骤
scikit-learn数据集API介绍
sklearn.datasets用来加载获取流行数据集
- datasets.load_*() :获取小规模数据集,数据包含在datasets中
- datasets.fetch_*(data_home=None):获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
sklearn小数据集
以鸢尾花为例
sklearn.datasets.load_iris():加载并返回鸢尾花数据集
| 名称 |
数量 |
| 类别 |
3 |
| 特征 |
4 |
| 样本数量 |
150 |
| 每个类别数量 |
50 |
sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train')
- subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
sklearn数据集的使用
sklearn数据集返回值介绍
load和fetch返回的数据类型datasets.base.Bunch(这个是字典格式的)
- data:特征数据数组,是二维数组
- target:标签数组,是目标值
- DESCR:数据描述
- feature_names:特征的名字
- target_names:目标值的名字
可以用两种方式获取值
- dict["key"] = values
- bunch.key = values
数据集的划分
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
测试集:20%~30%
sklearn.model_selection.train_test_split(arrays, *options)
- x数据集的特征值
- y数据集的标签值
- test_size测试集的大小,一般为float
- random_state随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return训练集特征值(x_train),测试集特征值(x_test),训练集目标值(y_train),测试集目标值(y_test)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def datasets_demo():
# 获取数据集
iris = load_iris()
print(iris)
print("特征数据\n", iris["data"])
print("目标值\n", iris.target)
print("数据描述\n", iris["DESCR"])
print("特征的名字\n", iris.feature_names)
print("目标值名字\n", iris.target_names)
# 数据集的划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# shape是看有多少行多少列
print("训练集的特征值:\n", x_train, x_train.shape)
if __name__ == "__main__":
datasets_demo()
特征工程
对特征进行处理
sklearn特征工程
pandas数据清洗、数据处理
特征抽取/特征提取
有些数据不能被直接处理,所以要用一种方式将它转换
将任意数据(如文本或图像)转换为可用于机器学习的数字特征(特征值化是为了计算机更好的去理解数据)
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习)
特征提取API
sklearn.feature_extraction
字典特征提取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorizer(sparse=True,...)
- DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值:返回sparse矩阵(系稀疏矩阵)
- DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵 返回值:转换之前的数据格式
- DictVectorizer.get_feature_names() 返回类别名称
vector 数学:向量 物理:矢量
- 矩阵 matrix 二维数组
- 向量 vector 一维数组
父类:转换器类
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
data = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60}, {'city': '深圳', 'temperature': 30}]
# 1.实例化一个转换器类
transfer = DictVectorizer()
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
print("特征值名称:\n", transfer.get_feature_names())
if __name__ == "__main__":
dict_demo()

返回结果是一个稀疏(sparse)矩阵
将改为:transfer = DictVectorizer(sparse=False)返回二维数组效果为

第一张结果图表示的是第二张结果图的非零值的位置
应用场景
- 将数据集的特征-->字典类型
- DictVectorizer转换
文本特征提取
作用:对文本数据进行特征值化
以单词作为特征
sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) 返回的是词频矩阵,统计每个样本特征值出现次数
- CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象,返回值:返回sparse矩阵
- CountVectorizer.inverse_transform(X) X:array数组或者sparse矩阵,返回值:转换之前数据格
- CountVectorizer.get_feature_names() 返回值:单词列表
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1.实例化一个转换器类
transfer = CountVectorizer()
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
print("特征值名称:\n", transfer.get_feature_names_out())
if __name__ == "__main__":
count_demo()
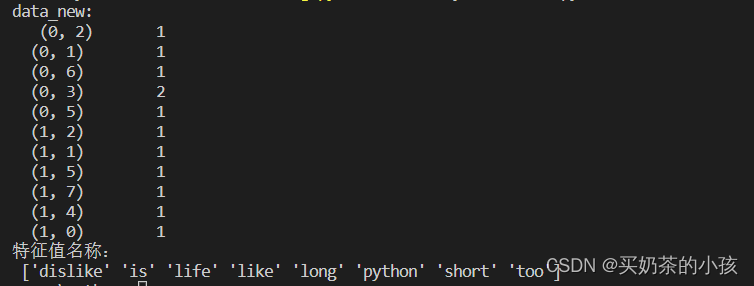
将结果转为二维数组
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1.实例化一个转换器类
transfer = CountVectorizer()
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
# CountVectorizer()不可以设置sparse矩阵
# toarray()方法可以将sparse矩阵转成二维数组
print("data_new:\n", data_new.toarray())
print("特征值名称:\n", transfer.get_feature_names_out())
if __name__ == "__main__":
count_demo()

中文文本特征值抽取
from sklearn.feature_extraction.text import CountVectorizer
def count_chinese_demo():
data = ["我爱吃火锅", "我爱喝奶茶"]
# 1.实例化一个转换器类
transfer = CountVectorizer()
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
# CountVectorizer()不可以设置sparse矩阵
# toarray()方法可以将sparse矩阵转成二维数组
print("data_new:\n", data_new.toarray())
print("特征值名称:\n", transfer.get_feature_names_out())
if __name__ == "__main__":
count_chinese_demo()

中文自动把短句子当成了特征值,不能区分单词,要手动分割
data = ["我 爱 吃火锅", "我 爱 喝奶茶"]

停用词
stop_words停用的
可以手动写,也可以去找停用词表
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
data = ["life is short,i like python", "life is too long,i dislike python"]
# 1.实例化一个转换器类
# 加停用词
transfer = CountVectorizer(stop_words=["is", "too"])
# 2.调用fit_transform()
data_new = transfer.fit_transform(data)
# CountVectorizer()不可以设置sparse矩阵
# toarray()方法可以将sparse矩阵转成二维数组
print("data_new:\n", data_new.toarray())
print("特征值名称:\n", transfer.get_feature_names_out())
if __name__ == "__main__":
count_demo()
中文文本特征值抽取分词处理
用jieba进行分词
需要安装jieba库
pip install jieba
步骤
- 利用jieba.cut进行分词
- 实例化CountVectorizer
- 将分词结果变成字符串当做fit_transform的输入值
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def count_demo():
data = ["我超喜欢吃火锅,每天都去吃火锅", "我很讨厌吃芒果,我每天都不吃"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# 1.实例化一个转换器类
transfer = CountVectorizer()
# 2.调用fit_transform()
data_final = transfer.fit_transform(data_new)
# CountVectorizer()不可以设置sparse矩阵
# toarray()方法可以将sparse矩阵转成二维数组
print("data_new:\n", data_final.toarray())
print("特征值名称:\n", transfer.get_feature_names_out())
def cut_word(text):
return " ".join(list(jieba.cut(text)))
if __name__ == "__main__":
count_demo()

文本特征抽取TfidfVevtorizer
计算词的重要程度
关键词:在某一类别的文章中,出现的次数很多,但是在其他类别的文章中出现很少
Tf-idf文本特征提取用来衡量一个词的主要程度
idf计算公式:总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
tf-idf计算公式:
例如:有1000篇文章,有100篇文章出现了“非常”,文章A(100词):出现10次“非常”
tf:10/100 = 0.1
idf:
tf-idf:0.1
API
sklearn.feature_extraction.text.TfidfVectorizer(stop_words=None,...)
返回词的权重矩阵
TfidfVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象,返回值:sparse矩阵
TfidfVectorizer.inverse_transform(X) X:array数组或者sparse矩阵,返回值:转换之前数据格式
TfidfVectorizer.get_feature_names() 返回值:单词列表
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import jieba
def count_demo():
data = ["我超喜欢吃火锅,每天都去吃火锅", "我很讨厌吃芒果,我每天都不吃"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# 1.实例化一个转换器类
transfer = TfidfVectorizer()
# 2.调用fit_transform()
data_final = transfer.fit_transform(data_new)
# CountVectorizer()不可以设置sparse矩阵
# toarray()方法可以将sparse矩阵转成二维数组
print("data_new:\n", data_final.toarray())
print("特征值名称:\n", transfer.get_feature_names_out())
def cut_word(text):
return " ".join(list(jieba.cut(text)))
if __name__ == "__main__":
count_demo()
特征预处理
sklearn.preprocessing
为什么进行归一化/标椎化
要将不同规格的数据转换到同一规格(因为可能会出现一些数据过大一些数据过小)
无量纲化
归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
稳定性较差,只适用于传统精确小数据场景
公式


作用于每一列,max为一列的最大值,min为一列的最小值, 为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
API
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)...)
MinMaxScaler.fit_transform(X) X:numpy array格式的数据[n_samples,n_features],返回值:转换后的形状相同的array
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
def minmax_demo():
# 1.获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2.实例化一个转换器类
transfer = MinMaxScaler()
# 也可以自己去设定归一化范围
# transfer = MinMaxScaler(feature_range=[2,3])
# 3.调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
if __name__ == "__main__":
minmax_demo()
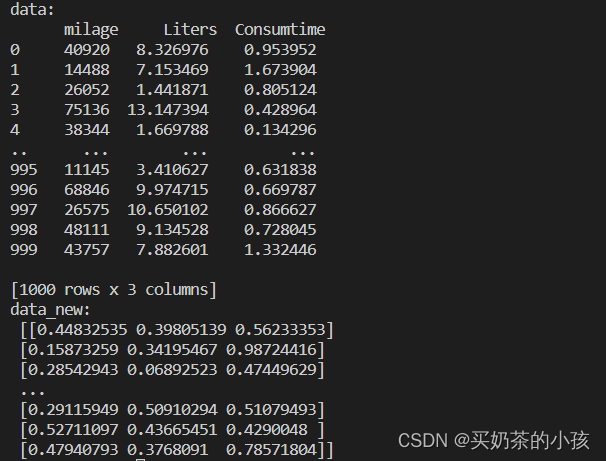
标准化
通过对原始数据进行变换把数据变换到均值为0,标准差为1的范围内
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景
公式

作用于每一列,mean为平均值,σ为标准差
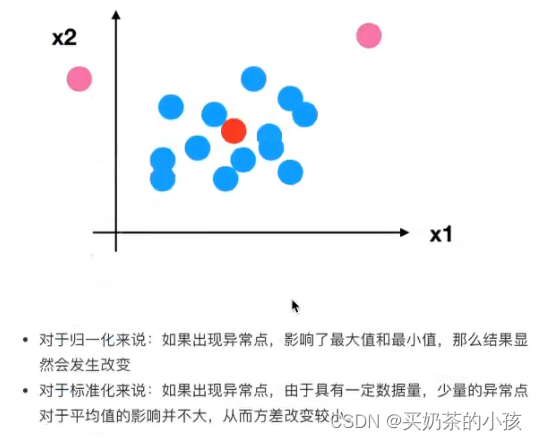
API
sklearn.preprocessing.StandardScaler()
- 处理之后,对于每列来说,所有数据都聚集在均值为0的附近,标准差为1
- StandardScaler.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
from sklearn.preprocessing import StandardScaler
import pandas as pd
def minmax_demo():
# 1.获取数据
data = pd.read_csv("dating.txt")
data = data.iloc[:, :3]
print("data:\n", data)
# 2.实例化一个转换器类
transfer = StandardScaler()
# 也可以自己去设定归一化范围
# transfer = MinMaxScaler(feature_range=[2,3])
# 3.调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
if __name__ == "__main__":
minmax_demo()
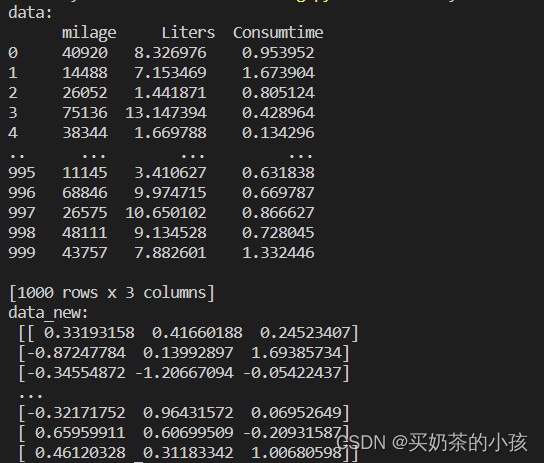
特征降维
降维
希望得到的特征是不相关的
维数:嵌套的层数
处理的对象是二维数组
- 此处的降维:降低特征的个数
- 效果:特征与特征之间不相关
方法
特征选择
方法
Filter(过滤式):主要探究特征本身的特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数:特征与特征之间的相关程度
Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
过滤式
低方差特征过滤
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
API
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
- 删除所有低方差特征
- Variance.fit_transform(X) X:nump array格式的数据[n_samples,n_features],返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
def minmax_demo():
# 1.获取数据
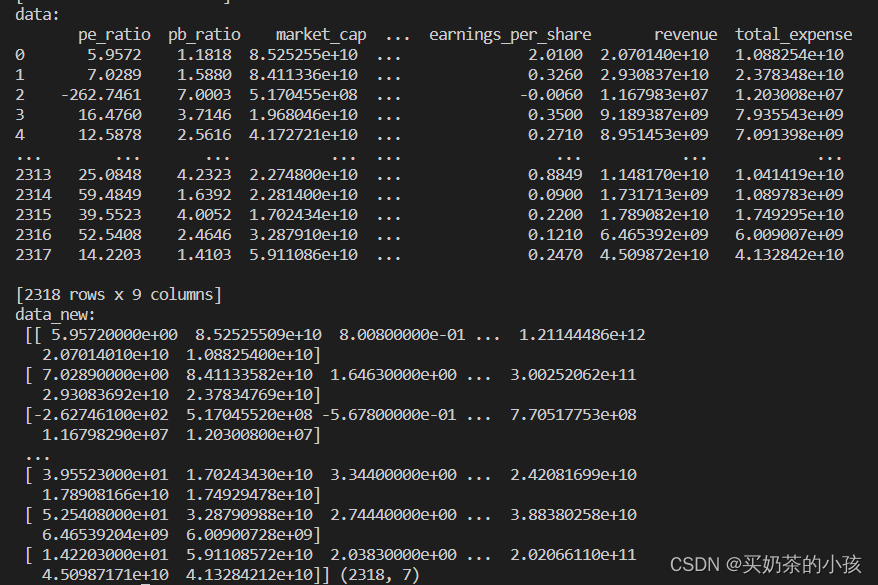
data = pd.read_csv("factor_returns.csv")
print("data:\n", data)
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2.实例化一个转换器类
transfer = VarianceThreshold(threshold=10)
# 3.调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
if __name__ == "__main__":
minmax_demo()
 相关系数
相关系数
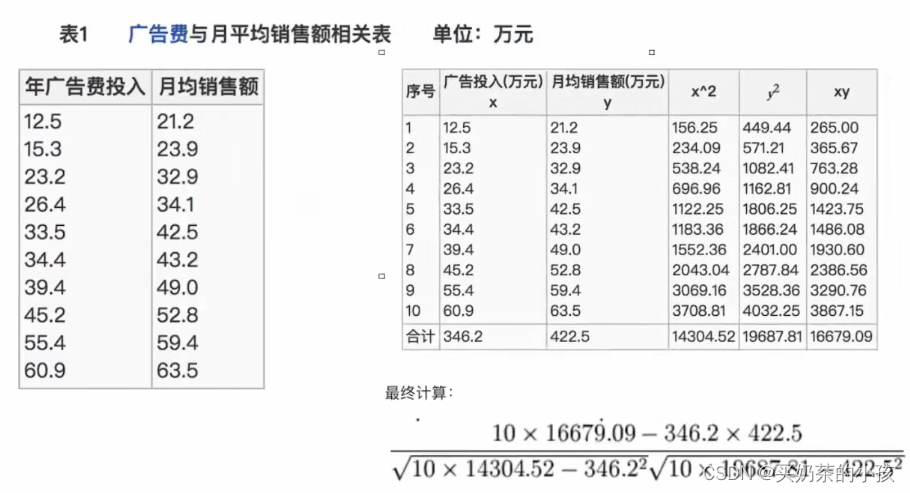
皮尔逊相关系数:反映变量之间相关关系密切程度的统计指标
公式

特点

API
from scipy.stats import pearsonr
x:(N,)array_like
y:(N,)array_like Returns:(Pearson’s correlation coefficient,p-value)
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
from scipy.stats import pearsonr
def minmax_demo():
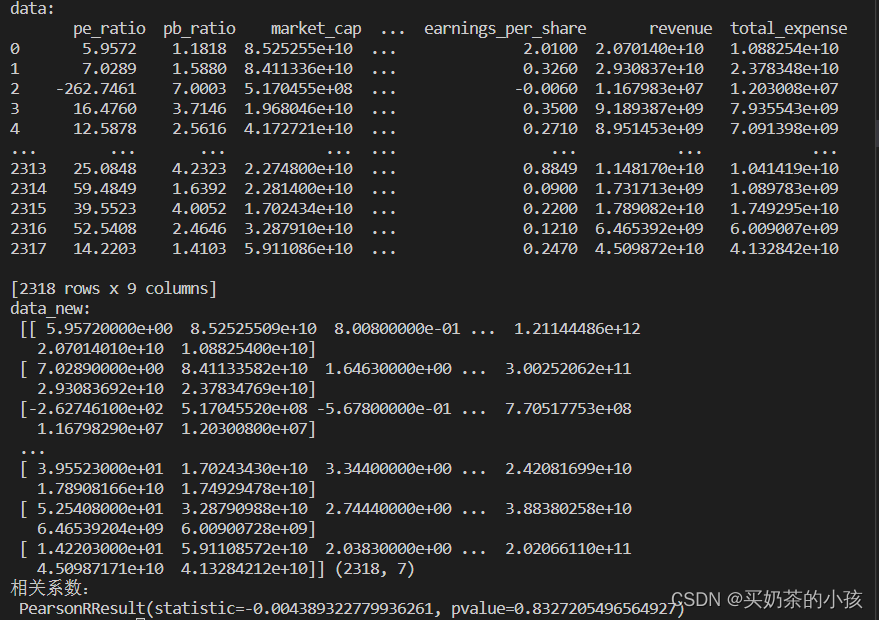
# 1.获取数据
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
print("data:\n", data)
# 2.实例化一个转换器类
transfer = VarianceThreshold(threshold=10)
# 3.调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new, data_new.shape)
# 计算某两个变量之间的相关系数
r = pearsonr(data["pe_ratio"], data["pb_ratio"])
print("相关系数:\n", r)
if __name__ == "__main__":
minmax_demo()
主成分分析(PCA)
what?
- 定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
- 作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息
- 应用:回归分析或者聚类分析
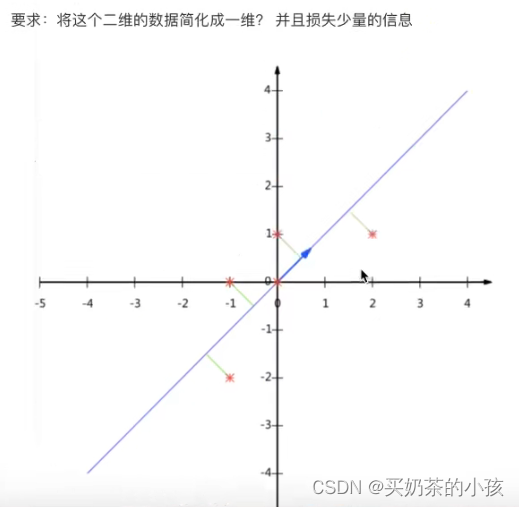

API
sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:小数:表示保留百分之多少的信息,整数:减少到多少特征(降到几维)
- PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
from sklearn.decomposition import PCA
def pca_demo():
data = [[2,0,3,9], [3,2,6,5], [7,5,1,8]]
# 1.实例化一个转换器类
# 意思是将4维降到2维
transfer = PCA(n_components=2)
# 2.调用fit_transform
data_new = transfer.fit_transform(data)
print("new_data:\n", data_new)
if __name__ == "__main__":
pca_demo()

案例:探究用户对物品类别的喜好细分降维

步骤
- 需要将user_id和aisle放在同一张表中---合并
- 找到user_id和aisle---交叉表和透视表
- 特征冗余过多---PCA降维
from sklearn.decomposition import PCA
import pandas as pd
def pca_demo():
# 1.读取文件
order_products = pd.read_csv("order_products__prior.csv")
products = pd.read_csv("products.csv")
orders = pd.read_csv("orders.csv")
aisles = pd.read_csv("aisles.csv")
# 2.合并表
tb1 = pd.merge(order_products, products, on=["product_id", "product_id"])
tb2 = pd.merge(tb1, orders, on=["order_id", "order_id"])
tb3 = pd.merge(tb2, aisles, on=["aisle_id","aisle_id"])
# 3.找到user_id和aisle之间的关系,用到交叉表
table = pd.crosstab(tb3["user_id"], tab3["aisle"])
data = table[:1000]
# 4.PCA消除冗余
transfer = PCA(n_components=0.95)
data_new = transfer.fit_transform(data)
print("new_data:\n",data_new)
if __name__ == "__main__":
pca_demo()