第一章 绪论
(一)课程内容
1 大数据安全
- 如何在满足可用性的前提下实现大数据机密性
安全与效率之间的平衡一直信息安全领域关注的重要问题。在大数据场景下,数据的高速流动特性以及操作多样性使得数据的安全与效率之间的矛盾更加突出。
- 如何实现大数据的安全共享
在大数据访问控制中,用户难以信赖服务商正确实施访问控制策略,且在大数据应用中实现用户角色与权限划分更为困难。
- 如何实现大数据真实性验证与可信溯源
当一定数量的虚假信息混杂在真实信息之中时,往往容易导致人们误判。(例如:点评网站上的虚假评论)最终影响数据分析结果的准确性。需要基于数据的来源真实性、传播途径、加工处理过程等,了解各项数据可信度,防止分析得出无意义或者错误的结果。
2 大数据隐私保护
- 由于去匿名化技术的发展,实现身份匿名越来越困难
仅数据发布时做简单的去标识处理已经无法保证用户隐私安全,通过链接不同数据源的信息,攻击者可能发起身份重识别攻击,逆向分析出匿名用户的真实身份,导致用户的身份隐私泄露。
- 基于大数据对人们状态和行为的预测带来隐私泄露威胁
随着深度学习等人工智能技术快速发展,通过对用户行为建模与分析,个人行为规律可以被更为准确的预测与识别,刻意隐藏的敏感属性可以被推测出来。
3 区别与联系@
- 大数据安全需求更为广泛,关注的目标不仅包括数据机密性,还包括数据完整性、真实性、不可否认性,以及平台安全、数据权属判定等。
而隐私保护需求一般仅聚焦于匿名性。
- 虽然隐私保护中的数据匿名需求与安全需求之一的机密性需求看上去比较类似,但后者显然严格得多。
-
匿名性仅防止攻击者将已公布的信息与现实中的用户联系起来,
- 而机密性则要求数据对于非授权用户完全不可访问。
- 在大数据安全问题下,一般来说数据对象是有明确定义。
而在涉及隐私保护需求时,所指的用户“隐私”则较为笼统,可能具有多种数据形态存在。
| 大数据安全 |
隐私保护 |
|
数据机密性、数据完整性、真实性、不可否认性,以及平台安全,数据权属判定 |
匿名性 |
| 安全需求的机密性:要求数据对于非授权用户完全不可访问 |
数据匿名需求:防止攻击者将已公布的信息与现实中的用户联系起来 |
| 数据对象是有明确定义
|
所指的用户“隐私”则较为笼统,可能具有多种数据形态存在
|
(二)基本知识:基本密码学
1 安全需求
-
机密性(Confidentiality):信息不泄露给非授权的用户
例:访问系统的BLP模型、泄密
-
完整性(Integrity):信息不被非法修改
例:访问系统的Biba模型、修改内容
-
可用性(Availability):信息系统能正确和及时地为合法用户提供服务的能力
例:dos/ddos攻击、流量分析
-
可鉴别性(Authentication):接收者能鉴别和识别信息的来源
例:破坏数据包收到的先后顺序、冒名顶替
-
抗抵赖性(Non-repudiation):生产信息的人不能事后否认该生产
例:不承认发送过某个文件
2 加密技术
(1) 相关定义
传统加密技术的主要目标是保护数据的机密性。
一个加密算法被定义为一对数据变换,其中一个变换应用于数据的起源项,称为明文;所产生的相应数据项称为密文。这个变换称为加密变换。而另一个变换应用于密文,恢复出明文,称为解密变换。
- 加密变换;密文=加密变换(明文,加密密钥)
- 解密变换;明文=解密变换(密文,解密密钥)
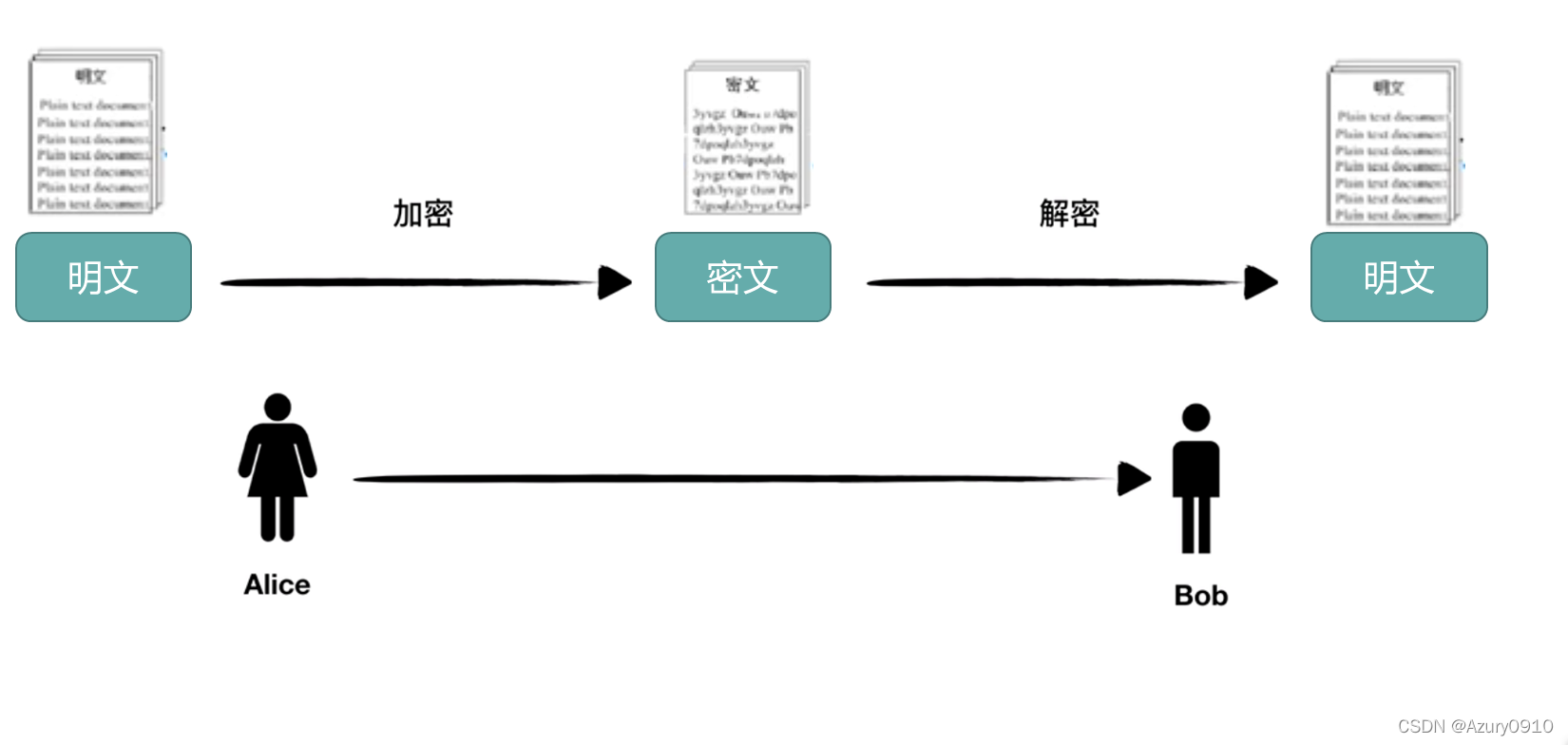
明文和密钥通常都可以用比特串的形式存储;但密文较长,密钥较短。
(2) 对称加密技术
加密和解密密钥相同,或可以互相推导。就像需要用钥匙才能锁上的门锁。
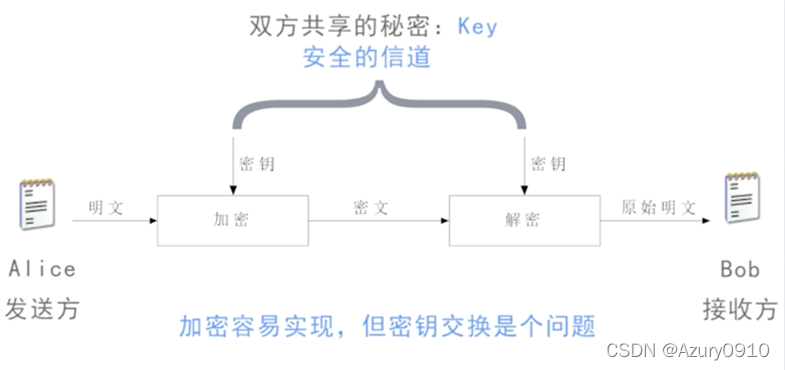
具备机密性、可鉴别性、完整性;不保证抗抵赖性。
机密性:
可鉴别性:

完整性:
抗抵赖性:
由于数字世界中,复制件和原件是无法区分的,因此加密者和解密者对密文有相同的生产能力。
(3) 非对称加密技术(公钥加密)
采用两个不同的密钥将加密和解密功能分开。
- 一个密钥称为私钥,像对称密码中一样,该密钥被秘密保存。
- 另一个密钥称为公钥,不需要保密。
公钥密码必须具有如下重要特性:给定公钥,要确定出私钥在计算上是不可行的。就像常见的门,锁门很容易,但开门需要钥匙。
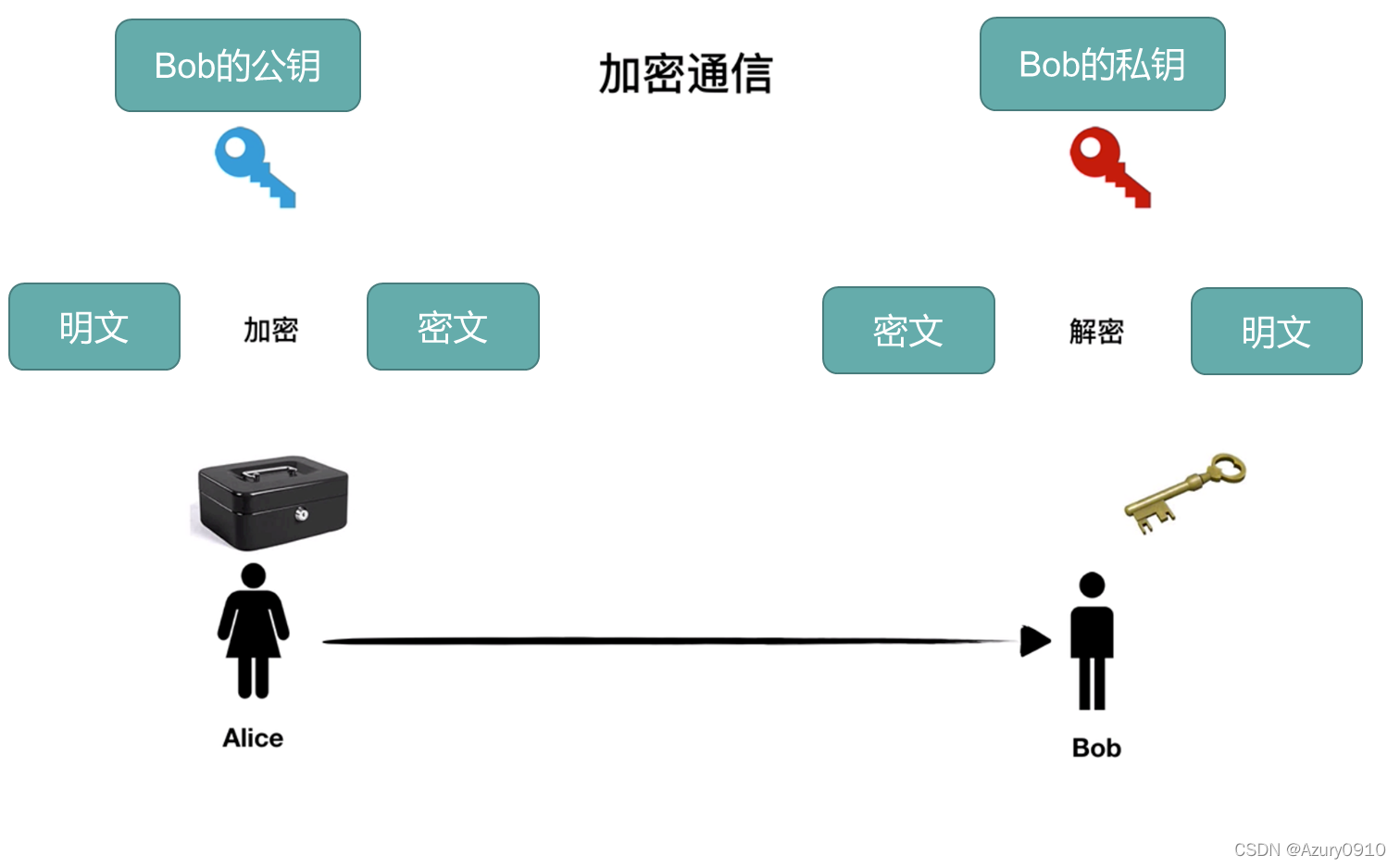
非对称加密技术的六要素:
- 明文
- 密文
- 公开密钥(记作PU或KU)Public Key
- 私有密钥(记作PR或KR)Private Key
- 加密算法
- 解密算法
Tip:
-
接收方B容易通过计算产生一对密钥(公开密钥
K
U
b
KU_b
KUb,私有密钥
K
R
b
KR_b
KRb)
-
发送方A容易计算产生密文
C
=
E
K
U
b
(
M
)
C=E_{KU_b} (M)
C=EKUb(M)
-
接收方B容易通过计算解密密文
M
=
D
K
R
b
(
C
)
=
D
K
R
b
[
E
K
U
b
(
M
)
]
M=D_{KR_b}(C)=D_{KR_b}[E_{KU_b}(M)]
M=DKRb(C)=DKRb[EKUb(M)]
- 敌对方即使知道公开密钥
K
U
b
{KU}_b
KUb,要确定私有密钥
K
R
b
{KR}_b
KRb在计算上不可行
敌对方即使知道公开密钥
K
U
b
KU_b
KUb和密文
C
C
C,要计算明文
M
M
M在计算上不可行
- 密钥对互相之间可交换使用
M
=
D
K
R
b
[
E
K
U
b
(
M
)
]
=
D
K
U
b
[
E
K
R
b
(
M
)
]
M=D_{KR_b}[E_{KU_b}(M)]=D_{KU_b} [E_{KR_b}(M)]
M=DKRb[EKUb(M)]=DKUb[EKRb(M)]
对比
| 项目 |
对称加密技术 |
非对称加密技术 |
| 特征 |
双方信息对等 |
双方信息不对等,根据公钥计算私钥是困难的
|
| 条件 |
实现密钥交换 |
不需要密钥交换 |
| 效果 |
保证机密性、可鉴别性、完整性;不保证抗抵赖性
|
保证机密性;不保证可鉴别性、抗抵赖性、完整性 |
| 缺点 |
/ |
解密加密效率低 |
| 密钥个数 |
n个人两两秘密通信需要 n(n-1)/2个密钥 |
n个人两两秘密通信需要n对密钥 |
(4) 混合加密技术@
为克服非对称加密技术的缺点——解密加密效率低
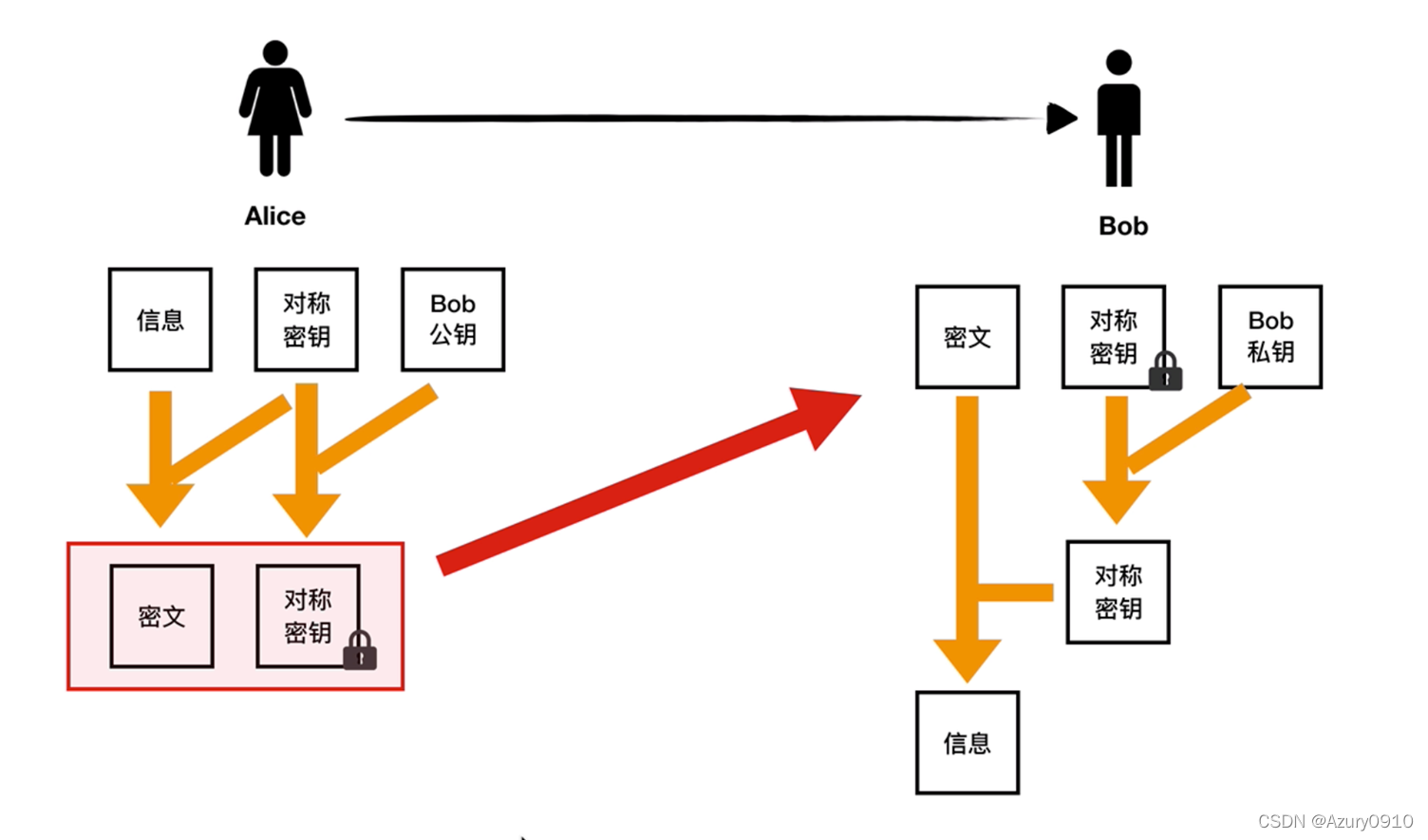
发送者A用对称密钥加密明文,用公钥加密对称密钥,接受者B用私钥解密对称密钥,用对称密钥解密密文得到信息。
- B将公钥传递给A;
- A用对称密钥对待传递的消息加密,并使用B的公钥加密该对称密钥;
- A将对称加密后的消息和公钥加密后的对称密钥传给B;
- B用自己的私钥对加密后的对称密钥解密,得到对称密钥;
- B用解密得到的对称密钥对加密后的消息解密,得到A传递来的消息。
3 数字签名技术
数字签名的目的是证明文件归签名者所有
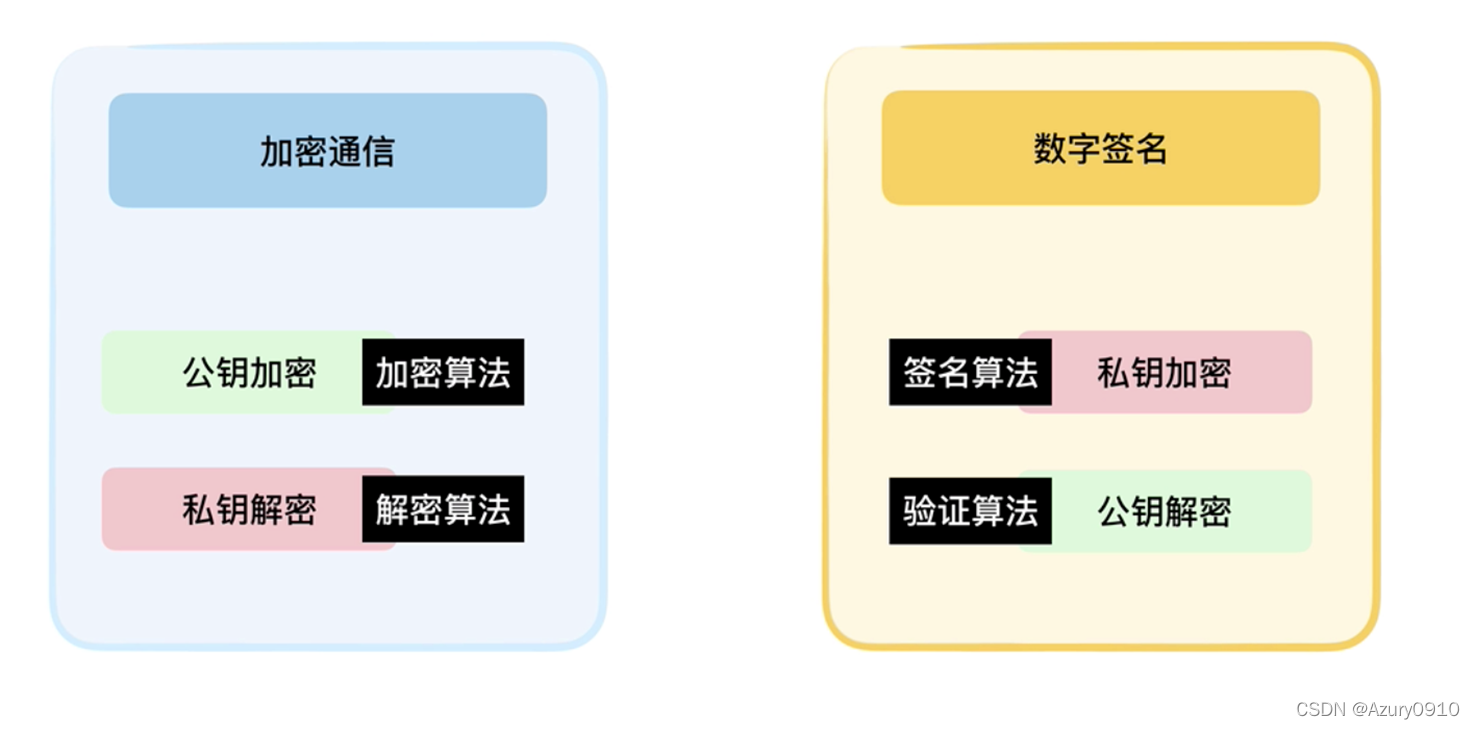
- 可鉴别性
在不知道签名者私钥的情况下,任何其他人都不能伪造签名。因此前面可用于鉴别签名者。
- 抗抵赖性
签名者无法否认自己对消息对签名。
- 完整性
任何消息的更改都将导致签名无法通过验证。
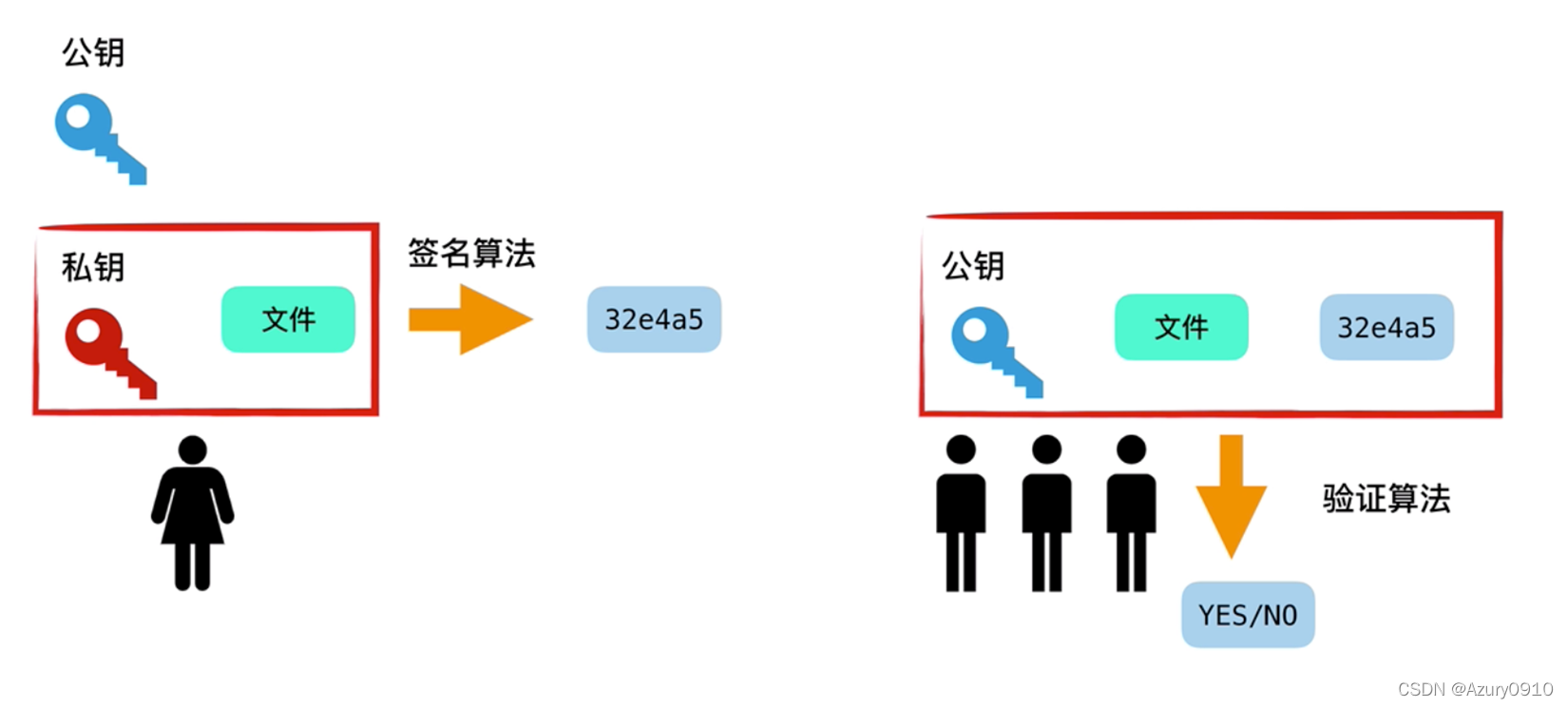
非对称加密技术保证信息的机密性,数字签名保证可鉴别性、抗抵赖性、完整性。
是否存在一种方法,同时满足四条性质?
答:先私钥后公钥
4 Hash和MAC技术
(1)Hash函数
Hash函数(也称哈希函数)可将任意长的消息压缩为固定长度的Hash值,Hash函数需满足如下性质:
-
单向性:从Hash值得到原消息是计算上不可行的
-
抗碰撞性:找到两个不同的报文Hash值相同,是计算上不可行的。
可用于文件完整性检验,密码保存,软件下载等场景。
不使用密码,任何人都可以计算,因此不能避免恶意篡改。比如在流氓软件的场景中,可以通过同时修改软件和Hash的方式实现恶意篡改。
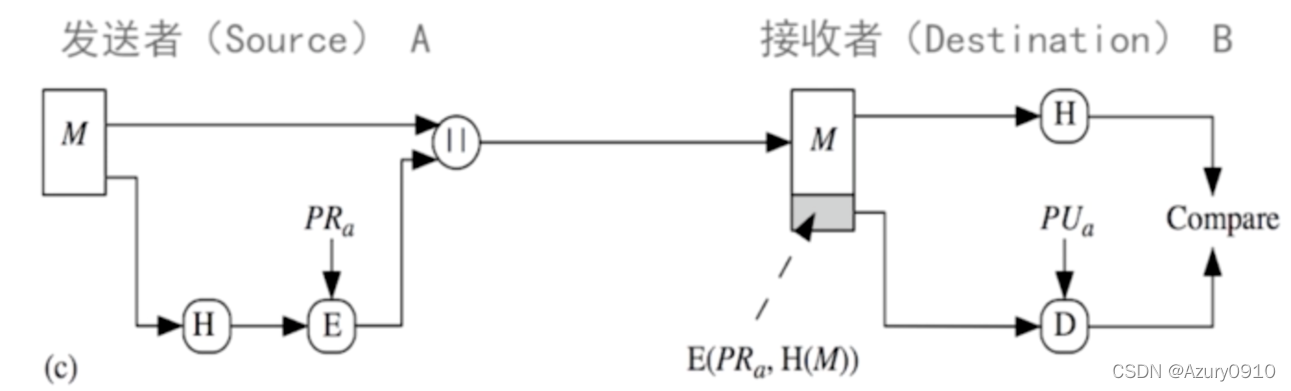
Hash通常和非对称密码技术配合实现数字签名,避免用私钥加密明文而导致的效率低下。保证完整性、可鉴别性、抗抵赖性。
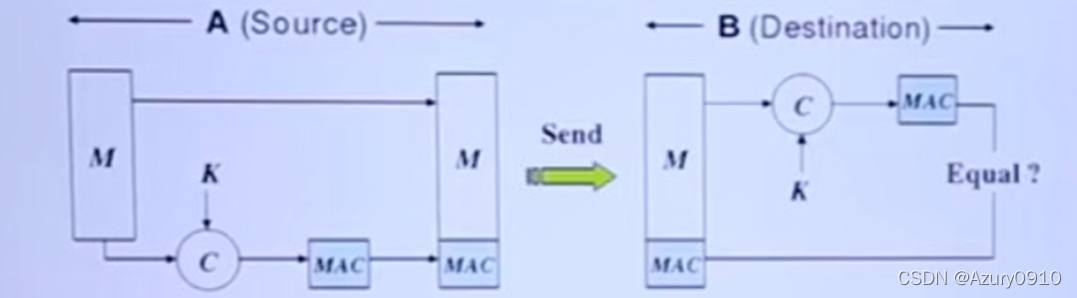
(2) MAC
MAC(Message Authentication Code,消息认证码/报文鉴别码)基于一个大尺寸数据生产一个小尺寸数据,在性能上也需要避免碰撞,但MAC算法有对称密钥参与,计算结果类似于一个加密的Hash值。
保证可鉴别性和完整性,不能抗抵赖(因为使用了对称密钥)。
| 加密技术 |
机密性 |
可鉴别性 |
完整性 |
抗抵赖性 |
| 对称加密技术 |
√ |
√ |
√ |
× |
| 非对称加密技术 |
√ |
× |
× |
× |
| Hash+非对称密码技术 |
- |
√ |
√ |
√ |
| MAC+对称加密技术 |
√ |
√ |
√ |
× |
5 密钥交换技术
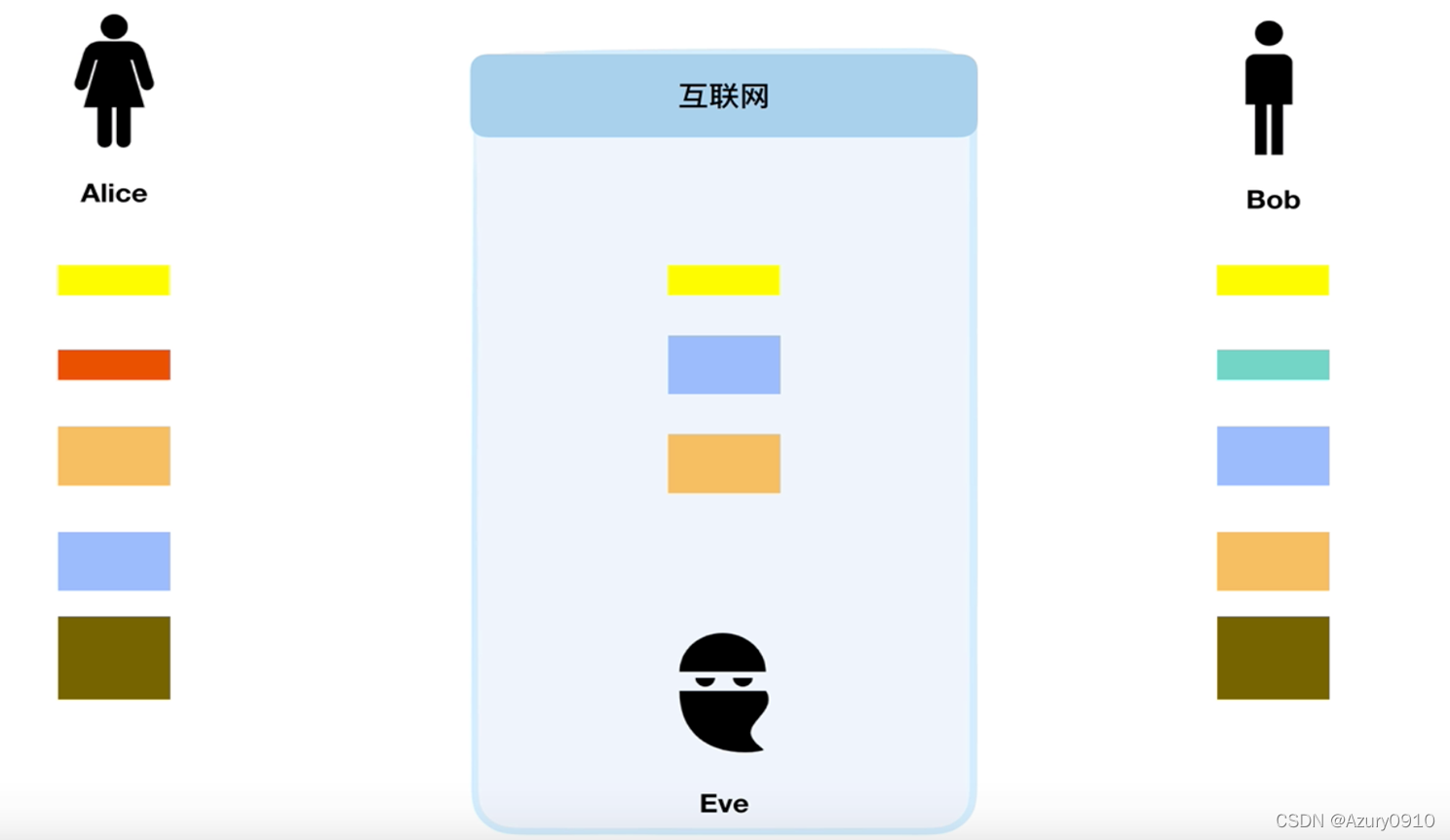
首先假设双方分别是Alice和Bob,他们就一个随机的初始的颜色达成了一致。这个颜色不需要被保密,但是每一次要不一样。在这个例子中,这个初始的颜色是黄色。然后他们两个人每一个人选择一个秘密的颜色,Alice只知道Alice的颜色,其他任何人都不知道Alice选的是什么颜色,Bob同理。在这个例子中,Alice选择的是红色,Bob选择的是蓝绿色。这个过程的关键部分是Alice和Bob每个人将他们自己的秘密颜色和他们对方彼此共享的颜色(初始的颜色即黄色)混合在一起,导致了分别是orang-tan色,和浅蓝色。他们公开的将混合之后的颜色进行交换。最终,他们每一个人将他们从对方收到的颜色和他们自己的private color进行混合。这个结果就是最终的混合颜色。在这个例子中是黄褐色。这个颜色和对方的颜色是一致的。
如果某个第三方听到了这个交换,他就会知道公共的颜色(黄色)和第一个混合的颜色(orange-tan和浅蓝色),但是对这个第三方来说,确定最终的秘密颜色(黄褐色)在计算上是很困难的。事实上,当在使用大的数字而不是颜色时,这个行为需要大量的计算。这个行为即使是现代超极计算机都是不可能在一个合理的时间内完成的。

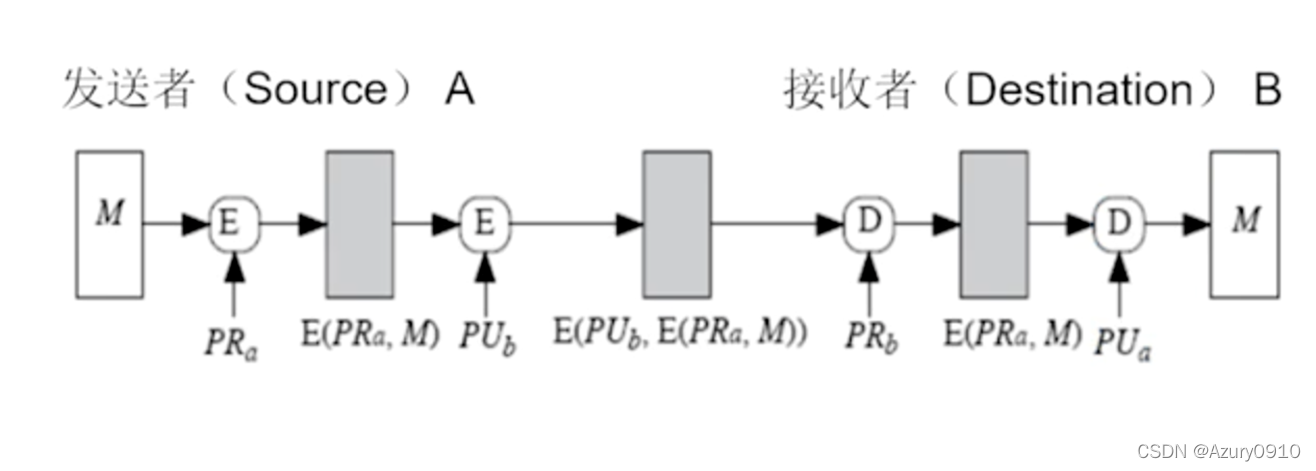
6 数字签名技术和非对称加密技术的混合使用 @
记Alice的公私钥对为
(
P
U
a
,
P
R
a
)
(PU_a,PR_a)
(PUa,PRa),Bob的公私钥对为
(
P
U
b
,
P
R
b
)
(PU_b,PR_b)
(PUb,PRb)
- Alice用自己的私钥对明文
M
M
M加密得到
E
(
P
R
a
,
M
)
E(PR_a,M)
E(PRa,M),对明文进行签名;
- Alice再用Bob的公钥对签名后的消息加密,得到
E
(
P
U
b
,
E
(
P
R
a
,
M
)
)
E(PU_b,E(PR_a,M))
E(PUb,E(PRa,M));
- Alice将
E
(
P
U
b
,
E
(
P
R
a
,
M
)
)
E(PU_b,E(PR_a,M))
E(PUb,E(PRa,M))发送给Bob;
- Bob接收后,先用自己的私钥解密,得到
D
(
P
R
b
,
E
(
P
U
b
,
E
(
P
R
a
,
M
)
)
)
=
E
(
P
R
a
,
M
)
D(PR_b,E(PU_b,E(PR_a,M)))=E(PR_a,M)
D(PRb,E(PUb,E(PRa,M)))=E(PRa,M);
- 最后,Bob用Alice的公钥对解密后的消息
E
(
P
R
a
,
M
)
E(PR_a,M)
E(PRa,M)进行解密运算,得到
D
(
P
U
a
,
E
(
P
R
a
,
M
)
)
=
M
D(PU_a, E(PR_a,M))=M
D(PUa,E(PRa,M))=M,以获取明文
M
M
M并验证签名。
第二章 安全存储与访问控制技术
背景:Unix系统的权限管理
Unix是一个多用户操作系统,需要保证许多用户同时访问操作系统服务,这就要求系统具有高度安全性和隐私性。
Unix对每个用户分配唯一的用户号(UID),多个用户组成用户组,每个组分配一个组号(GID)。
系统管理员可以将用户分到组中,用户也可以属于多个组,Unix中的每个进程具有拥有者的UID和GID。
文件的权限有三种,读(r)、写(w)和执行(x)。下面为Unix文件权限的示例:
| 符号表示 |
含义 |
| rwx------ |
仅拥有者可以读、写、执行 |
| rwxr-xr-x |
拥有者可以读、写、执行;其他用户可以读和执行 |
| r-x—r-x |
拥有者和其他用户可以读和执行,同组其他用户没有权限 |
| rw-r----- |
拥有者可以读写,同组其他用户可读 |
字符每组依次为所有者、同组其他用户、其他用户
(一)早期访问控制技术
1 几个基本概念@引用监控机、主体、客体、操作、访问权限
早期的访问控制技术都是建立在可信引用监控机基础上的。引用监控机是在1972年由Anderson首次提出的抽象概念,它能够对系统中的主体和客体之间的授权访问关系进行监控。当数据存储系统中存在一个所有用户都信任的引用监控机时,就可以由它来执行各种访问控制策略,以实现客体资源的受控共享。
访问控制策略是对系统中用户访问资源行为的安全约束需求的具体描述。
引用监控机(Reference Monitor,RM):指系统中监控主体和客体之间授权访问关系的部件。
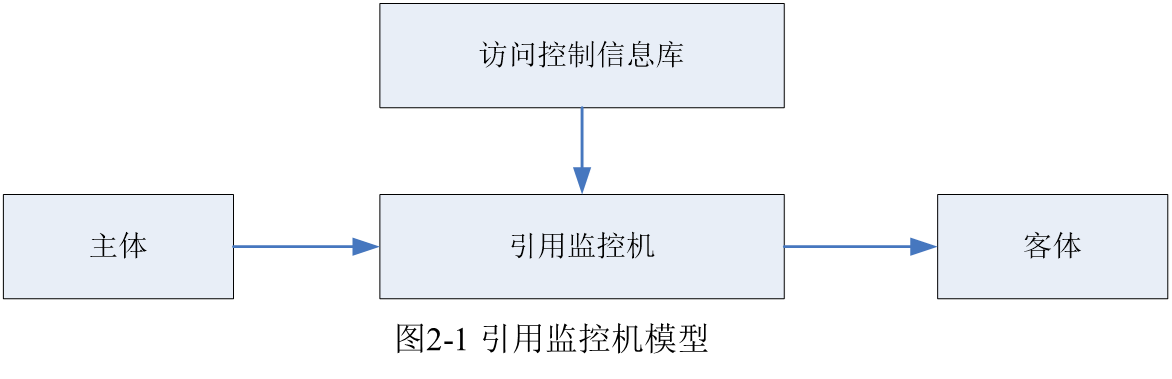
一般来说,这类访问控制技术都涉及如下的概念:
-
主体:能够发起对资源的访问请求的主动实体,通常为系统的用户或进程。
-
客体:能够被操作的实体,通常是各类系统和数据资源。
-
操作:主体对客体的读、写等动作行为。
-
访问权限:客体及对其的操作形成的二元组
<操作,客体>。
2 访问控制模型
访问控制模型的发展历史
在20世纪70年代,大型资源共享系统出现在政府和企业中。为了应对系统中的资源安全共享需求,访问控制矩阵等①自主访问控制模型和BLP、Biba等②强制访问控制模型被提出,并得到了广泛应用。
在20世纪80年代末到90年代初,人们发现在商业系统按照工作或职位来进行访问权限的管理更加方便。因此,③基于角色的访问控制模型被提出,并发展成为迄今为止在企业或组织中应用最为广泛的访问控制模型之一。
在21世纪初期,互联网技术使得用户对资源的访问处于开放环境。开放环境往往无法预先获得主客体身份的全集,且存在身份隐藏的需求。因此,④基于属性的访问控制被提出,它通过安全属性来管理授权,而不需要预先指导访问者身份。
(1)自主访问控制模型
客体的属主决定主体对客体的访问权限。可以被表述为
(
S
,
O
,
A
)
(S,O,A)
(S,O,A)三元组。其中,
S
S
S表示主体(subject)集合,
O
O
O表示客体(object)集合,且
S
⊂
O
S⊂O
S⊂O。
A
A
A表示访问(Access)矩阵,
A
(
s
i
,
o
j
)
A(s_i,o_j)
A(si,oj)则表示主体
s
i
s_i
si能够对客体
o
j
o_j
oj执行的操作权限。
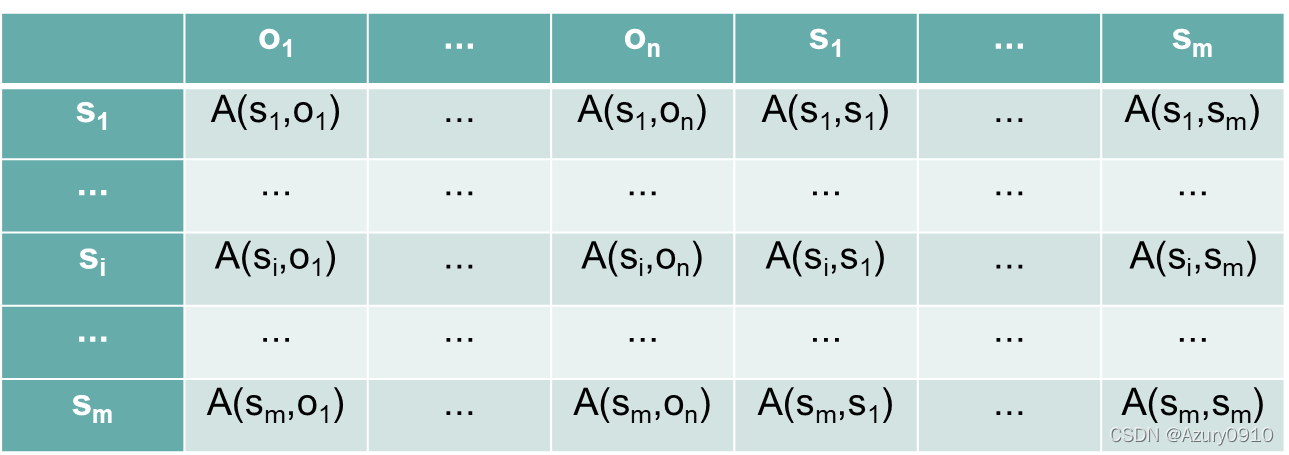
访问矩阵中的一行,代表某个主体对系统中所有客体的访问权限信息,一列代表所有主体对某个客体的访问权限信息。
自主访问控制模型的实施由RM根据访问矩阵A进行判定,而数据的所有者对权限的管理通过修改访问矩阵A来实现。
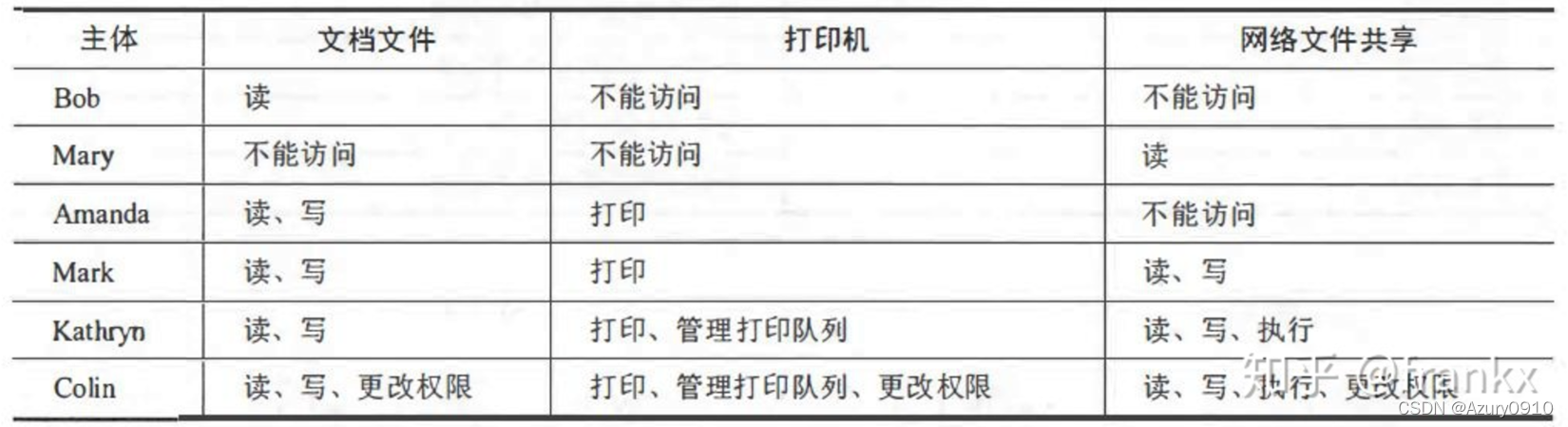
访问矩阵A在实际系统中主要有两种实现方式:
- 指定主体的能力表(Capabilities List,CL)
该表记录了每一个主体与一个权限集合的对应关系。权限集合中每个权限被表示为一个客体以及其上允许的操作集合的二元组。
- 指定客体的访问控制列表(Access Control List,ACL)
该表记录了每一个客体与一个权限集合的对应关系。权限集合中的每个权限被表示为一个主体以及其能够进行的操作集合的二元组。
(2)强制访问控制模型
(a)BLP模型:机密性、下读上写
BLP(Bell-lapadula)模型被用于保护系统的机密性,防止信息的未授权泄漏。
-
安全级别Level:公开(UC)、秘密(S)、机密(C)、绝密(TS)。它们之间的关系为UC≤S≤C≤TS。
-
范畴Category:为一个类别信息构成的集合,例如{中国,军事,科技}。具有该范畴的主体能够访问那些以该范畴子集为范畴的客体。
-
安全标记Label:由安全级别和范畴构成的二元组<Level,Category>,例如<C,{中国,科技>。
-
支配关系dom:安全标记A dom B,当且仅当Level_A≥Level_B,Category_A⊇Category_B。
BLP模型中在为系统中每个保护范围内的主客体都分配了安全标记后,主体对客体的访问行为应满足如下两条安全属性:
-
简单安全属性:主体S可以读客体O,当且仅当LabelS dom LabelO,且S对O有自主型读访问权限。
-
安全属性:主体S可以写客体O,当且仅当LabelO dom LabelS,且S对O具有自主型写权限。
从信息流角度看,上述两条读/写操作所应遵循的安全属性阻止了信息从高安全级别流入低安全级别,且使得信息“仅被需要知悉的人所知悉”,因此,能够有效地确保数据的机密性。
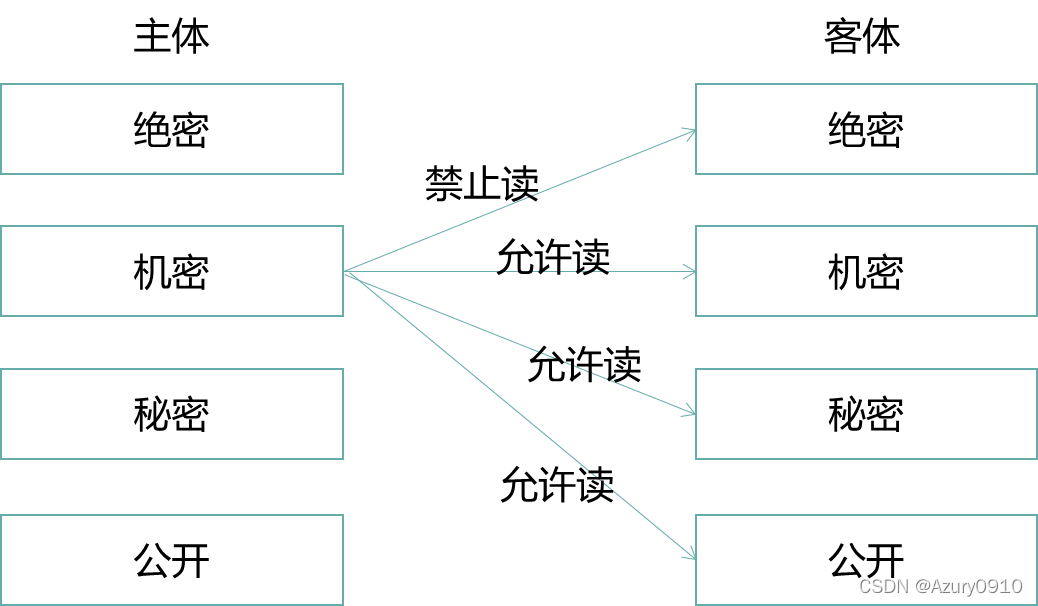
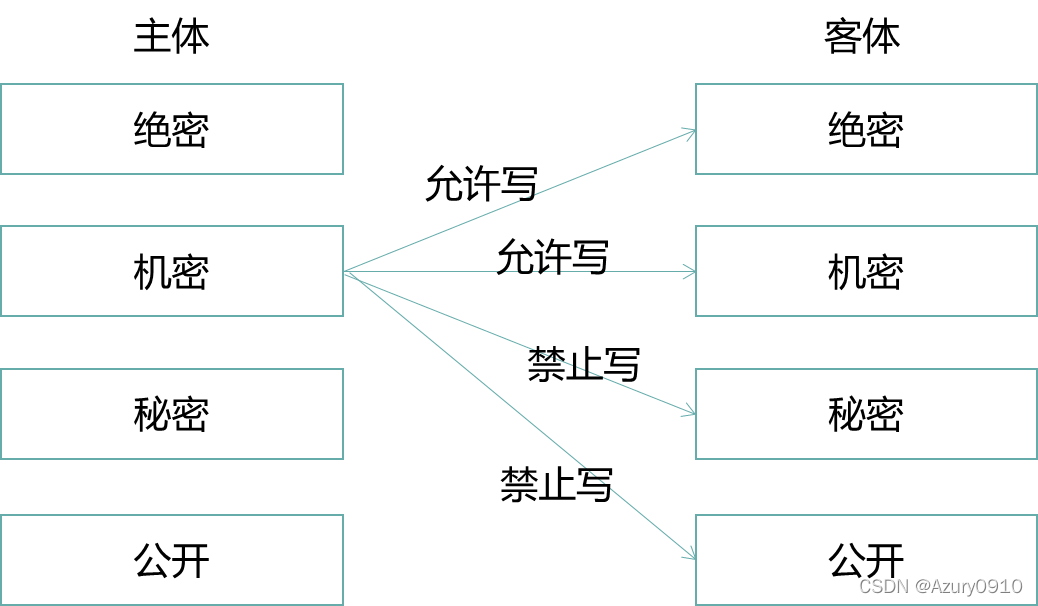
但是BLP模型这种“下读上写”的规则忽略了完整性的重要安全指标。
(b)Biba模型:完整性、上读下写
Biba模型是第一个关注完整性的访问控制模型,用于防止用户或应用程序等主体未授权地修改重要的数据或程序等客体。该模型可以看作是BLP模型的对偶。
-
完整性级别Level:代表了主/客体的可信度。完整性级别高的主体比完整性级别低的主体在行为上具有更高的可靠性;完整性级别高的客体比完整性级别低的客体所承载的信息更加精确和可靠 。
-
范畴Category:是基于类别信息对方问行为的进一步约束。若范畴Category_A⊇Category_B,则A能写入B;否则,A不能写入B
-
完整性标记Label:由完整性级别和范畴构成的二元组<Level,Category>。
-
支配关系dom:完整性标记A dom B,当且仅当Level_A≥Level_B,Category_A⊇Category_B。
Biba模型的严格完整性策略是BLP模型的对偶,也是不特别指明情况下所谓的Biba模型。它应满足如下安全属性:
-
完整性特性:主体S能够写入客体O,当且仅当LabelS dom LabelO。
-
调用特性:主体S1能够调用主体S2,当且仅当LabelS1 dom LabelS2。
-
简单完整性条件:主体S能够读取客体O,当且仅当LabelO dom LabelS。
基于上述三条安全属性,信息只能从高完整性级别的主客体流向低完整性级别的主客体,从而有效避免了低完整性级别的主客体对高安全级别主客体的完整性的“污染”。
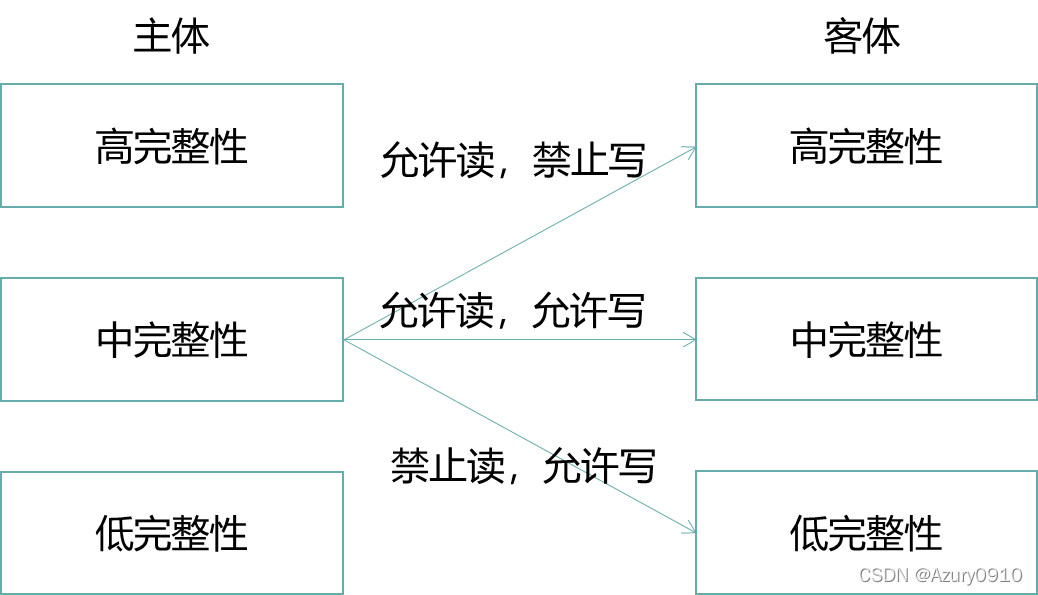
从上述BLP模型和Biba模型可以看出,强制访问控制是基于主客体标记之间的支配关系来实现的。在大数据场景下,由安全管理员来进行强制访问控制的授权管理是具有挑战性的。
- 随着主客体规模的急剧增长,安全标记的定义和管理将变得非常繁琐;
- 来自多个应用的用户主体和数据客体也将使得安全标记难以统一。
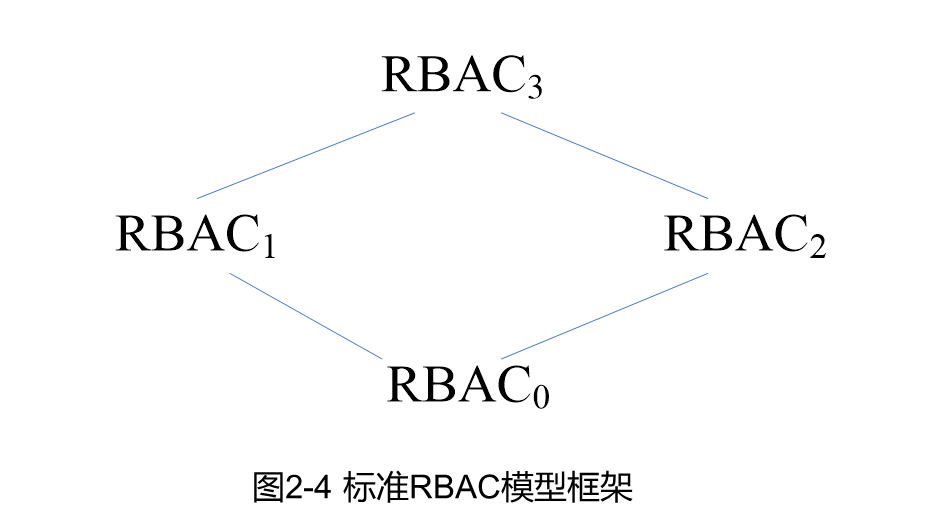
(3)基于角色的访问控制模型:RBAC0~3四个模型及其相互关系
RBAC0是最基本的模型,定义了用户、角色、会话和访问权限等要素。RBAC1在RBAC0的基础上引入了角色继承的概念。RBAC2增加了角色之间的约束条件,例如互斥角色等。RBAC3是RBAC1和RBAC2的综合,探讨了角色继承和约束之间的关系。
标准RBAC模型包括了RBAC0~3四个模型。
- RBAC0(Core RBAC),定义了用户、角色、会话和访问权限等要素,并形式化地描述了访问权限与角色的关系。
- RBAC1(Hierarchal RBAC)在RBAC0的基础上引入了角色继承的概念,简化了权限管理的复杂度。
- RBAC2(Constraint RBAC)增加了角色之间的约束条件,例如互斥角色、最小权限等。
- RBAC3(Combines RBAC)是RBAC1和RBAC2的综合,探讨了角色继承和约束之间的关系。
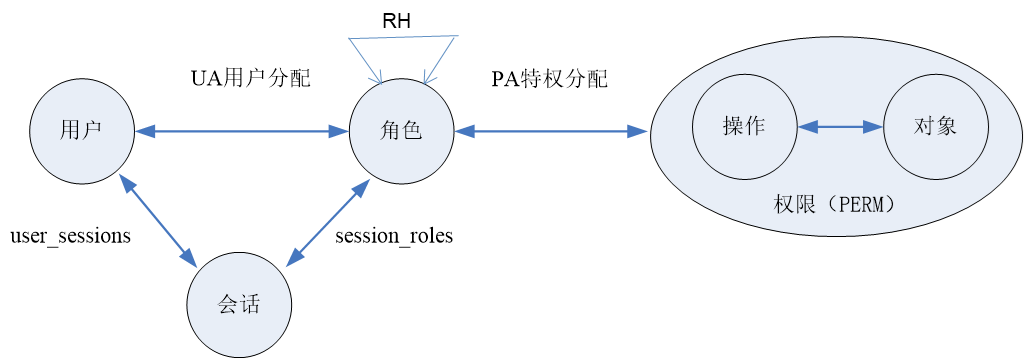
(a)Core RBAC
Core RBAC定义了基于角色访问控制的5个元素——用户、角色、对象、操作、权限以及一个动态的概念——会话。
角色访问控制的基本元素
-
用户是访问控制的主体,可以发起访问操作请求。
-
对象是访问控制的客体,指系统中受访问控制机制保护的资源.
-
操作是指对象上能够被执行的一组访问操作。
-
权限是指对象及其上指定的一组操作,是可以进行权限管理的最小单元。
-
角色是权限分配的载体,是一组有意义的权限集合。
-
会话用于维护用户和角色之间的动态映射关系。
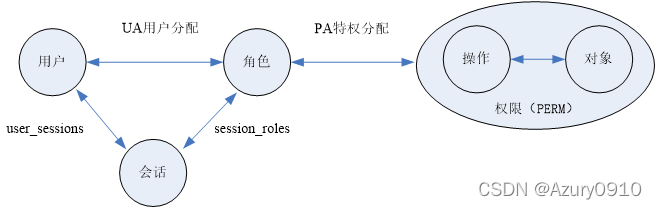
元素之间的关系:
-
UA用户分配:用户和角色之间是多对多的映射关系,记录了管理员为用户分配的所有角色。
-
PA特权分配:角色与权限之间也是多对多的映射关系,记录了管理员为角色分配的所有权限
-
user_sessions:用户与会话之间的一对多映射关系。即一个用户可通过登录操作开启一个或多个会话,而每个会话只对应一个用户。
-
session_roles:会话与角色之间的多对多关系。即用户可以在一个会话中激活多个角色,而一个角色也可以在多个会话中被激活。
(b)Hierarchal RBAC
角色继承操作(Role Hierarchies,RH)即一个角色
r
1
r_1
r1继承了另一个角色
r
2
r_2
r2,那么
r
1
r_1
r1就拥有
r
2
r_2
r2的所有权限。角色继承分成两类:
-
多重继承:一个角色可以同时继承多个角色,且角色满足偏序关系
-
受限继承:在满足偏序关系的同时,一个角色只能继承一个角色,即继承关系为树结构
(c)Constraint RBAC
RBAC2在RBAC0的基础上引入了指责分离的概念,以调节角色之间的权限冲突,即如果两个角色拥有的某些权限是冲突的,那么就需要增加职责分离约束,使两个角色不能并存。根据约束生效的时期不同,这些约束可以被分为两类:
- 静态职责分离(Static Separation of Duty,SSD)
- 动态职责分离(Dynamic Separation of Duty,DSD)
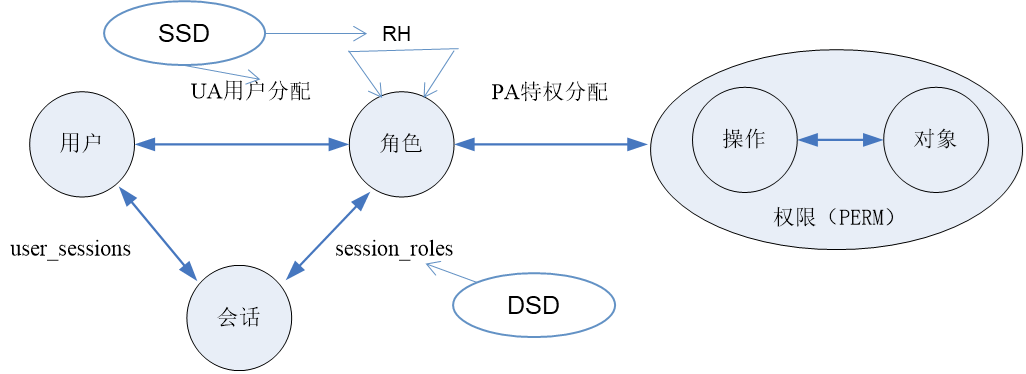
SSD主要作用于管理员为用户分配角色和定义角色继承关系阶段。若两个角色被设定了SSD约束,则不能被同时分配给一个用户,且不存在继承关系;
DSD主要作用于用户激活角色的阶段。若两个角色被设定了DSD约束,则不能在一个对话中被用户同时激活。
(d)Combines RBAC
Combines RBAC是在Core RBAC的基础上对Hierarchal RBAC的角色继承和Constraint RBAC的约束的综合。
(4)基于属性的访问控制模型:各组成部分的功能及流程
基于属性的访问控制模型是一种适用于开放环境下的访问控制技术。它通过安全属性来定义授权,并实施访问控制。由于安全属性可以由不同的属性权威分别定义和维护,所以具备较高的动态性和分散性,能够较好地适应开放式的环境。具体地,它包括如下几个重要概念:
-
实体entity:系统中存在的主体、客体,以及权限和环境。
-
环境environment:指访问控制发生时的系统环境。
-
属性attribute:用于描述上述实体的安全相关信息。它通常由属性名和属性值构成,又可分为以下几类:
- 主体属性:姓名、性别、年龄
- 客体属性:创建时间、大小
- 权限属性:业务操作读写性质的创建、读、写
- 环境属性:时间、日期、系统状态等。
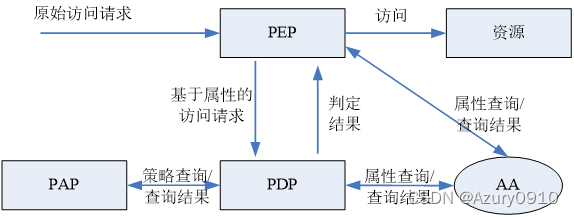
AA为属性权威 attribution authority,负责实体属性的创建和管理,并提供属性的查询。
PAP为策略管理点,负责访问控制策略的创建和管理,并提供策略的查询。
PEP为策略执行点,负责处理原始访问请求,查询AA中的属性信息生成基于属性的访问请求,并将其发送给PDP进行判定,然后根据PDP的判定结果实施访问控制。
PDP为策略判定点,负责根据PAP中的策略集对基于属性的访问请求进行判定,并将判定结果返回PEP。
较为适合大数据的开放式数据共享环境。然而属性的管理和标记对于安全管理员来说仍然是劳动密集型工作,且需要一定的专业领域知识。在大数据场景下,数据规模和应用复杂度使得这一问题更加严重。
3 局限性总结@
早期访问控制模型和技术在大数据应用场景下主要存在三方面问题:
- 安全管理员的授权管理难度更大
- 严格的访问控制策略难以适用
-
外包存储环境下无法使用
- 数据所有者不具备海量存储能力
- 数据所有者不具备构建可信引用监控机的能力
(二)基于数据分析的访问控制技术
1 角色挖掘技术
在基于角色的访问控制中,管理员需要解决两个问题:
大数据场景下角色的定义将是大工作量,且需要领域知识的任务。安全管理员已经难以自上而下地分析和归纳安全需求,并基于需求来定义角色了。为了解决该问题,自底向上定义角色的方法被提出,即采用数据挖掘技术从系统的访问控制信息等数据中获得角色的定义,也被称为角色挖掘(Role Mining)。目前经典的角色挖掘技术可以分为两类:
(1) 基于层次聚类的角色挖掘方法
系统在初始情况下往往已经有了简单的访问权限分配——“哪些用户能够访问哪些数据”,例如授权信息表。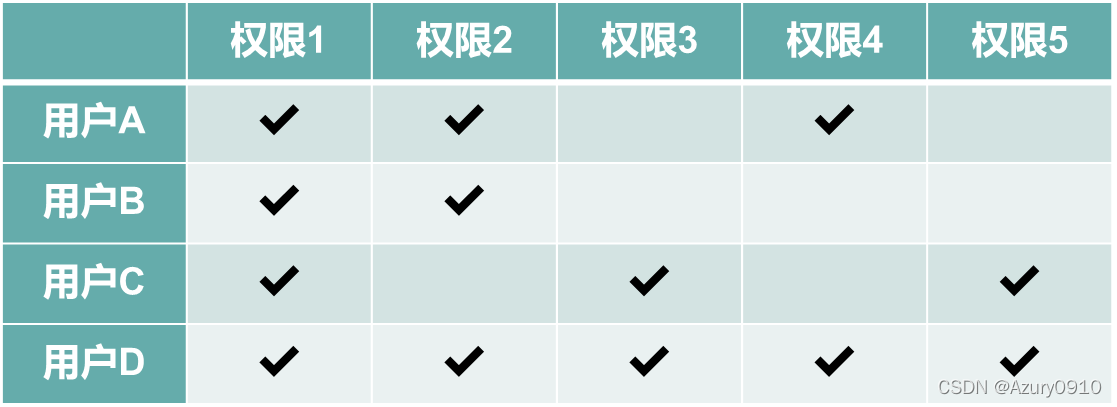
以上表格中所呈现的权限组合往往暗示着为了完成工作而应该设置的角色,因此,可以对已有的权限分配关系进行数据挖掘来寻找潜在的角色概念,并将角色与用户、角色与权限分别关联。
我们将角色看作大量用户共享的权限组合,并假设真实的角色定义已经正确且完整地隐含在当前的授权数据中。也就是说,所有人持有的权限都是有意义的,同时已有的权限分配都是正确的。
聚类是一种非监督场景下的发现数据潜在模式的经典方法。系统的用户基数越大,权限越多,这种权限分配的潜在模式就越明显,采用聚类进行角色挖掘的效果就越好。
基于层次聚类的角色挖掘根据层次聚类方式的不同又可以分为:
(a)凝聚式的角色挖掘
将权限看作是聚类的对象,通过不断合并距离近的类簇完成对权限的层次聚类,聚类结果为候选的角色。
基本定义
- 类簇Cluster:由权限和持有这些权限的用户组成的二元组c=<rights,members>。
- 用户集合Persons:所有用户组成的集合。
- 类簇集合Clusters:包含所有类簇的聚类结果集。
- 偏序关系集合
<
<
<:聚类之间的偏序关系构成的集合。
- 无偏序关系类簇集合
T
<
T_<
T<:类簇集合中的类簇,两两间不存在偏序关系。即
T
<
=
c
∈
C
l
u
s
t
e
r
s
:
∄
d
∈
C
l
u
s
t
e
r
s
:
c
<
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)