前言
前面学习了使用正则表达式和利用python第三方的解析库实现对目标网页源代码的爬取,可见即可爬,但很多时候往往并没有那么友好,网页源代码中可能没有我们需要的东西。还有当我们使用requesets抓取页面的时候,得到的结果可能和我们在浏览器中看到的结果不太一样,在浏览器中能看到正常的页面数据,但是使用requests爬取到的页面信息却不一样。这是因为requests获取到的是原始的HTML文本,而浏览器中的页面是经过JavaScript处理数据之后生成的结果。这种数据处理的方式有很多,可能是通过Ajax加载的,或者其他方式。通过Ajax加载的网页原始页面不会包含某些数据,等原始页面加载完成之后,会再向服务器请求接口获取数据,然后数据就被呈现在网页上。使用Ajax请求的网页一般有一个特点:下拉页面能源源不断的获取新的内容,不需要说是点击下一页才能看到其他数据,下拉页面之后新的内容就被加载出来了。下面我就介绍一下如何利用requests来模拟Ajax请求获取页面数据。
什么是Ajax
Ajax,全称Asynchronous Javascript and XML,即异步的JavaScript和XML。他不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
对于传统的网页,我们要获取新内容,那么必须要刷新整个页面,但是Ajax就可以保证在页面不用全部刷新的情况下更新内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用Javascript改变网页,然后就可以看到新的内容了。这就是我前面提到的只需要下拉页面就可以获取新的内容。
Ajax基本原理
发送Ajax请求到网页更新的这个过程可以分为以下三个步骤:
发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是JavaScript对Ajax最底层的实现,实际上就是新建了XMLHttpRequest对象,然后调用onreadystatechange属性设置了监听,然后调用open()和send()方法向某个链接(也就是服务器)发送了请求。前面用Python实现请求发送之后,可以得到响应结果,但这里请求的发送变成JavaScript来完成.由于设置了监听,所以当服务器返回响应时,onreadystatechange对应的方法便会被触发,然后在这个方法里面解析响应内容即可。
解析内容
得到响应之后,onreadystatechange属性对应的方法便会被触发,此时利用xmlhttp的responseText属性便可取到响应内容。这类似于Python中利用requests向服务器发起请求,然后得到响应的过程。那么返回内容可能是HTML,可能是JSON,接下来只需要在方法中用JavaScript进一步处理即可。比如,如果是JSON的话,可以进行解析和转化。
渲染网页
JavaScript有改变网页内容的能力,解析完响应内容之后,就可以调用JavaScript来针对解析完的内容对网页进行下一步处理了。比如,通过document.getElementById().innerHTML这样的操作,便可以对某个元素内的源代码进行更改,这样网页显示的内容就改变了,这样的操作也被称作DOM操作,即对Document网页文档进行操作,如更改、删除等。
上例中,document.getElementById(“myDiv”).innerHTML=xmlhttp.responseText便将ID为myDiv的节点内部的HTML代码更改为服务器返回的内容,这样myDiv元素内部便会呈现出服务器返回的新数据,网页的部分内容看上去就更新了。
我们观察到,这3个步骤其实都是由JavaScript完成的,它完成了整个请求、解析和渲染的过程。
引用来源:https://cuiqingcai.com/5593.html
以上的部分大家可以作为一个了解,如果对JavaScript比较熟悉的同学应该能搞明白,反正我是不太懂的。
Ajax分析方法
查看请求
这里我们需要借助浏览器的开发者工具进行Ajax分析,下面以Chrome浏览器中梅老板的微博界面为例介绍一下如何进行Ajax分析。
首先在Chrome中打开链接https://m.weibo.cn/detail/4522545920873031,然后在加载好的页面右键单击,选择“检查",然后就能打开开发者工具。
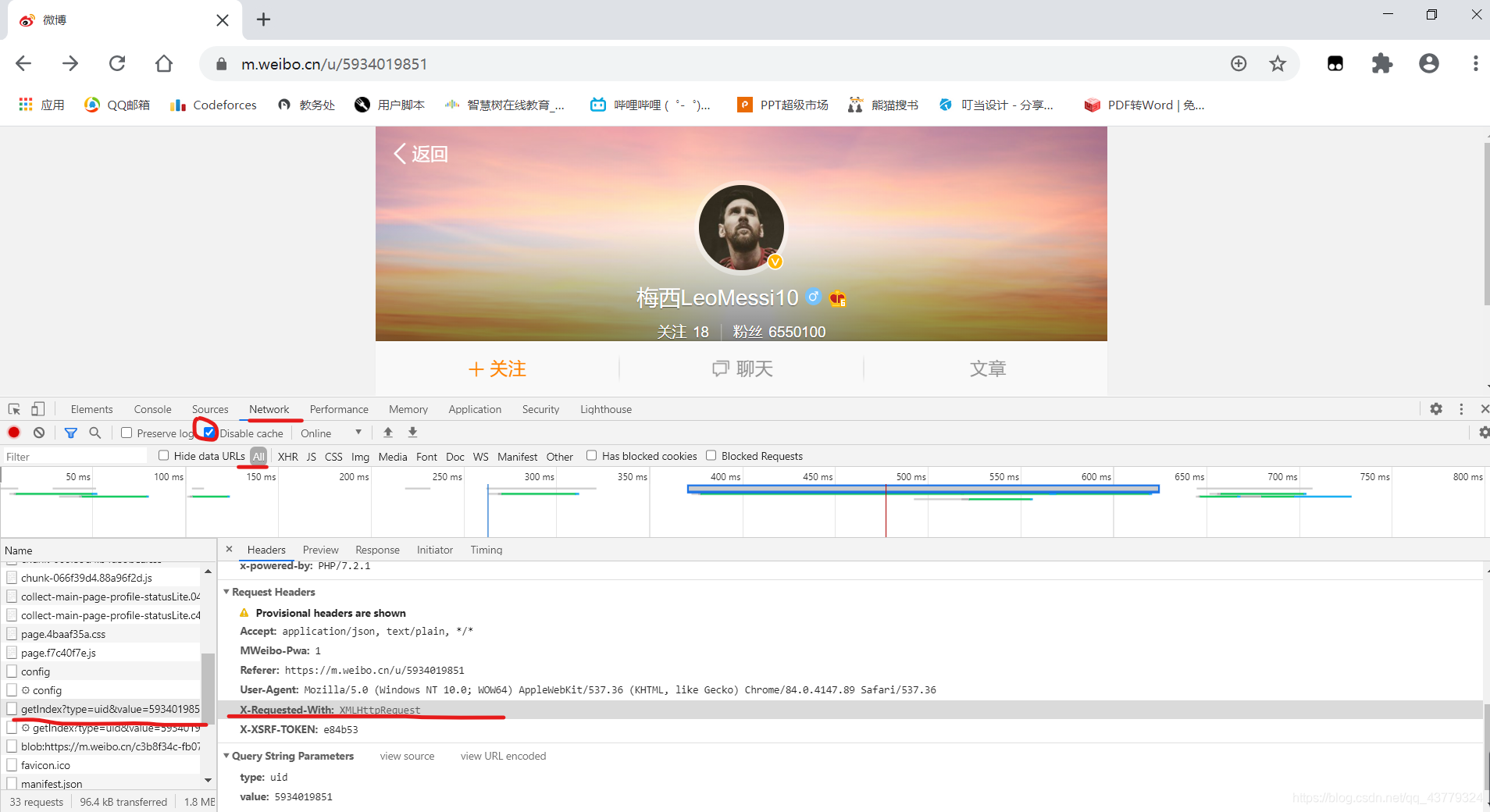
切换到Network选项卡,然后点击中间那两栏我红笔标记的地方,然后刷新页面,找到第一个以getIndex开头的一个请求,然后在headers界面,往下翻会看到X-Requested-With: XMLHttpRequest,其中的XMLHttpRequest就代表这是一个Ajax请求。

然后切换到preview,就可以看到响应的内容,这里是json格式的,这里的Chrome为我们做了解析,然后看到的就是一个一个的键值对A : B。然后点击里面的箭头就可以看到一些主页的数据信息,JavaScript在接收到这些数据之后执行相应的渲染方法,整个页面就渲染出来了。
过滤请求
然后再利用开发者工具筛选出所有的Ajax请求,我们可以看到上面的筛选栏,然后点击XHR,此时下方现实的所有请求就是Ajax请求。
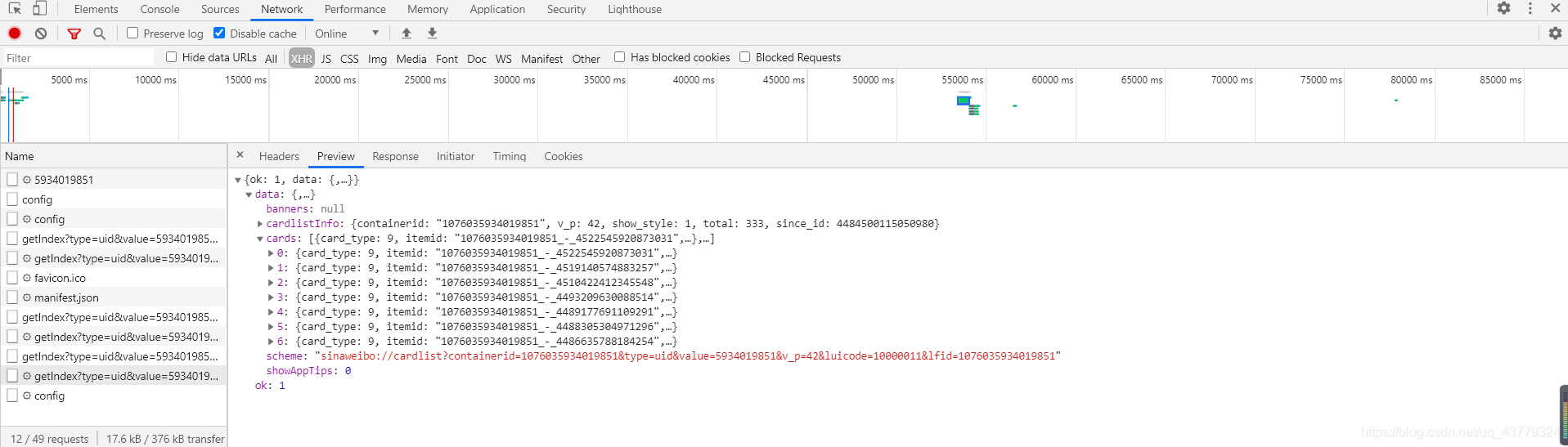
然后你可以点开每一个开头是getIndesx的请求,前面有的没有存数据,从后面的开始,每当你下拉页面就会有新的这个请求出来,然后里面就保存的有微薄的数据信息。然后我们只需要从这些数据中提取出我们想要的内容就可以了。
Ajax结果提取
我们仍以上面梅老板的微博为例,接下来我们利用python模拟Ajax请求,把梅老板发过的微博信息提取出来。
1.分析请求(since_id解析)
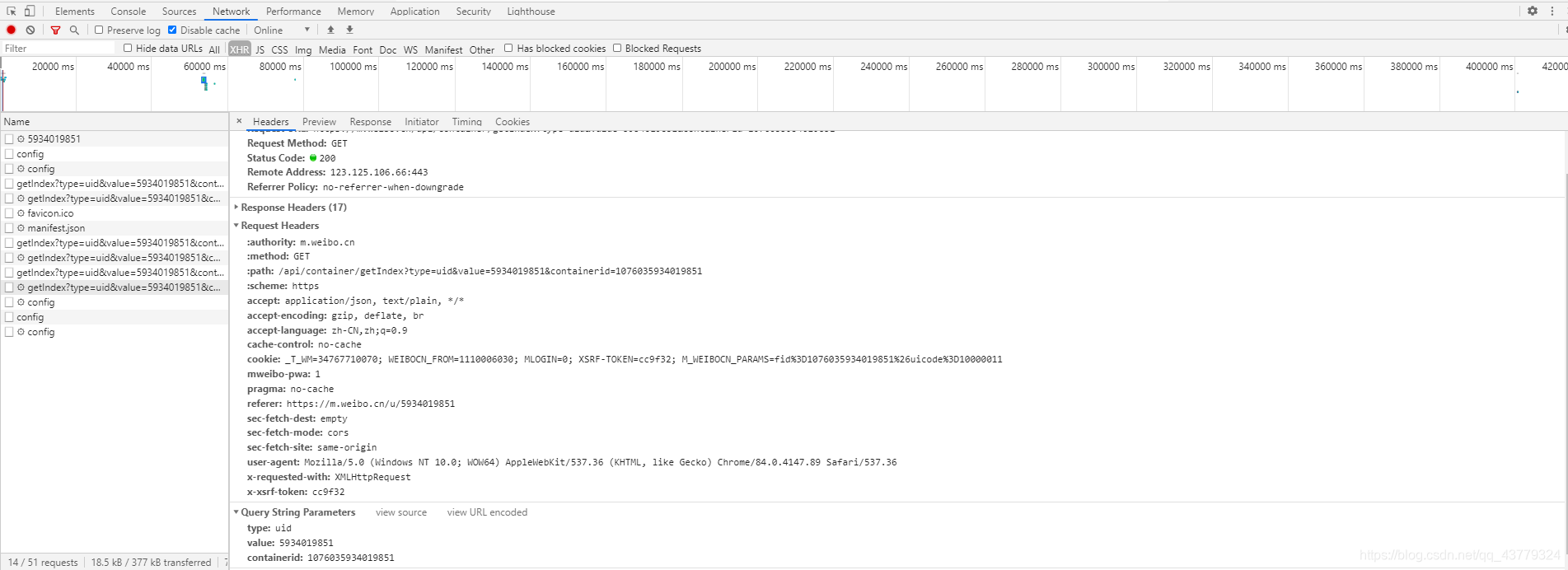
我们在Headers页面可以看到这个请求的各种参数信息,首先这是一个GET类型的请求,然后最后他的请求参数有四个type、value、containerid、since_id。然后再查看一下其他类似的请求发现这前三个参数所有的getIndex请求都是一样的,唯独这个since_id参数在每个请求的页面都不一样,并且还找不到什么规律,在我一筹莫展的时候,我有了如下发现:
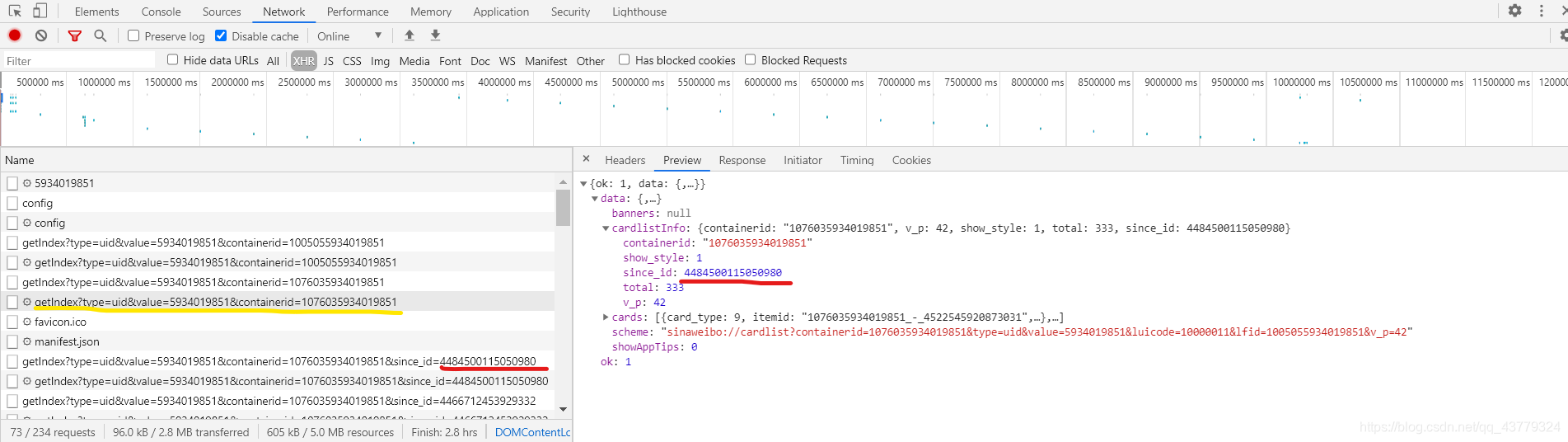
上图我画红线的地方:首先界面上是我画黄色线条请求的接送数据页面,然后它里面的有一个cardlistInfo信息,然后里面就有这个since_id的值,然后观察可以看到,这个since_id的值就是下一个Ajax请求中url后面since_id的值。同理多看几个页面我们可以发现这么个规律:就是第一个以getIndex开头的Ajax请求的since_id为空,可以当作是0,但其请求数据中包含的有下一个请求的since_id值,然后后面的每一个since_id数据都在前一个请求所响应的JSON格式数据中,就这样所有的请求就都可以模拟得到。
2.分析响应
我们找到其中一个请求的preview界面,然后看到其内容是JSON格式的,然后浏览器开发者工具为我们做了解析便于查看,我们点开里面的每一个箭头,然后可以看到一些微博的信息,在mblog字段里面有attitude_count(点赞数)、comments_conunt(评论数)、reposts_count(转发数)、created_at(发布时间)、text(正文内容)等等数据。
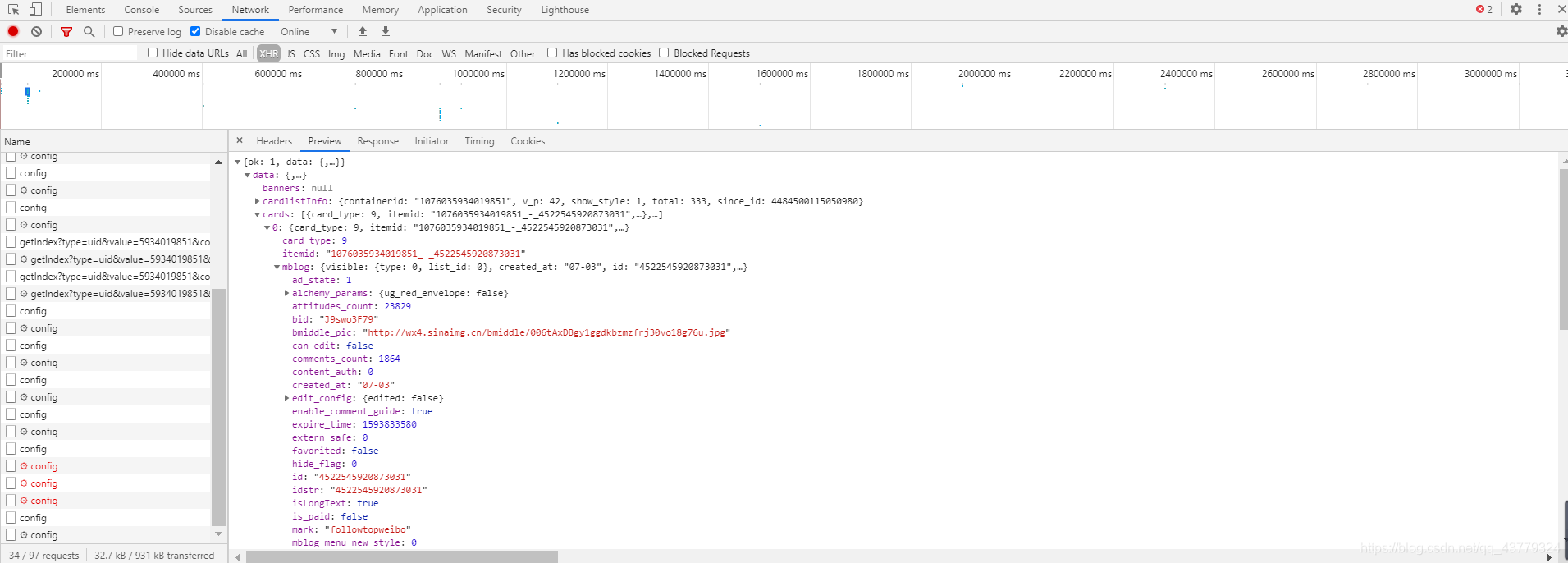
3.爬取微博数据
首先,我们定义一个方法来获取每次请求的结果:
headers = {
'host': 'm.weibo.cn',
'Referer':'https://m.weibo.cn/u/5934019851',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/84.0.4147.89 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(since_id):
params = {
'type': 'uid',
'value': '5934019851',
'containerid': '1076035934019851',
}
if since_id != 0:
params['since_id'] = since_id
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print("Error", e.args)
首先是要一个请求头,需要注意的是每台电脑中这个User-Agent是不一样的,然后在开发者工具中的Headers里面可以看到自己的User-Agent。然后构造一个字典,这个字典就能通过urlencode()方法转化为url中的请求参数,从而构成一个完整的url,其中的since_id我们单独定义并且要作为这个函数的参数,他是可变的,且可以通过其他方法求出。然后下面异常处理里面的代码就是一个非常常见的requests请求这个构造的链接,传入headers参数,然后返回json信息。
然后我们就需要定义一个解析方法了,从结果中提取出想要的信息,比如发布时间(created_at)、正文内容(text)、点赞数(attitude_count)、comments_conunt(评论数)、reposts_count(转发数)这几个内容。我们可以先遍历cards,然后获取mblog中的信息赋值为一个新的字典然后返回即可。
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['time'] = item.get('created_at')
weibo['text'] = pq(item.get('text')).text()
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
其中由于text里面有很多的HTML文本标签,所以我们借助pyquery中的text()方法将不含标签的文本提取出来。
最后就是main函数的编写了,此处需要注意的一点就是since_id的表示和调用关系。
if __name__ == '__main__':
since_id = 0
for page in range(1, 11):
json = get_page(since_id)
since_id = json.get('data').get('cardlistInfo').get('since_id')
results = parse_page(json)
for result in results:
print(result)
首先我们定义since_id为0,这表示是第一个Ajax请求,由于不存在上一个请求,所以设置初值为0,然后就是一个for循环,这里的page没有实际含义,不是原来崔庆才老师里面的那个page,原书中的page是因为微博的请求参数是page,现在改成了since_id。json = get_page(since_id)这行代码是解析出第一个Ajax请求的json信息,然后下一个请求的since_id可以在这个json数据中提取出来,然后解析得到我们想要的那几个数据并打印出来,然后下一次循环,又得到一个请求,这样不断地爬取微博数据。其实这里面的since_id就是原来的page,只不过有点麻烦需要我们去找。到此这个爬虫程序就差不多写完了。
完整代码:
import requests
from urllib.parse import urlencode
base_url = 'https://m.weibo.cn/api/container/getIndex?'
from pyquery import PyQuery as pq
headers = {
'host': 'm.weibo.cn',
'Referer':'https://m.weibo.cn/u/5934019851',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/84.0.4147.89 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(since_id):
params = {
'type': 'uid',
'value': '5934019851',
'containerid': '1076035934019851',
}
if since_id != 0:
params['since_id'] = since_id
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print("Error", e.args)
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['time'] = item.get('created_at')
weibo['text'] = pq(item.get('text')).text()
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
if __name__ == '__main__':
since_id = 0
for page in range(1, 11):
json = get_page(since_id)
since_id = json.get('data').get('cardlistInfo').get('since_id')
results = parse_page(json)
for result in results:
print(result)
注:如果向copy过去自己运行的话需要修改headers里面的User_Agent信息。
部分运行结果:

后记
因为是按照崔庆才老师的爬虫书来学的,他这个书写的有一点早,好像是18年,很多的东西跟现在都不一样了,包括里面请求的内容啥的,最重要的一点是请求的参数不同,就是原来的那个page变成了since_id,刚开始的时候真的是一筹莫展,随说原来的代码也能够运行,但是总感觉哪里怪怪的,然后我就想办法用since_id代替page,中间的过程用了蛮久,但是最后解决了还是很nice的,最重要的是思想,思想是对的,在整理一些细节的地方就能够完美的解决问题了。