什么是目标检测?简单来说就是“检测图片中物体所在的位置”。
本文只介绍用深度学习的方法进行目标检测,同过举出几个特性来帮助各位理解目标检测任务。同时建议学习目标检测应先具备物体人工智能算法基础和物体分类现实基础。
特性1——Bounding Box输出
为了得到物体的位置(即Bounding Box)的四个参数,bx、by、bh、bw,我们在最后再输出层上面多加四个神经元来输出这四个参数。同理,我们需要什么信息,就多加一个神经元来输出它。例如,我现在检测一张8x8x3的图片中苹果的位置,我们可以通过kernel_size=2x2x3,stride=2的卷积核连续三次提取特征,再用经过kernel_size=1x1x5,stride=1的卷积核,不难计算,最后的图片向量为1x1x5,即输出层有5个神经元,那我们可以将其中四个来作为Bounding Box的输出,一个作为confidence的输出。
或许有人会问,为什么这五个神经元会乖乖的输出Bounding Box的值以及confidence呢?
那因为最后的五个神经元就是我们的输出值,我们会根据这五个输出值进行不断的训练,将它“调教”为我们需要的功能,如果还不清楚整个流程,建议回去学一下反向传播的知识。
注:所以数据都为自己杜撰,不可实际运用。
尺寸计算公式:w = (w - kernel_size + 2padding)/stride +1
特性2——卷积层代替全连接层
目标检测的神经网络一个最明显的特性就是用卷积层代替了全连接层。
在我们做目标分类网络的时候,最后一层甚至许多层都会使用全连接层,而全连接层会吧所有的矩阵展开成一排,例如我们最后的feature_map(经过多次卷积之后的特征输出)是3x3x5,那么展开完应该是45个神经元。而这个45个神经元是代表整张图的feature的呀。所以如果用了全连接层,我们必须得针对整张图进行识别,这正符合了物体分类的任务。但是我们的目标检测,是为了找出图中物体的位置,这样显然会模糊了物体的位置。
让我们再看看用卷积层会如何。

卷积会使feature_map上的每一个点都在原图上面有所对应的区域,这个区域我们也称为感受野。感受野的大小并不是一定的,这我画的这副图中,feature_map的每一个点对应原图3x3的大小。所以如果我们要检测的物体刚好在左上角的3x3区域内,那么feature_map左上角标红的那五个神经元,就会输出该物体的BoundingBox的四个参数和自信度。
再啰嗦一下,输出层神经元的个数,也就是上图中feature_map的小方格(有45个)。它的多少是我们自己根据需要灵活调整的,方法十分简单,就是通过调整卷积核的大小,步长和数量。
特性3——anchor(default box)
在最后的feature_map中我们会生成像这样的几个default box,它们的尺寸和数量都是由我们自己定义的。例如下图就生成了4个不同比例的default box,这4个default box会成比例的映射到原图上面去,和原图的ground truth(真实框,我们预先标注好的问题的位置)进行比较,然后我们将IOU定义为default box/ground truth。一般来说,IOU大于0.5的我们称之为正样本,小于0.5的我们称之为负样本。

通过对default box的训练,我们可以是default box无限接近于ground truth。那么我们的目标位置检测任务不就完成了吗?
下面再让我们看看到底是如何把default box训练到无限接近ground truth的把。
特性4——位置损失函数
在运用损失函数之前,我们得先知道是要拿预测框(default box)的中心坐标和真实框(ground truth box)的中心坐标进行对比。我们会首先在众多default box(anchor)中选出和ground truth(真实框)IOU最大的那个框来进行训练。
这里以SSD采用的Smooth loss function为例子,其它也大同小异。其中x就是两个坐标的距离。
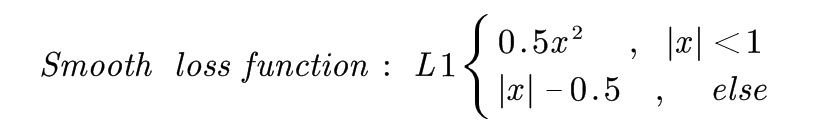
附上Pytorch的代码
location_loss = nn.SmoothL1Loss(reduction='none')
loc_loss = location_loss(ground truth, default box)
后记:
对于目标检测而言,损失函数是分为两个部分的,其中一个部分便是我上面提及的位置损失函数(Location Loss function),用于训练预测框,另一个部分就是我们经常接触到的交叉熵损失函数(CrossEntropy loss function),用于对目标进行分类。可以参考这篇博文CrossEntroyloss function