一.什么是二叉搜索树
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
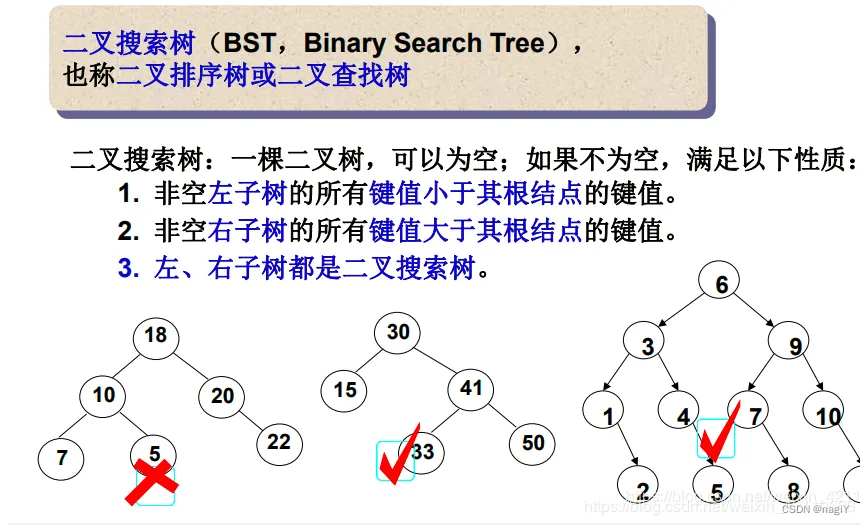
根据二叉搜索树的性质,它的中序遍历结果就是一个升序列。
二.二叉搜索树的模拟实现
节点 Node
在实现二叉搜索树之前,要先定义一个节点,成员变量包括左指针(left),右指针(right)和一个值 (key)
template<class K>
struct BSTNode
{
BSTNode<K>* _left;
BSTNode<K>* _right;
K _key;
BSTNode(const K& key) //构造函数
:_left(nullptr)
,_right(nullptr)
,_key(key)
{}
};
打印 InOrder
打印二叉搜索树树,就是对树进行中序遍历。
这里有个小技巧,可以不用写 Getroot 函数就可以使用到类里面的成员变量:
就是在函数里再套一个函数;
具体看代码实现:
void InOrder() //函数里面再套一个函数,真正实现中序遍历的是 _InOrder函数
{
_InOrder(_root);
cout << endl;
}
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
插入 insert
在插入时,如果要插入的数据(key)已经存在,则返回false,若不存在,则完成插入操作,然后返回true。
其实这刚好也完成了去重的操作。
插入操作:
定义一个parent指针,记录当前节点的父节点,方便最后插入节点时的链接。
定义一个cur指针,用于遍历整个树。
根据二叉搜素树的性质:
当key小于节点的 _key 时,更新parent,就到树的左边;
当key大于节点的 _key 时,更新parent,就到树的右边;
当cur为空时,跳出循环,进行节点间的链接操作(同样遵循二叉搜索树的性质)
bool Insert(const K& key)
{
if (_root == nullptr) //注意树为空的情况
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
return false;
}
cur = new Node(key);
if (parent->_key<key) //链接
{
parent->_right = cur;
}
else
parent->_left = cur;
return true;
}
插入的递归实现 insertR
既然要递归,那么肯定要用到根节点,同样使用中序遍历那样的方式,函数里再套一个函数。
其实理论还是和非递归的一样,只不过换成了调用函数,但这里有个小窍门,就是我们可以传根节点的引用,这样就不用定义一个父节点指针了,根据引用的特性,引用是一个变量的别名,当我们递归到下一层时,此时传过来的root就是这一层的父节点,直接链接就行了。
bool insertR(const K& key)
{
return _insertR(_root, key);
}
bool _insertR(Node*& root, const K& key)
{
if (root == nullptr)
{
Node* newroot = new Node(key);
root = newroot;
return true;
}
if (root->_key < key)
{
return _insertR(root->_right, key);
}
else if (root->_key > key)
{
return _insertR(root->_left, key);
}
else
return false;
}
删除 erase
删除就有点复杂了,它分几种情况:
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情
况:
1.要删除的结点无孩子结点
2. 要删除的结点只有左孩子结点
3. 要删除的结点只有右孩子结点
4. 要删除的结点有左、右孩子结点
前三种情况倒好解决,如果待删除的节点只有一个孩子,那么只需要把这个孩子根据二叉搜索树的性质托孤给它的父节点。


很显然,当有两个孩子时,托孤就行不通了,那么我们可不可以重新找一个符合条件的节点来充当父节点 ?
答案当然是可以,这就是替换法。
替换法:
找左子树的最大节点(在最右边),或是右子树的最小节点(在最左边)。
代码实现:
bool erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur) //先查找待删除节点,没找到则返回false
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else //找到了
{
if (cur->_left == nullptr) //有一个孩子,且左子树为空
{
if (parent == nullptr) //如果待删除节点是根节点,那么parent为空
{
_root = cur->_right;
return true;
}
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
parent->_right = cur->_right;
}
else if (cur->_right == nullptr) //有一个孩子,且右子树为空
{
if (parent == nullptr) //如果待删除节点是根节点,那么parent为空
{
_root = cur->_left;
}
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
parent->_right = cur->_left;
}
else //有两个孩子,替换法,这里是寻找左子树的最大节点
{
Node* parent = cur;
Node* leftmax = cur->_left;
while (leftmax->_right) //找左子树最大的
{
parent = leftmax;
leftmax = leftmax->_right;
}
std::swap(leftmax->_key, cur->_key); //交换值
if (parent->_left == leftmax)
{
parent->_left = leftmax->_left;
}
else
parent->_right = leftmax->_left;
cur = leftmax;
}
delete cur; //删除节点
return true;
}
}
return false; //没找到返回false
}
删除的递归实现 eraseR
同样使用函数套函数的方式。同样传root的引用。
当有一个孩子或没有孩子的时候,可以直接链接,然后再删除;
当有两个孩子的时候,同样使用替换法,找到左子树的最大节点(或是右子树的最小节点),此时这个最大节点(或是最小节点)一定没有孩子,再递归一次,转换成没有孩子的情况。
bool eraseR(const K& key)
{
return _eraseR(_root, key);
}
bool _eraseR(Node*& root, const K& key)
{
if (root == nullptr) //没找到
return false;
if (root->_key < key) //开始寻找待删除节点
{
return _eraseR(root->_right, key);
}
else if (root->_key > key)
{
return _eraseR(root->_left, key);
}
else //找到了待删除节点
{
Node* del = root;
if (root->_left == nullptr) //有一个叶节点或没有叶节点
{
root = root->_right;
}
else if (root->_right == nullptr)
{
root = root->_left;
}
else //有两个叶节点
{
Node* leftmax = root->_left;
while (leftmax->_right)
{
leftmax = leftmax->_right;
}
std::swap(leftmax->_key, root->_key);
return _eraseR(root->_left, key); //注意这里要传root->left,不能传leftmax,否
//则链接关系会对不上
}
delete del; //删除节点
return true;
}
}
剩下接口
剩下的操作(查找find ,拷贝构造,重载赋值运算符,析构函数)都很简单了,就不一一讲述,都放在源码里了。
三.源码
Binary_Search_Tree.h
template<class K>
struct BSTNode
{
BSTNode<K>* _left;
BSTNode<K>* _right;
K _key;
BSTNode(const K& key) //构造函数
:_left(nullptr)
,_right(nullptr)
,_key(key)
{}
};
template<class K>
class BSTree
{
typedef BSTNode<K> Node;
public:
BSTree() //构造函数
:_root(nullptr)
{}
void InOrder() //函数里面再套一个函数,真正实现中序遍历的是 _InOrder函数
{
_InOrder(_root);
cout << endl;
}
bool Insert(const K& key)
{
if (_root == nullptr) //注意树为空的情况
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
return false;
}
cur = new Node(key);
if (parent->_key<key) //链接
{
parent->_right = cur;
}
else
parent->_left = cur;
return true;
}
bool insertR(const K& key) //插入的递归实现
{
return _insertR(_root, key);
}
bool erase(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur) //先查找待删除节点,没找到则返回false
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else //找到了
{
if (cur->_left == nullptr) //有一个孩子,且左子树为空
{
if (parent == nullptr) //如果待删除节点是根节点,那么parent为空
{
_root = cur->_right;
return true;
}
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else
parent->_right = cur->_right;
}
else if (cur->_right == nullptr) //有一个孩子,且右子树为空
{
if (parent == nullptr) //如果待删除节点是根节点,那么parent为空
{
_root = cur->_left;
}
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else
parent->_right = cur->_left;
}
else //有两个孩子,替换法,这里是寻找左子树的最大节点
{
Node* parent = cur;
Node* leftmax = cur->_left;
while (leftmax->_right) //找左子树最大的
{
parent = leftmax;
leftmax = leftmax->_right;
}
std::swap(leftmax->_key, cur->_key); //交换值
if (parent->_left == leftmax)
{
parent->_left = leftmax->_left;
}
else
parent->_right = leftmax->_left;
cur = leftmax;
}
delete cur; //删除节点
return true;
}
}
return false; //没找到返回false
}
bool eraseR(const K& key) //删除的递归实现
{
return _eraseR(_root, key);
}
bool find(const K& key) //查找
{
Node* cur = _root;
while (cur)
{
if (cur->_key < key)
{
cur = cur->_right;
}
else if (cur->_key > key)
{
cur = cur->_left;
}
else
return true;
}
return false;
}
bool findR(const K& key) //查找的递归实现
{
return _findR(_root, key);
}
~BSTree() //析构函数
{
destroy(_root);
}
BSTree(const BSTree<K>& bst) //拷贝构造
{
_root = copy(bst._root);
}
BSTree<K>& operator=(BSTree<K> bst) //赋值重载
{
std::swap(_root, bst._root);
return *this;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
bool _insertR(Node*& root, const K& key)
{
if (root == nullptr)
{
Node* newroot = new Node(key);
root = newroot;
return true;
}
if (root->_key < key)
{
return _insertR(root->_right, key);
}
else if (root->_key > key)
{
return _insertR(root->_left, key);
}
else
return false;
}
bool _eraseR(Node*& root, const K& key)
{
if (root == nullptr) //没找到
return false;
if (root->_key < key) //开始寻找待删除节点
{
return _eraseR(root->_right, key);
}
else if (root->_key > key)
{
return _eraseR(root->_left, key);
}
else //找到了待删除节点
{
Node* del = root;
if (root->_left == nullptr) //有一个叶节点或没有叶节点
{
root = root->_right;
}
else if (root->_right == nullptr)
{
root = root->_left;
}
else //有两个叶节点
{
Node* leftmax = root->_left;
while (leftmax->_right)
{
leftmax = leftmax->_right;
}
std::swap(leftmax->_key, root->_key);
return _eraseR(root->_left, key); //注意这里要传root->left,不能传leftmax,否
//则链接关系会对不上
}
delete del; //删除节点
return true;
}
}
Node* copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* copyroot = new Node(root->_key);
copyroot->_left = copy(root->_left);
copyroot->_right = copy(root->_right);
return copyroot;
}
bool _findR(Node* root, const K& key)
{
if (root == nullptr)
return false;
if (root->_key < key)
return _findR(root->_right, key);
else if (root->_key > key)
return _findR(root->_left, key);
else
return true;
}
void destroy(Node* root) //后序删除
{
if (root == nullptr)
return;
destroy(root->_left);
destroy(root->_right);
delete root;
root = nullptr;
}
private:
Node* _root;
};
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)