导读
源码:Detr
Detr用的数据集格式为coco数据集格式,所以在进行Detr算法前,需要将我们的数据集转为coco数据集,可参考VOC转COCO数据集
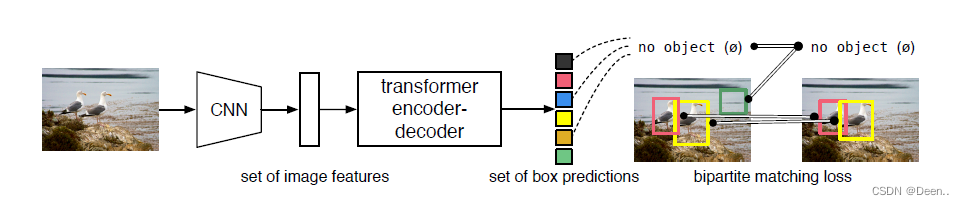
Detr模型如上图所示,简单来讲,就是将图片进行CNN特征提取后送入Transformer模块,然后直接生成预测框,设置个阈值后,生成的预测框就是预测结果,不需要再经历NMS操作。
下载完源码后,直接打开项目,Detr项目依赖了几个作者自己做的第三方库,所以首先打开项目里的README.md文件。
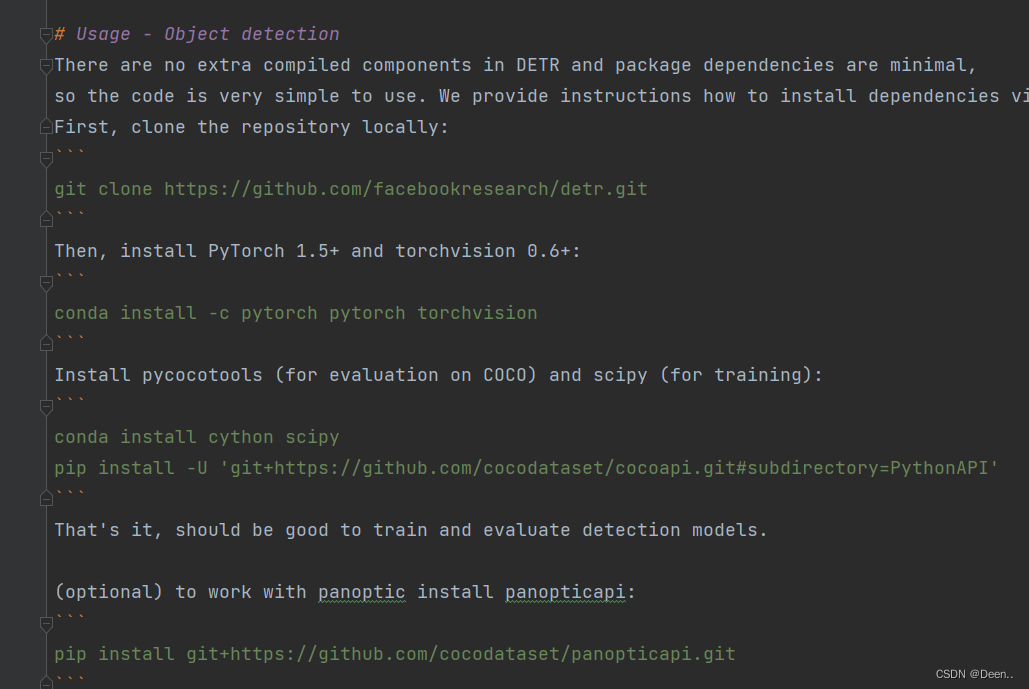
找到Usage - Object detection部分,按着这部分提供的安装指令,将第三方库安装到编译器环境下。这里注意,可能输入指令会报错,原因可能是你没有安装git。git的安装可以去查一下。
环境配置完毕后就可以运行main.py文件开始运行整个项目。
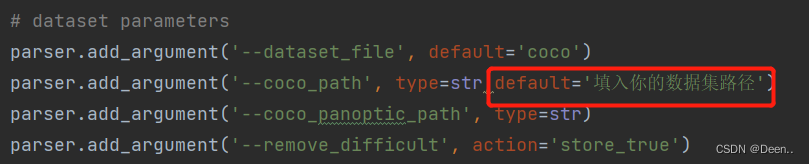
在运行main.py前需要将对它的初始参数进行设置,比如batch_size,数据来源等等。两种方式可以设置,第一,直接在代码每个参数后的default进行设置:
调试的时候也可以通过Debug里修改运行配置:
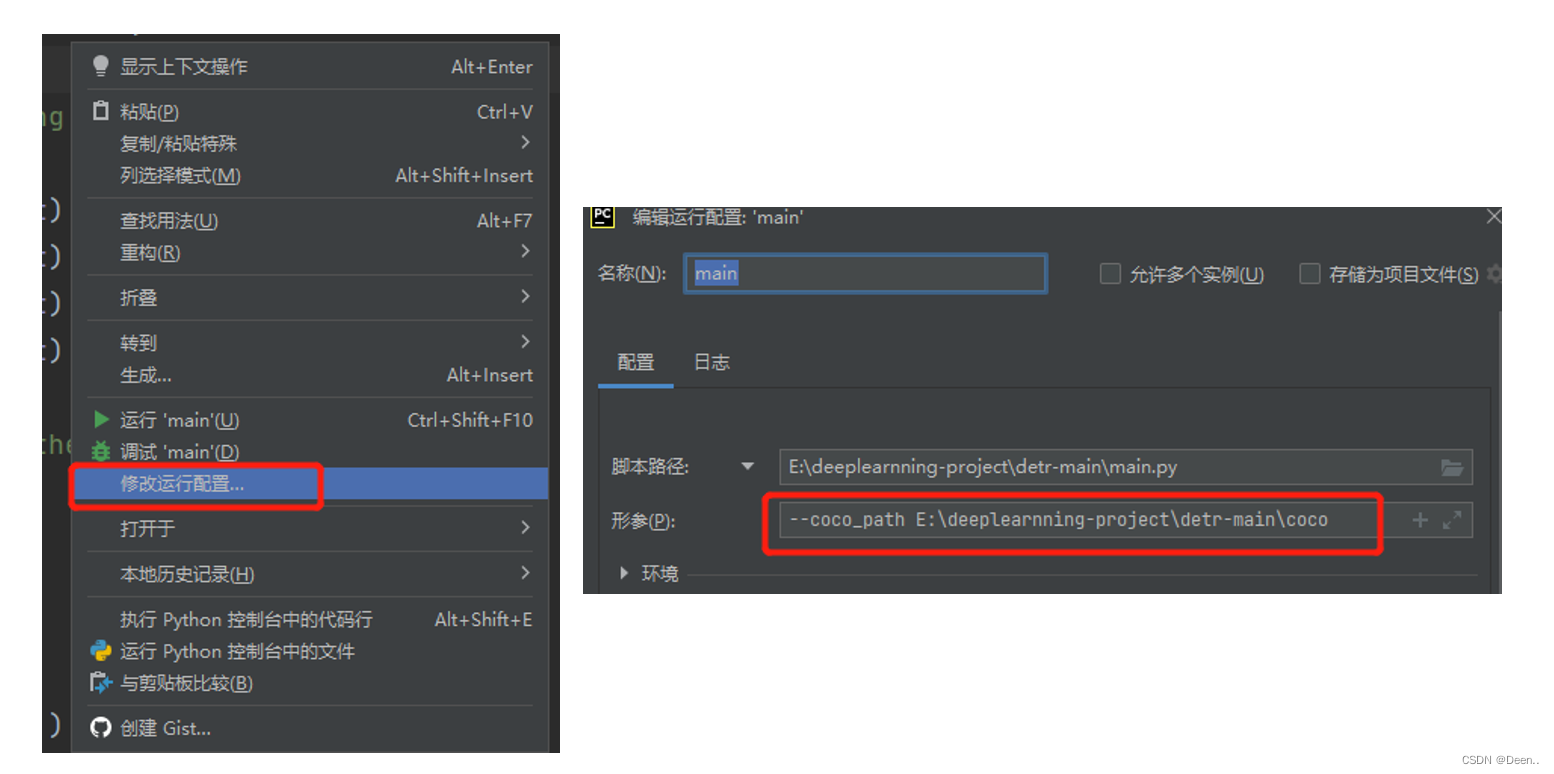
给main.py设置完数据源后就可以运行项目了。
如果出现数据文件找不到之类的报错:

直接翻到本文目录。
数据加载
这一部分先来看数据集是怎么加载到模型里的。之前写过一篇数据加载机理的
数据集加载部分SSDDataset类代码解读-数据采样机理
其实不管是什么检测算法,用的都是DataLoader进行数据采样。
直接在main.py文件里找到DataLoader,代码如下
data_loader_train = DataLoader(dataset_train, batch_sampler=batch_sampler_train,
collate_fn=utils.collate_fn, num_workers=args.num_workers)
DataLoader中设置了数据集dataset_train,采样策略batch_sampler(可选择随机采样还是顺序采样),collate_fn收集策略(读取的数据进行初步的处理后,以什么的格式返回给上层的函数)num_workers(告诉DataLoader实例要使用多少个子进程进行数据加载(和CPU有关,和GPU无关))
dataset_train这个实例可以认为是一个数据迭代器,DataLoader告诉dataset_train迭代器需要随机采样16张图片,dataset_train就会迭代16次,每一次去读取一张图片,并对这张图进行初步的处理。
dataset_train
按ctrl+F直接在main.py中搜索dataset_tarin:
dataset_train = build_dataset(image_set='train', args=args)
dataset_val = build_dataset(image_set='val', args=args)
按ctrl+鼠标左键进入build_dataset函数:
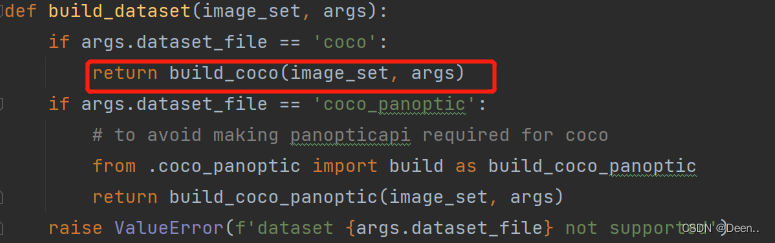
def build_dataset(image_set, args):
if args.dataset_file == 'coco':
return build_coco(image_set, args)
if args.dataset_file == 'coco_panoptic':
# to avoid making panopticapi required for coco
from .coco_panoptic import build as build_coco_panoptic
return build_coco_panoptic(image_set, args)
raise ValueError(f'dataset {args.dataset_file} not supported')
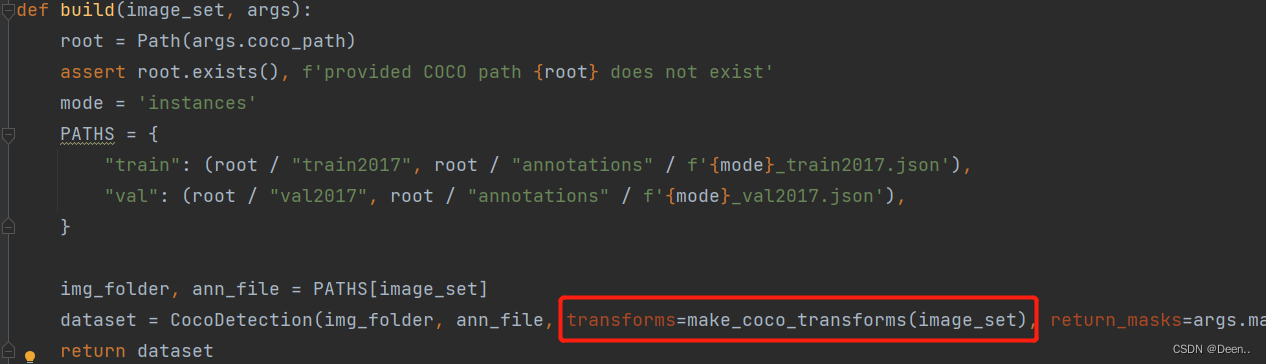
本文的数据集文件是coco,所以直接运行前两句,进入build_coco函数
数据源文件不存在报错解决
这里有个点要注意PATHS是现在数据集下面训练集跟验证集的名称,如果跟你数据集名称不一样,可以在这里改成你数据集下的名称。
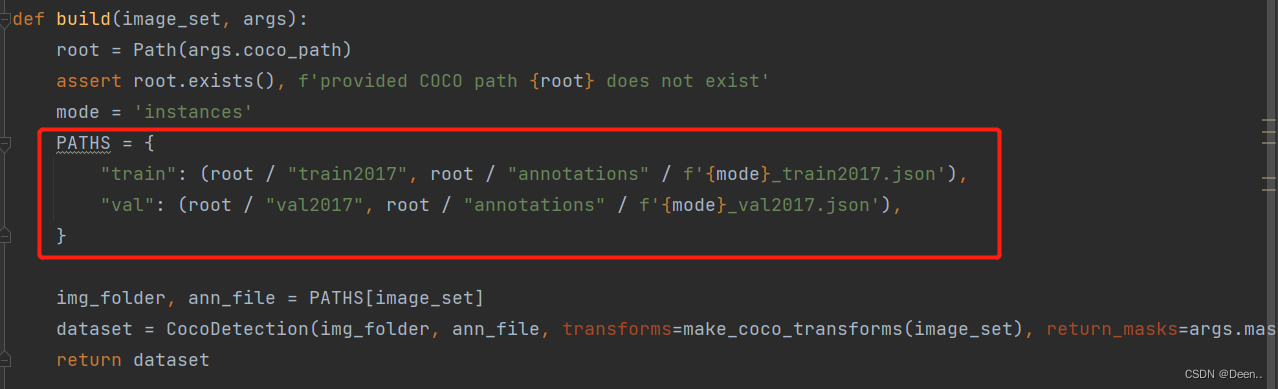
这一步就将数据集的路径跟dataset迭代器联系起来了,之后迭代器就可以根据指令,去读取数据集路径下的数据了。
CocoDetection
这一部分才是dataset_tarin这个数据迭代器的核心内容,
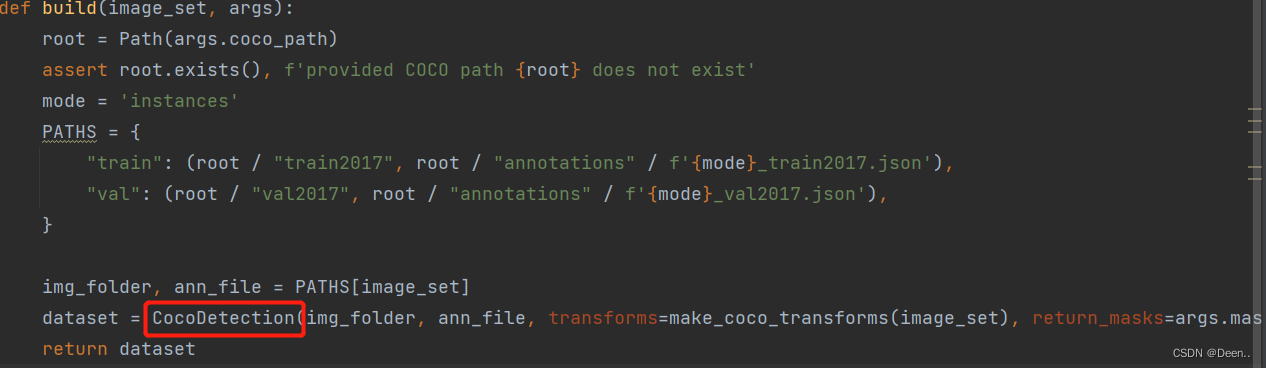
dataset_train可以根据DataLoader进行采样对应的函数就是CocoDetection中的def __getitem__(self, idx):函数,这个函数会根据DataLoader下发的idx索引进行采样。
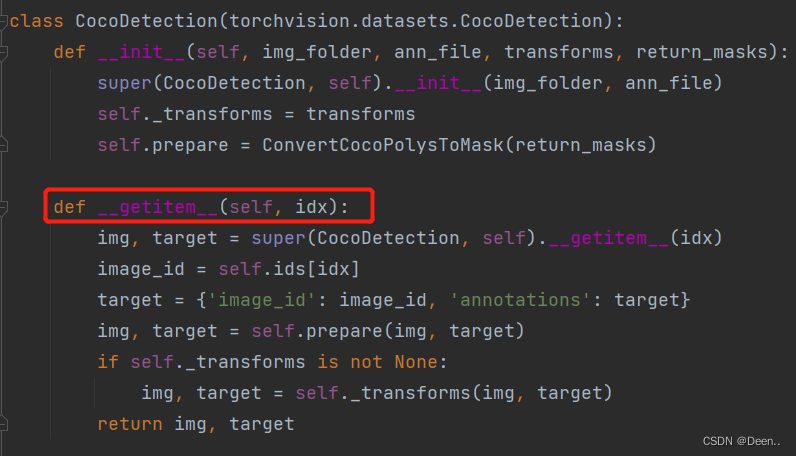
在CocoDetection中设置了图象变换的函数,以及是数据处理函数:
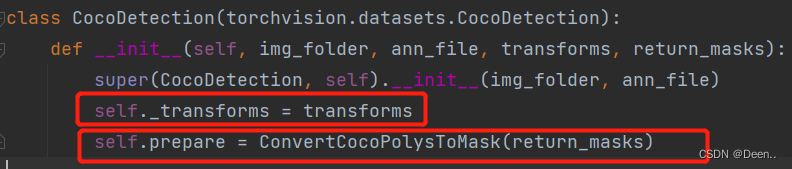
初始值设置好后,返回main.py查找train_one_epoch,数据通过train_one_epoch进行读取。train_one_epoch也是正式的一轮训练。
train_stats = train_one_epoch(
model, criterion, data_loader_train, optimizer, device, epoch,
args.clip_max_norm)
打开train_one_epoch函数在for samples, targets in metric_logger.log_every(data_loader, print_freq, header):这行指令中进行数据集的采样。通过for in对DataLoader进行访问,DataLoader根据所配置的内容对dataset_train进行采样。

将调用DataLoader的for in写在了metric_logger.log_every里:
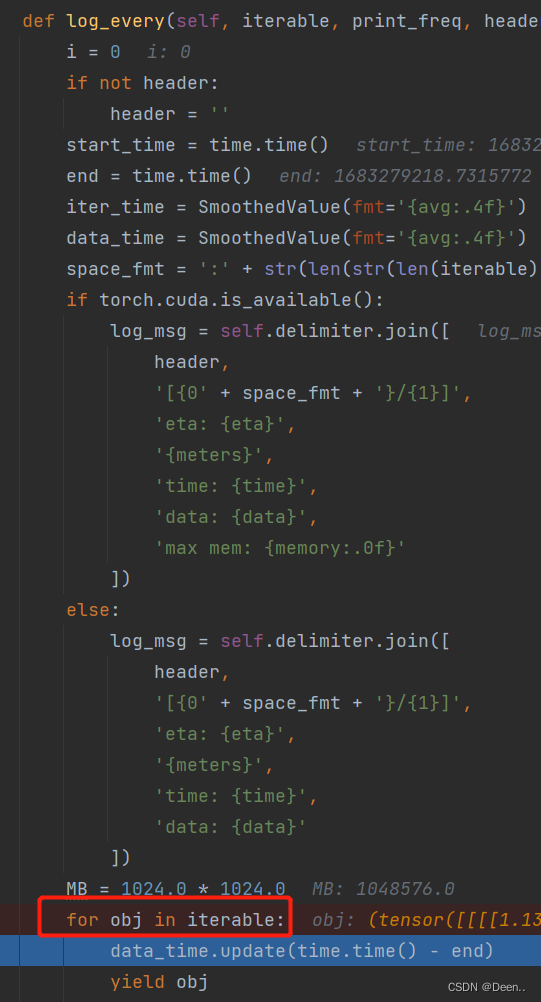
采样
DataLoader随机生成一个索引传给数据迭代器CocoDetection,通过def __getitem__(self, idx):对这个索引对应的数据进行处理:
下图中的super(CocoDetection, self).__getitem__(idx)这个函数是COCO自己的第三方库里的一个函数,可以根据索引直接获取数据集中对应的图片跟他的标注。img就是这个索引对应的图片,target就是对应的标注。
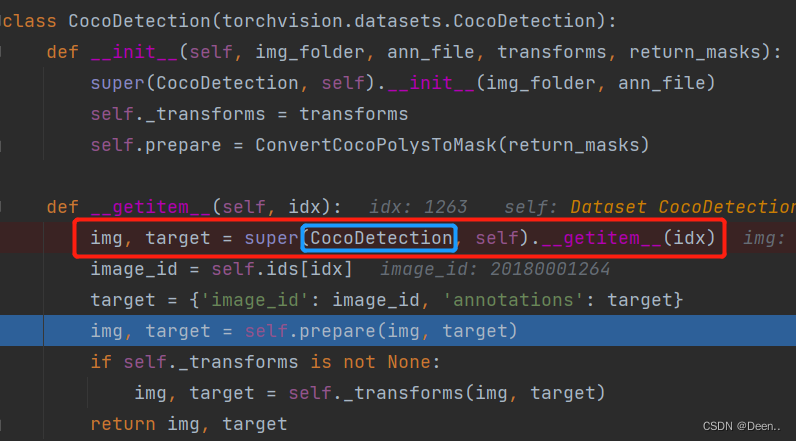
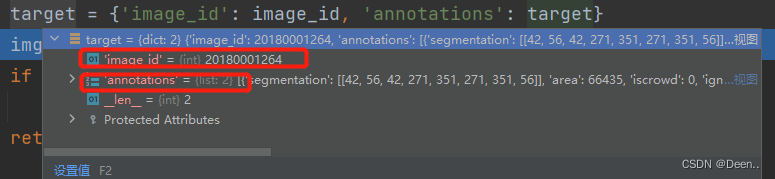
进一步通过img, target = self.prepare(img, target)对图片跟标注进行处理:
img, target = self.prepare(img, target)
数据处理
处理target
对输入self.prepare的图片跟标注进行处理,首先先获取图片id,然后获取标注信息,获取目标类别,然后将这些转为tensor格式。
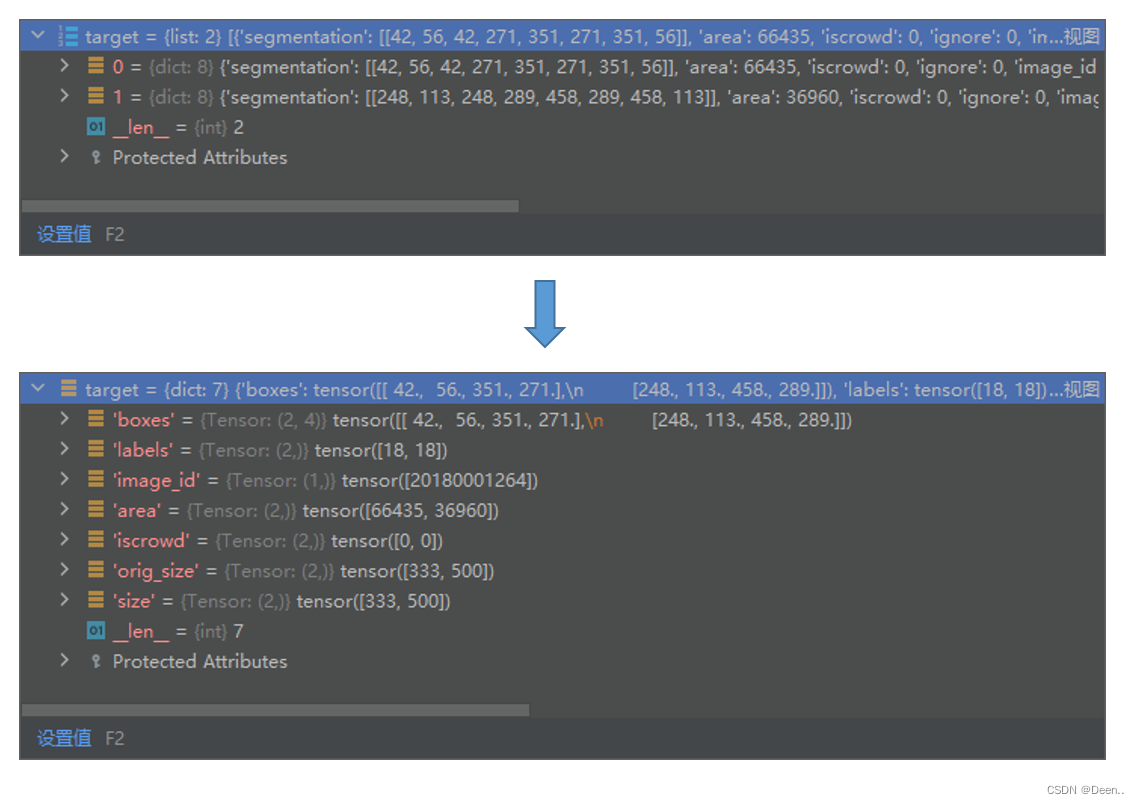
ConvertCocoPolysToMask将每个image对应的target转化成为一个dict,这个dict中保存了该图片的所有标注信息,其中对于目标检测的有用信息是boxes和labels,其如下:
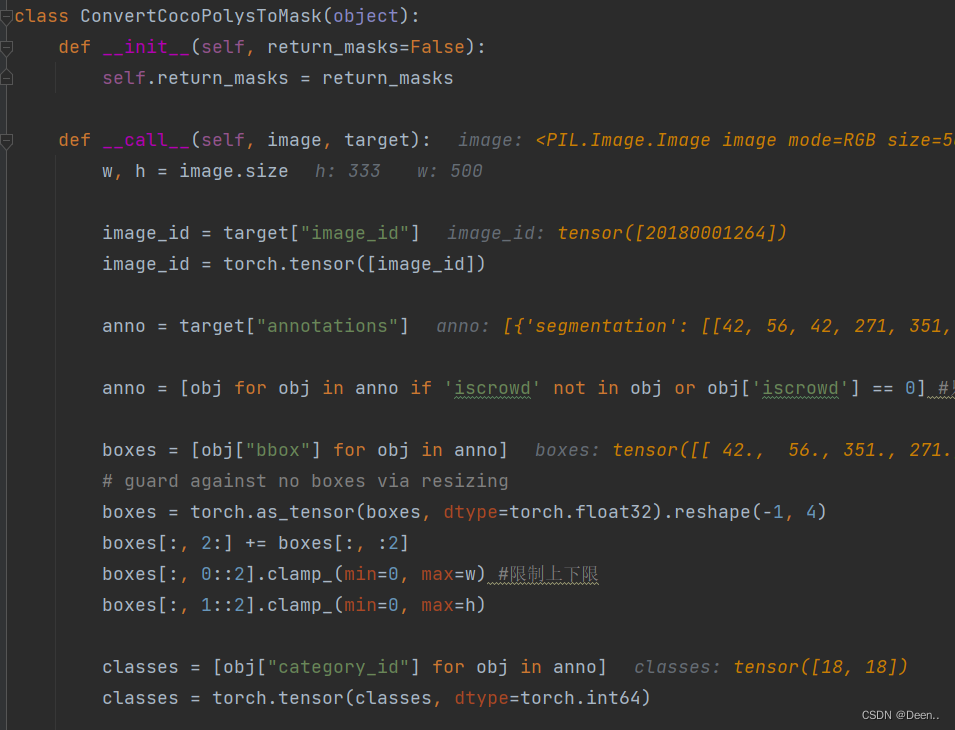
因为研究的是目标检测,而不是关键点检测跟实例分割所以跳过跟keypoints、self.return_masks有关的代码,如下面两段代码:
if self.return_masks:
segmentations = [obj["segmentation"] for obj in anno]
masks = convert_coco_poly_to_mask(segmentations, h, w)
keypoints = None
if anno and "keypoints" in anno[0]:
keypoints = [obj["keypoints"] for obj in anno]
keypoints = torch.as_tensor(keypoints, dtype=torch.float32)
num_keypoints = keypoints.shape[0]
if num_keypoints:
keypoints = keypoints.view(num_keypoints, -1, 3)
然后将获取到的标注信息重新整理放到target字典中:
target = {}
target["boxes"] = boxes
target["labels"] = classes
target["image_id"] = image_id
此外又做了一个标注内容面积的计算,还有尺寸信息等,是为了之后利用COCOAPI计算检测的map值准备的。
# for conversion to coco api
area = torch.tensor([obj["area"] for obj in anno])
iscrowd = torch.tensor([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno])
target["area"] = area[keep]
target["iscrowd"] = iscrowd[keep]
target["orig_size"] = torch.as_tensor([int(h), int(w)])
target["size"] = torch.as_tensor([int(h), int(w)])
得到的target内如如下:
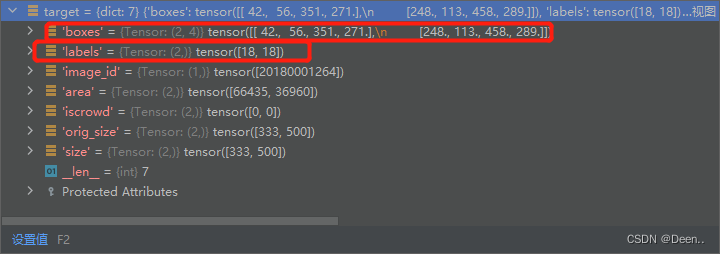
通过img, target = self.prepare(img, target)使得target从标注的格式变成dict类型:
处理img
图片处理这边用到transforms了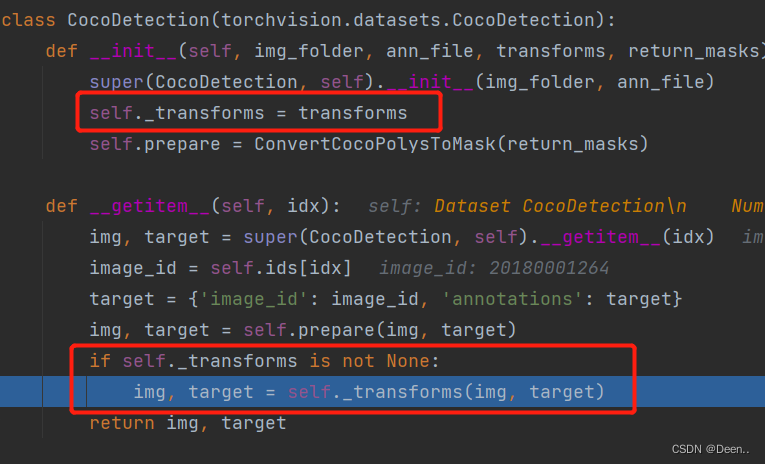
这是一种常见的图片操作函数,直接看make_coco_transforms函数
简单来讲就是将输入进来的图片转为tensor格式然后进行标准化,再判断其是train模式还是val模式,如果是tarin模式,则先对图片进行翻转,再随机的缩放等操作。最后将图片返回。具体代码如下:
def make_coco_transforms(image_set):
normalize = T.Compose([
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]
if image_set == 'train':
return T.Compose([
T.RandomHorizontalFlip(),#随机水平翻转给定的PIL.image 概率为0.5
T.RandomSelect(#随机选择两个字操作之一
T.RandomResize(scales, max_size=1333),#随机选择sizes中的一个值作为图象短边,并保持比例,最大不超过max_size
T.Compose([
T.RandomResize([400, 500, 600]),
T.RandomSizeCrop(384, 600),#对图片进行随机尺寸裁剪,最后缩放到统一大小
T.RandomResize(scales, max_size=1333),#
])
),
normalize,
])
if image_set == 'val':
return T.Compose([
T.RandomResize([800], max_size=1333),
normalize,
])
raise ValueError(f'unknown {image_set}')
收集策略collate_fn(batch)
DataLoader对trainset训练数据集进行一个batch的采样后,将采到的数据传入collate_fn(batch)函数,将这一批数据进行整理一下返回给上一级。
如下图所示,DataLoader一批采样两张图片:
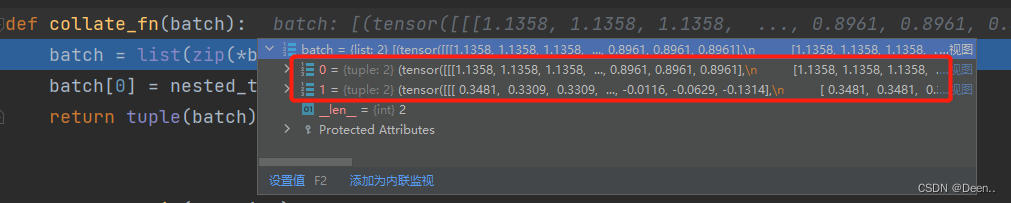
这里对图片又进行了nested_tensor_from_tensor_list操作,对于每一批次的图像,首先找出每一批次图片的H,W的最大值Hmax,Wmax,然后将原始图像填充为3HmaxWmax大小,并将图像部分置为False,填充部分置为True.最后将图像数据tensor和mask打包为nesttensor格式。
这样子使得每批次输出的图片的大小一致。
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
if tensor_list[0].ndim == 3:
if torchvision._is_tracing():
# nested_tensor_from_tensor_list() does not export well to ONNX
# call _onnx_nested_tensor_from_tensor_list() instead
return _onnx_nested_tensor_from_tensor_list(tensor_list)
# TODO make it support different-sized images
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)
处理后的图片如下图所示:
