ASCII控制字符 Unicode编码
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCⅡ)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其余西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。php
ASCII第一次以规范标准的型态发表是在1967年,最后一次更新则是在1986年,至今为止共定义了128个字符,其中33个字符没法显示(这是以现今操做系统为依归,但在DOS模式下可显示出一些诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已经是陈废的控制字符,控制字符的用途主要是用来操控已经处理过的文字,在33个字符以外的是95个可显示的字符,包含用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。html
ASCII控制字符
| 二进制 | 十进制 | 十六进制 | 缩写 | 能够显示的表示法/Unicode表示法 | 名称/意义 |
|---|
| 0000 0000 | 0 | 00 | NUL | ␀ | 空字符(Null) |
| 0000 0001 | 1 | 01 | SOH | ␁ | 标题开始 |
| 0000 0010 | 2 | 02 | STX | ␂ | 本文开始 |
| 0000 0011 | 3 | 03 | ETX | ␃ | 本文结束 |
| 0000 0100 | 4 | 04 | EOT | ␄ | 传输结束 |
| 0000 0101 | 5 | 05 | ENQ | ␅ | 请求 |
| 0000 0110 | 6 | 06 | ACK | ␆ | 确认回应 |
| 0000 0111 | 7 | 07 | BEL | ␇ | 响铃 |
| 0000 1000 | 8 | 08 | BS | ␈ | 退格 |
| 0000 1001 | 9 | 09 | HT | ␉ | 水平定位符号 |
| 0000 1010 | 10 | 0A | LF | ␊ | 换行键 |
| 0000 1011 | 11 | 0B | VT | ␋ | 垂直定位符号 |
| 0000 1100 | 12 | 0C | FF | ␌ | 换页键 |
| 0000 1101 | 13 | 0D | CR | ␍ | 归位键 |
| 0000 1110 | 14 | 0E | SO | ␎ | 取消变换(Shift out) |
| 0000 1111 | 15 | 0F | SI | ␏ | 启用变换(Shift in) |
| 0001 0000 | 16 | 10 | DLE | ␐ | 跳出数据通信 |
| 0001 0001 | 17 | 11 | DC1 | ␑ | 设备控制一(XON 启用软件速度控制) |
| 0001 0010 | 18 | 12 | DC2 | ␒ | 设备控制二 |
| 0001 0011 | 19 | 13 | DC3 | ␓ | 设备控制三(XOFF 停用软件速度控制) |
| 0001 0100 | 20 | 14 | DC4 | ␔ | 设备控制四 |
| 0001 0101 | 21 | 15 | NAK | ␕ | 确认失败回应 |
| 0001 0110 | 22 | 16 | SYN | ␖ | 同步用暂停 |
| 0001 0111 | 23 | 17 | ETB | ␗ | 区块传输结束 |
| 0001 1000 | 24 | 18 | CAN | ␘ | 取消 |
| 0001 1001 | 25 | 19 | EM | ␙ | 链接介质中断 |
| 0001 1010 | 26 | 1A | SUB | ␚ | 替换 |
| 0001 1011 | 27 | 1B | ESC | ␛ | 跳出 |
| 0001 1100 | 28 | 1C | FS | ␜ | 文件分割符 |
| 0001 1101 | 29 | 1D | GS | ␝ | 组群分隔符 |
| 0001 1110 | 30 | 1E | RS | ␞ | 记录分隔符 |
| 0001 1111 | 31 | 1F | US | ␟ | 单元分隔符 |
| 0111 1111 | 127 | 7F | DEL | ␡ | 删除 |
ASCII可显示字符
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|
| 0010 0000 | 32 | 20 | (空格)(␠) | | 0010 0001 | 33 | 21 | ! | | 0010 0010 | 34 | 22 | " | | 0010 0011 | 35 | 23 | # | | 0010 0100 | 36 | 24 | $ | | 0010 0101 | 37 | 25 | % | | 0010 0110 | 38 | 26 | & | | 0010 0111 | 39 | 27 | ' | | 0010 1000 | 40 | 28 | ( | | 0010 1001 | 41 | 29 | ) | | 0010 1010 | 42 | 2A | * | | 0010 1011 | 43 | 2B | + | | 0010 1100 | 44 | 2C | , | | 0010 1101 | 45 | 2D | - | | 0010 1110 | 46 | 2E | . | | 0010 1111 | 47 | 2F | / | | 0011 0000 | 48 | 30 | 0 | | 0011 0001 | 49 | 31 | 1 | | 0011 0010 | 50 | 32 | 2 | | 0011 0011 | 51 | 33 | 3 | | 0011 0100 | 52 | 34 | 4 | | 0011 0101 | 53 | 35 | 5 | | 0011 0110 | 54 | 36 | 6 | | 0011 0111 | 55 | 37 | 7 | | 0011 1000 | 56 | 38 | 8 | | 0011 1001 | 57 | 39 | 9 | | 0011 1010 | 58 | 3A | : | | 0011 1011 | 59 | 3B | ; | | 0011 1100 | 60 | 3C | < | | 0011 1101 | 61 | 3D | = | | 0011 1110 | 62 | 3E | > | | 0011 1111 | 63 | 3F | ? |
| |
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|
| 0100 0000 | 64 | 40 | @ | | 0100 0001 | 65 | 41 | A | | 0100 0010 | 66 | 42 | B | | 0100 0011 | 67 | 43 | C | | 0100 0100 | 68 | 44 | D | | 0100 0101 | 69 | 45 | E | | 0100 0110 | 70 | 46 | F | | 0100 0111 | 71 | 47 | G | | 0100 1000 | 72 | 48 | H | | 0100 1001 | 73 | 49 | I | | 0100 1010 | 74 | 4A | J | | 0100 1011 | 75 | 4B | K | | 0100 1100 | 76 | 4C | L | | 0100 1101 | 77 | 4D | M | | 0100 1110 | 78 | 4E | N | | 0100 1111 | 79 | 4F | O | | 0101 0000 | 80 | 50 | P | | 0101 0001 | 81 | 51 | Q | | 0101 0010 | 82 | 52 | R | | 0101 0011 | 83 | 53 | S | | 0101 0100 | 84 | 54 | T | | 0101 0101 | 85 | 55 | U | | 0101 0110 | 86 | 56 | V | | 0101 0111 | 87 | 57 | W | | 0101 1000 | 88 | 58 | X | | 0101 1001 | 89 | 59 | Y | | 0101 1010 | 90 | 5A | Z | | 0101 1011 | 91 | 5B | [ | | 0101 1100 | 92 | 5C | \ | | 0101 1101 | 93 | 5D | ] | | 0101 1110 | 94 | 5E | ^ | | 0101 1111 | 95 | 5F | _ |
| |
| 二进制 | 十进制 | 十六进制 | 图形 |
|---|
| 0110 0000 | 96 | 60 | ` | | 0110 0001 | 97 | 61 | a | | 0110 0010 | 98 | 62 | b | | 0110 0011 | 99 | 63 | c | | 0110 0100 | 100 | 64 | d | | 0110 0101 | 101 | 65 | e | | 0110 0110 | 102 | 66 | f | | 0110 0111 | 103 | 67 | g | | 0110 1000 | 104 | 68 | h | | 0110 1001 | 105 | 69 | i | | 0110 1010 | 106 | 6A | j | | 0110 1011 | 107 | 6B | k | | 0110 1100 | 108 | 6C | l | | 0110 1101 | 109 | 6D | m | | 0110 1110 | 110 | 6E | n | | 0110 1111 | 111 | 6F | o | | 0111 0000 | 112 | 70 | p | | 0111 0001 | 113 | 71 | q | | 0111 0010 | 114 | 72 | r | | 0111 0011 | 115 | 73 | s | | 0111 0100 | 116 | 74 | t | | 0111 0101 | 117 | 75 | u | | 0111 0110 | 118 | 76 | v | | 0111 0111 | 119 | 77 | w | | 0111 1000 | 120 | 78 | x | | 0111 1001 | 121 | 79 | y | | 0111 1010 | 122 | 7A | z | | 0111 1011 | 123 | 7B | { | | 0111 1100 | 124 | 7C | | | | 0111 1101 | 125 | 7D | } | | 0111 1110 | 126 | 7E | ~ |
|
| 二进制 | 十进制 | 十六进制 | 缩写 | Unicode
表示法 | 脱出字符
表示法 | 名称/意义 |
|---|
| 0000 0000 | 0 | 00 | NUL | ␀ | ^@ | 空字符(Null) | | 0000 0001 | 1 | 01 | SOH | ␁ | ^A | 标题开始 | | 0000 0010 | 2 | 02 | STX | ␂ | ^B | 本文开始 | | 0000 0011 | 3 | 03 | ETX | ␃ | ^C | 本文结束 | | 0000 0100 | 4 | 04 | EOT | ␄ | ^D | 传输结束 | | 0000 0101 | 5 | 05 | ENQ | ␅ | ^E | 请求 | | 0000 0110 | 6 | 06 | ACK | ␆ | ^F | 确认回应 | | 0000 0111 | 7 | 07 | BEL | ␇ | ^G | 响铃 | | 0000 1000 | 8 | 08 | BS | ␈ | ^H | 退格 | | 0000 1001 | 9 | 09 | HT | ␉ | ^I | 水平定位符号 | | 0000 1010 | 10 | 0A | LF | ␊ | ^J | 换行键 | | 0000 1011 | 11 | 0B | VT | ␋ | ^K | 垂直定位符号 | | 0000 1100 | 12 | 0C | FF | ␌ | ^L | 换页键 | | 0000 1101 | 13 | 0D | CR | ␍ | ^M | Enter键 | | 0000 1110 | 14 | 0E | SO | ␎ | ^N | 取消变换(Shift out) | | 0000 1111 | 15 | 0F | SI | ␏ | ^O | 启用变换(Shift in) | | 0001 0000 | 16 | 10 | DLE | ␐ | ^P | 跳出数据通信 | | 0001 0001 | 17 | 11 | DC1 | ␑ | ^Q | 设备控制一(XON 激活软件速度控制) | | 0001 0010 | 18 | 12 | DC2 | ␒ | ^R | 设备控制二 | | 0001 0011 | 19 | 13 | DC3 | ␓ | ^S | 设备控制三(XOFF 停用软件速度控制) | | 0001 0100 | 20 | 14 | DC4 | ␔ | ^T | 设备控制四 | | 0001 0101 | 21 | 15 | NAK | ␕ | ^U | 确认失败回应 | | 0001 0110 | 22 | 16 | SYN | ␖ | ^V | 同步用暂停 | | 0001 0111 | 23 | 17 | ETB | ␗ | ^W | 区块传输结束 | | 0001 1000 | 24 | 18 | CAN | ␘ | ^X | 取消 | | 0001 1001 | 25 | 19 | EM | ␙ | ^Y | 链接介质中断 | | 0001 1010 | 26 | 1A | SUB | ␚ | ^Z | 替换 | | 0001 1011 | 27 | 1B | ESC | ␛ | ^[ | 退出键 | | 0001 1100 | 28 | 1C | FS | ␜ | ^\ | 文件分区符 | | 0001 1101 | 29 | 1D | GS | ␝ | ^] | 组群分隔符 | | 0001 1110 | 30 | 1E | RS | ␞ | ^^ | 记录分隔符 | | 0001 1111 | 31 | 1F | US | ␟ | ^_ | 单元分隔符 | | | 0111 1111 | 127 | 7F | DEL | ␡ | ^? | 删除 |
|
字符编码的前世此生
前言
不少程序员对字符编码不太理解,虽然他们大概知道 ASCII、UTF八、GBK、Unicode 等术语概念,但在写代码过程当中仍是会遇到各类奇怪的编码问题,在 Java 中最多见的是乱码,而 Python 开发中遇到最多的是编码错误,如:UnicodeDecodeError, UnicodeEncodeError,几乎每一个 Python 开发者都会碰到这种问题,对此都是束手无策,这篇文章从字符编码的起源开始,讲述了编程中应该如何应对编码的问题,经过理解本文,你能够从容地定位、分析、解决字符编码相关的问题。
说到「字符编码」咱们先要理解什么是编码以及为何要编码。
什么是编码
但凡学过计算机的同窗都知道,计算机只能处理0和1组成的二进制数据,人类借助计算机所看到的、听到的任何信息,包括:文本、视频、音频、图片在计算机中都是以二进制形式进行存储和运算。计算机善于处理二进制数据,可是人类对于二进制数据显得捉襟见肘,为了下降人与计算机的交流成本,人们决定把每一个字符进行编号,好比给字母 A 的编号是 65,对应的二进制数是「01000001」,当把 A 存到计算机中时就用 01000001 来代替,当要加载显示在文件中或网页中用来阅览时,就把二进制数转换成字符 A,这个过程当中就会涉及到不一样格式数据之间的转换。
编码(encode) 是把数据从一种形式转换为另一种形式的过程,它是一套算法,好比这里的字符 A 转换成 01000001 就是一次编码的过程, 解码(decode) 就是编码的逆过程。今天咱们讨论的是关于字符的编码,是字符和二进制数据之间转换的算法。密码学中的加密解密有时也称为编码与解码,不过它不在本文讨论范围内。

什么是字符集
字符集是一个系统支持的全部抽象字符的集合。它是各类文字和符号的总称,常见的字符集种类包括 ASCII 字符集、GBK 字符集、Unicode字符集等。不一样的字符集规定了有限个字符,好比:ASCII 字符集只含有拉丁文字字母,GBK 包含了汉字,而 Unicode 字符集包含了世界上全部的文字符号。
有人不由要问,字符集与字符编码是什么关系?别急,先往下看。
ASCII:字符集与字符编码的起源
世界上第一台计算机,1945年由美国宾夕法尼亚大学的两位教授-莫奇利和埃克特设计和研制出来,美国人起草了计算机的第一份字符集和编码标准,叫 ASCII(American Standard Code for Information Interchange,美国信息交换标准代码),一共规定了 128 个字符及对应的二进制转换关系,128 个字符包括了可显示的26个字母(大小写)、10个数字、标点符号以及特殊的控制符,也就是英语与西欧语言中常见的字符,这128个字符用一个字节来表示绰绰有余,由于一个字节能够表示256个字符,因此当前只利用了字节的7位,最高位用来看成奇偶校验。以下图因此,字符小写 a 对应 01100001,大写 A 对应 01000001。
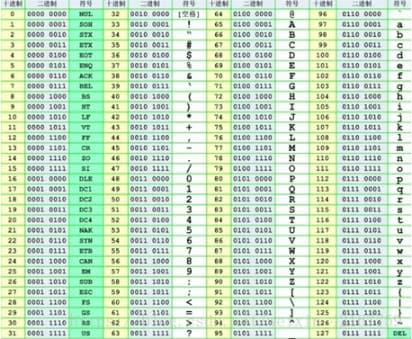
ASCII 字符集 是字母、数字、标点符号以及控制符(回车、换行、退格)等组成的128个字符。ASCII 字符编码 是将这128个字符转换为计算机可识别的二进制数据的一套规则(算法)。如今能够回答前面的那个问题了,一般来讲,字符集同时定义了一套同名的字符编码规则,例如 ASCII 就定义了字符集以及字符编码,固然这不是绝对的,好比 Unicode 就只定义了字符集,而对应的字符编码是 UTF-8,UTF-16。
ASCII 由美国国家标准学会制定,1967年定案,最初是美国国家标准,后来被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准,适用于全部拉丁文字字母。
EASCII:扩展的ASCII
随着计算机的不断普及,计算机开始被西欧等国家使用,而后西欧语言中还有不少字符不在 ASCII 字符集中,这给他们使用计算机形成了很大的限制,就比如在中国,你只能用英语跟人家交流同样。因而乎,他们想着法子把 ASCII 字符集进行扩充,觉得 ASCII 只使用了字节的前 7 位,若是把第八位也利用起来,那么可表示的字符个数就是 256。这就是后来的 EASCII(Extended ASCII,延伸美国标准信息交换码)EASCII 码比 ASCII 码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。
而后 EASCII 并无造成统一的标准,各国个商家都有本身的小算盘,都想在字节的高位作文章,好比 MS-DOS, IBM PC上使用了各自定义的编码字符集,为告终束这种混乱的局面,国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位元字符集的标准,叫 ISO 8859,全称ISO/IEC 8859,它在 ASCII 基础之上扩展而来,因此彻底 ASCII,ISO 8859 字符编码方案所扩展的这128个编码中,只有0xA0~0xFF(十进制为160~255)被使用,其实 ISO 8859是一组字符集的总称,旗下共包含了15个字符集,分别是 ISO 8859-1 ~ ISO 8859-15,ISO 8859-1 又称之为 Latin-1,它是西欧语言,其它的分别表明 中欧、南欧、北欧等字符集。

GB2312:知足国人需求的字符集
后来,计算机开始普及到了中国,但面临的一个问题就是字符,汉字博大精深,经常使用汉字有3500个,已经大大超出了 ASCII 字符集所能表示的字符范围了,即便是 EASCII 也显得杯水车薪,1981 年国家标准化管理委员会定了一套字符集叫 GB2312 ,每一个汉字符号由两个字节组成,理论上它能够表示65536个字符,不过它只收录了7445个字符,6763个汉字和682个其余字符,同时它可以兼容 ASCII,ASCII 中定义的字符只占用一个字节的空间。
GB2312 所收录的汉字已经覆盖中国大陆99.75%的使用频率,可是对一些罕见的字和繁体字还有不少少数民族使用的字符都无法处理,因而后来就在 GB2312 的基础上建立了一种叫 GBK 的字符编码,GBK 不只收录了27484 个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。GBK 是利用了 GB2312 中未被使用的编码空间上进行扩充,因此它能彻底兼容 GB2312和 ASCII。而 GB 18030 是现时最新的字符集,兼容 GB 2312-1980 和 GBK, 共收录汉字70244个,采用多字节编码,每一个字符能够有一、二、4个字节组成,某种意义上它能容纳161 万个字符,包含繁体汉字以及日韩汉字,单字节与ASCII兼容,双字节与GBK标准兼容。
Unicode :统一江湖的字符集
尽管咱们有了属于本身的字符集和字符编码 GBK,可世界上还有不少国家拥有本身的语言和文字,好比日本用 JIS,台湾用 BIG5,不一样国家之间交流起来就很困难,由于没有统一的编码标准,可能同一个字符,在A国家用两字字节存储,而到了B国家是3个字节,这样很容易出现编码问题,因而在 1991 年,国际标准化组织和统一码联盟组织各自开发了 ISO/IEC 10646(USC)和 Unicode 项目,这两个项目的目的都是但愿用一种字符集来统一全世界全部字符,不过很快双方都意识到世界上并不须要两个不兼容的字符集。因而他们就编码问题进行了很是友好地会晤,决定彼此把工做内容合并,虽然项目仍是独立存在,各自发布各自的标准,但前提是二者必须保持兼容。不过因为 Unicode 这一名字比较好记,于是它使用更为普遍,成为了事实上的统一编码标准。
以上是对字符集历史的一个简要回顾,如今重点来讲说Unicode,Unicode 是一个囊括了世界上全部字符的字符集,其中每个字符都对应有惟一的编码值(code point),注意了!它不是字符编码,仅仅是字符集而已, Unicode 字符如何进行编码,能够是 UTF-八、UTF-1六、甚至用 GBK 来编码。 例如:
>>> a = u"好" >>> a u'\u597d' >>> b = a.encode( "utf-8" )>>> b '\xe5\xa5\xbd' >>>>>> b = a.encode( "gbk" )>>> b '\xba\xc3'
Unicode 自己并无规定一个字符到底是用一个仍是三个或者四个字节表示 。Unicode 只规定了每一个字符对应到惟一的代码值(code point),代码值 从 0000 ~ 10FFFF 共 1114112 个值 , 真正存储的时候须要多少个字节是由具体的编码格式决定的。 好比:字符 「A」用 UTF-8 的格式编码来存储就只占用1个字节,用 UTF-16 就占用2个字节,而用 UTF-32 存储就占用4个字节。
UTF-8:Unicode编码
UTF( Unicode Transformation Format)编码 和 USC(Universal Coded Character Set) 编码分别是 Unicode 、ISO/IEC 10646 编码体系里面两种编码方式,UCS 分为 UCS-2 和 UCS-4,而 UTF 常见的种类有 UTF-八、UTF-1六、UTF-32。由于 Unicode 与 USC 两种字符集是相互兼容的,因此这几种编码格式也有着对应的等值关系。
UCS-2 使用两个定长的字节来表示一个字符,UTF-16 也是使用两个字节,不过 UTF-16 是变长的(网上不少错误的说法说 UTF-16是定长的),遇到两个字节无法表示时,会用4个字节来表示,所以 UTF-16 能够看做是在 UCS-2 的基础上扩展而来的。而 UTF-32 与 USC-4 是彻底等价的,使用4个字节表示,显然,这种方式浪费的空间比较多。
UTF-8 的优点是:它以单字节为单位用 1~4 个字节来表示一个字符,从首字节就能够判断一个字符的UTF-8编码有几个字节。若是首字节以0开头,确定是单字节编码,若是以110开头,确定是双字节编码,若是是1110开头,确定是三字节编码,以此类推。除了单字节外,多字节UTF-8码的后续字节均以10开头。
1~4 字节的 UTF-8 编码看起来是这样的:
0 xxxxxxx 110 xxxxx 10 xxxxxx 1110 xxxx 10 xxxxxx 10 xxxxxx 11110 xxx 10 xxxxxx 10 xxxxxx 10 xxxxxx
- 单字节可编码的 Unicode 范围:\u0000~\u007F(0~127)
- 双字节可编码的 Unicode 范围:\u0080~\u07FF(128~2047)
- 三字节可编码的 Unicode 范围:\u0800~\uFFFF(2048~65535)
- 四字节可编码的 Unicode 范围:\u10000~\u1FFFFF(65536~2097151)
UTF-8 兼容了 ASCII,在数据传输和存储过程当中节省了空间,其二是UTF-8 不须要考虑大小端问题。这两点都是 UTF-16 的劣势。不过对于中文字符,用 UTF-8 就要用3个字节,而 UTF-16 只需2个字节。而UTF-16 的优势是在计算字符串长度,执行索引操做时速度会很快。Java 内部使用 UTF-16 编码方案。而 Python3 使用 UTF-8。UTF-8 编码在互联网领域应用更加普遍。
来看一张图,下图是Windows平台保存文件时可选择的字符编码类型,你能够指定系统以什么样的编码格式来存储文件,ANSI 是 ISO 8859-1的超集,之因此在 Windows下有 Unicode 编码这样一种说法,实际上是 Windows 的一种错误表示方法,或许是由于历史缘由一直沿用至今,其实它真正表示的是 UTF-16 编码,更具体一点是 UTF-16小端,什么是大端和小端呢?

大端与小端
大小端是数据在存储器中的存放顺序,大端模式,是指数据的高字节在前,保存在内存的低地址中,与人类的读写法一致,数据的低字节在后,保存在内存的高地址中,小端与之相反,小端模式,是指数据的高字节在后,保存在内存的高地址中,而数据的低字节在前,保存在内存的低地址中例如,十六进制数值 0x1234567 的大端字节序和小端字节序的写法:

至于为何会有大端和小端之分呢?对于 16 位或者 32 位的处理器,因为寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节排放的问题,由于不一样操做系统读取多字节的顺序不同,x86和通常的OS(如windows,FreeBSD,Linux)使用的是小端模式。但好比Mac OS是大端模式。所以就致使了大端存储模式和小端存储模式的存在,二者并无孰优孰劣。
为何 UTF-8 不须要考虑大小端问题?
UTF-8 的编码单元是1个字节,因此就不用考虑字节序问题。而 UTF-16 是用 2个字节来编码 Unicode 字符,编码单位是两个字节,所以须要考虑字节序问题,由于2个字节哪一个存高位哪一个存低位须要肯定。
Python2 中的字符编码
如今总算把理论说完了,再来讲说 Python 中的编码问题,也是每一个Python开发者最关心、最常常遇到的问题,Python 的诞生时间比 Unicode 还要早几年,因此,Python的第一个版本一直延续到Python2.7,Python 的默认编码都是 ASCII。
>>> import sys >>> sys.getdefaultencoding() 'ascii'
因此在 Python 源代码,要可以正常保存中文字符就必须先指定utf
8 或者 gbk 格式
# coding=utf-8 或者是: #!/usr/bin/python# -*- coding: utf-8 -*-
str 与 unicode
在前面咱们介绍过字符,这里还有必要重复一下字符和字节的区别,字符就是一个符号,好比一个汉字、一个字母、一个数字、一个标点均可以称为一个字符,而字节就是字符就是编码以后转换而成的二进制序列,一个字节是8个比特位。例如字符 "p" 存储到硬盘是一串二进制数据 01110000,占用一个字节。字节方便存储和网络传输,而字符用于显示方便阅读。
在Python2中,字符与字节的表示很微妙,二者的界限很模糊,Python2 中把字符串分为 unicode 和 str 两种类型。本质上 str 类型是二进制字节序列, unicode 类型的字符串是字符,下面的示例代码能够看出 str 类型的 "禅" 打印出来是十六进制的 \xec\xf8 ,对应的二进制字节序列就是 '11101100 11111000'。
>>> s = '禅' >>> s '\xec\xf8' >>> type (s)< type 'str' >
而 unicode 类型的 u"禅" 对应的 unicode 符号是 u'\u7985':
>>> u = u"禅" >>> u u'\u7985' >>> type (u)< type 'unicode' >
咱们要把 unicode 字符保存到文件或者传输到网络就须要通过编码处理转换成二进制形式的 str 类型,因而 python 的字符串提供了 encode 方法,从 unicode 转换到 str,反之亦然。
encode:
>>> u = u"禅" >>> u u'\u7985' >>> u.encode( "utf-8" ) '\xe7\xa6\x85'
decode:
>>> s = "禅" >>> s.decode( "utf-8" ) u'\u7985' >>>
很多初学者怎么也记不住 str 与 unicode 之间的转换用 encode 仍是 decode,若是你记住了 str 本质上实际上是一串二进制数据,而 unicode 是字符(符号),编码(encode)就是把字符(符号)转换为 二进制数据的过程,所以 unicode 到 str 的转换要用 encode 方法,反过来就是用 decode 方法。
encoding always takes a Unicode string and returns a bytes sequence, and decoding always takes a bytes sequence and returns a Unicode string".
清楚了 str 与 unicode 之间的转换关系以后,咱们来看看何时会出现 UnicodeEncodeError、UnicodeDecodeError 错误。
UnicodeEncodeError
UnicodeEncodeError 发生在 unicode 字符串转换成 str 字节序列的时候,来看一个例子,把一串 unicode 字符串保存到文件。
# -*- coding:utf-8 -*- def main (): name = u'Python之禅' f = open ( "output.txt" , "w" ) f.write(name)
错误日志:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 6-7: ordinal not in range(128)
为何会出现 UnicodeEncodeError?
由于调用 write 方法时,程序会把字符通过编码转换成二进制字节序列,内部会有 unicode 到 str 的编码转换过程,程序会先判断字符串是什么类型,若是是 str,就直接写入文件,不须要编码,由于 str 类型的字符串自己就是一串二进制的字节序列了。若是字符串是 unicode 类型,那么它会先调用 encode 方法把 unicode 字符串转换成二进制形式的 str 类型,才保存到文件,而 Python2中,encode 方法默认使用 ascii 进行 encde。
至关于:
>>> u"Python之禅" .encode( "ascii" )
可是,咱们知道 ASCII 字符集中只包含了128个拉丁字母,不包括中文字符,所以 出现了 'ascii' codec can't encode characters 的错误。要正确地使用 encode ,就必须指定一个包含了中文字符的字符集,好比:UTF-八、GBK。
>>> u"Python之禅" .encode( "utf-8" ) 'Python\xe4\xb9\x8b\xe7\xa6\x85' >>> u"Python之禅" .encode( "gbk" ) 'Python\xd6\xae\xec\xf8'
因此要把 unicode 字符串正确地写入文件,就应该预先把字符串进行 UTF-8 或 GBK 编码转换。
def main (): name = u'Python之禅' name = name.encode( 'utf-8' ) with open ( "output.txt" , "w" ) as f: f.write(name)
或者直接写str类型的字符串:
def main (): name = 'Python之禅' with open ( "output.txt" , "w" ) as f: f.write(name)
固然,把 unicode 字符串正确地写入文件不止一种方式,但原理是同样的,这里再也不介绍,把字符串写入数据库,传输到网络都是一样的原理。
UnicodeDecodeError
UnicodeDecodeError 发生在 str 类型的字节序列解码成 unicode 类型的字符串时:
>>> a = u"禅" >>> a u'\u7985' >>> b = a.encode( "utf-8" )>>> b '\xe7\xa6\x85' >>> b.decode( "gbk" )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> UnicodeDecodeError : 'gbk' codec can 't decode byte 0x85 in position 2: incomplete multibyte sequence
把一个通过 UTF-8 编码后生成的字节序列 '\xe7\xa6\x85' 再用 GBK 解码转换成 unicode 字符串时,出现 UnicodeDecodeError,由于 (对于中文字符)GBK 编码只占用两个字节,而 UTF-8 占用3个字节,用 GBK 转换时,还多出一个字节,所以它无法解析。避免 UnicodeDecodeError 的关键是保持 编码和解码时用的编码类型一致。
这也回答了文章开头说的字符 "禅",保存到文件中有可能占3个字节,有可能占2个字节,具体处决于 encode 的时候指定的编码格式是什么。
再举一个 UnicodeDecodeError 的例子:
>>> x = u"Python" >>> y = "之禅" >>> x + yTraceback (most recent call last): File "<stdin>" , line 1 , in <module> UnicodeDecodeError : 'ascii' codec can 't decode byte 0xe4 in position 0: ordinal not in range(128) >>>
str 与 unicode 字符串 执行 + 操做时,Python 会把 str 类型的字节序列隐式地转换成(解码)成 和 x 同样的 unicode 类型,但Python是使用默认的 ascii 编码来转换的,而 ASCII字符集中不包含有中文,因此报错了。至关于:
>>> y.decode( 'ascii' )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> UnicodeDecodeError : 'ascii' codec can 't decode byte 0xe4 in position 0: ordinal not in range(128)
正确地方式应该是找到一种包含有中文字符的字符编码,好比 UTF-8或者 GBK 显示地把 y 进行解码转换成 unicode 类型:
>>> x = u"Python" >>> y = "之禅" >>> y = y.decode( "utf-8" )>>> x + y u'Python\u4e4b\u7985'
Python3 中的字符串与字节序列
Python3 对字符串和字符编码进行了很完全的重构,彻底不兼容 Python2,同时也不少想迁移到 Python3 的项目带来了很大的麻烦,Python3 把系统默认编码设置为 UTF-8,字符和二进制字节序列区分得更清晰,分别用 str 和 bytes 表示。文本字符所有用 str 类型表示,str 能表示 Unicode 字符集中全部字符,而二进制字节数据用一种全新的数据类型,用 bytes 来表示,尽管 Python2 中也有 bytes 类型,但那只不过是 str 的一个别名。
str
>>> a = "a" >>> a 'a' >>> type (a)< class ' str '> >>> b = "禅" >>> b '禅' >>> type (b)< class ' str '>
bytes
Python3 中,在字符引号前加‘b’,明确表示这是一个 bytes 类型的对象,实际上它就是一组二进制字节序列组成的数据,bytes 类型能够是 ASCII 范围内的字符和其它十六进制形式的字符数据,但不能用中文等非 ASCII 字符表示。
>>> c = b 'a' >>> cb 'a' >>> type (c)< class ' bytes '> >>> d = b '\xe7\xa6\x85' >>> db '\xe7\xa6\x85' >>> type (d)< class ' bytes '> >>>>>> e = b '禅' File "<stdin>" , line 1 SyntaxError : bytes can only contain ASCII literal characters.
bytes 类型提供的操做和 str 同样,支持分片、索引、基本数值运算等操做。可是 str 与 bytes 类型的数据不能执行 + 操做,尽管在python2中是可行的。
>>> b"a"+b"c"b'ac'>>> b"a"*2b'aa'>>> b"abcdef\xd6"[1:]b'bcdef\xd6'>>> b"abcdef\xd6"[-1]214>>> b"a" + "b"Traceback (most recent call last): File "<stdin>", line 1, in <module>TypeError: can't concat bytes to str
python2 与 python3 字节与字符对比:
| python2 | python3 | 表现 | 转换 | 做用 |
| str | bytes | 字节 | encode | 存储 |
| unicode | str | 字符 | decode | 显示 |
总结
- 字符编码本质上是字符到字节的转换过程
- 字符集的演进过程是:ascii、eascii、ios8895-x,gb2312... Unicode
- Unicode 是字符集,对应的编码格式有UTF-8,UTF-16
- 字节序列存储的时候有大小端之分
- python2 中字符与字节分别用 unicode 和 str 类型表示
- python3 中字符与字节分别用 str 与 bytes 表示
参考的连接:ASSII码对照表 http://ascii.911cha.com/python
Unicode编码 http://www.cnblogs.com/lwqhp/p/3175817.htmlios
| 二进制 | 十进制 | 十六进制 | 缩写 | Unicode
表示法 | 脱出字符
表示法 | 名称/意义 |
|---|
| 0000 0000 | 0 | 00 | NUL | ␀ | ^@ | 空字符(Null) | | 0000 0001 | 1 | 01 | SOH | ␁ | ^A | 标题开始 | | 0000 0010 | 2 | 02 | STX | ␂ | ^B | 本文开始 | | 0000 0011 | 3 | 03 | ETX | ␃ | ^C | 本文结束 | | 0000 0100 | 4 | 04 | EOT | ␄ | ^D | 传输结束 | | 0000 0101 | 5 | 05 | ENQ | ␅ | ^E | 请求 | | 0000 0110 | 6 | 06 | ACK | ␆ | ^F | 确认回应 | | 0000 0111 | 7 | 07 | BEL | ␇ | ^G | 响铃 | | 0000 1000 | 8 | 08 | BS | ␈ | ^H | 退格 | | 0000 1001 | 9 | 09 | HT | ␉ | ^I | 水平定位符号 | | 0000 1010 | 10 | 0A | LF | ␊ | ^J | 换行键 | | 0000 1011 | 11 | 0B | VT | ␋ | ^K | 垂直定位符号 | | 0000 1100 | 12 | 0C | FF | ␌ | ^L | 换页键 | | 0000 1101 | 13 | 0D | CR | ␍ | ^M | Enter键 | | 0000 1110 | 14 | 0E | SO | ␎ | ^N | 取消变换(Shift out) | | 0000 1111 | 15 | 0F | SI | ␏ | ^O | 启用变换(Shift in) | | 0001 0000 | 16 | 10 | DLE | ␐ | ^P | 跳出数据通信 | | 0001 0001 | 17 | 11 | DC1 | ␑ | ^Q | 设备控制一(XON 激活软件速度控制) | | 0001 0010 | 18 | 12 | DC2 | ␒ | ^R | 设备控制二 | | 0001 0011 | 19 | 13 | DC3 | ␓ | ^S | 设备控制三(XOFF 停用软件速度控制) | | 0001 0100 | 20 | 14 | DC4 | ␔ | ^T | 设备控制四 | | 0001 0101 | 21 | 15 | NAK | ␕ | ^U | 确认失败回应 | | 0001 0110 | 22 | 16 | SYN | ␖ | ^V | 同步用暂停 | | 0001 0111 | 23 | 17 | ETB | ␗ | ^W | 区块传输结束 | | 0001 1000 | 24 | 18 | CAN | ␘ | ^X | 取消 | | 0001 1001 | 25 | 19 | EM | ␙ | ^Y | 链接介质中断 | | 0001 1010 | 26 | 1A | SUB | ␚ | ^Z | 替换 | | 0001 1011 | 27 | 1B | ESC | ␛ | ^[ | 退出键 | | 0001 1100 | 28 | 1C | FS | ␜ | ^\ | 文件分区符 | | 0001 1101 | 29 | 1D | GS | ␝ | ^] | 组群分隔符 | | 0001 1110 | 30 | 1E | RS | ␞ | ^^ | 记录分隔符 | | 0001 1111 | 31 | 1F | US | ␟ | ^_ | 单元分隔符 | | | 0111 1111 | 127 | 7F | DEL | ␡ | ^? | 删除 |
|
标签:phphtmlpythonios程序员算法数据库编程windows网络
原文地址:https://blog.csdn.net/weixin_42167759/article/details/80421206
转载于:https://www.shangmayuan.com/a/5cbfba96a462473dbfcb637f.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)