kaggle上的Give Me Some Credit一个8年前的老项目,网上的分析说明有很多,但本人通过阅读后,也发现了很多的问题。比如正常随着月薪越高,违约率会下降。但对于过低的月薪,违约率却为0等。
因此,本人写这个项目的目的是按照自己对数据的理解(可能有的地方是错的,希望大家指正),对网上相关的分析进行改进。(主要集中在数据预处理)
目录
由于整篇文章的篇幅过长,因此分为上下两部分。
- 上篇
- 理解数据
- 探索性数据分析
- 数据预处理
- 下篇
- 特征工程
- 构建模型
- 模型评估
- 评分卡建立
1.理解数据
项目背景
随着人们的消费观念的升级,所谓的“花明天的钱,圆今天的梦”。银行以及私营企业推出了各种各样的消费金融服务,具有代表性的是各大银行的信用卡,支付宝的花呗、京东白条,还有一些专门针对针对学生群体的平台,比如趣分期哈、分期乐之类的,把这些统称为信用卡用户。
只要涉及到金融借贷的,就有可能有坏账的存在。 每个公司都在用各种手段来降低坏账的发生,最常见的方法就是根据一定的规则,给每个用户打分进行预测,哪些用户可能会发生坏账,针对预测结果采取相应的措施。
本篇将针对历史坏账用户进行分析,分析坏账用户都有哪些特征,为后续的建模做准备。数据来自kaggle上的Give Me Some Credit根据信用评分建立原理,构建一个简易的信用评分卡模型——申请评分卡(A卡),对用户自动评分。
数据获取
现在kaggle上获取数据好像要注册手机号,但是国外……所以,把数据的链接贴在这里了。
链接:https://pan.baidu.com/s/1jl9-r3FItlpHX-HP3-7d_A
提取码:mtq0
导入数据
# 需要导入的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
import scipy
%matplotlib inline
sns.set(style="ticks")
pd.set_option("display.max_columns",None)#展示所有列数据
pd.set_option("display.max_rows",None)#展示所有行数据
# 画图显示中文
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from sklearn.ensemble import RandomForestRegressor as rfr
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression as LR
import scikitplot as skplt
train = pd.read_csv('./cs-training.csv',index_col=0)
test = pd.read_csv('./cs-test.csv',index_col=0)
查看数据基本信息
train.head()
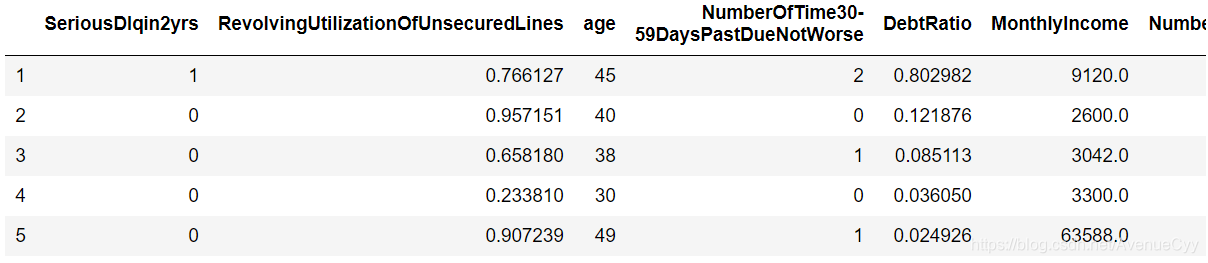
注:对测试数据也做同样的操作,这里只举例训练数据。
train.shape
(150000, 11)
test.shape
(101503, 11)
训练集数据150000个样本,11个特征。
测试集数据101503个样本,11个特征。
数据特征含义
- SeriousDlqin2yrs -----出现 90 天或更长时间的逾期行为(即定义好坏客户)
- RevolvingUtilizationOfUnsecuredLines ----- 贷款以及信用卡可用额度与总额度比例
- age ----- 借款人借款年龄
- NumberOfTime30-59DaysPastDueNotWorse----- 过去两年内出现35-59天逾期但是没有发展得更坏的次数
- DebtRatio----- 每月偿还债务,赡养费,生活费用除以月总收入
- MonthlyIncome -----月收入
- NumberOfOpenCreditLinesAndLoans -----开放式贷款和信贷数量
- NumberOfTimes90DaysLate -----过去两年内出现90天逾期或更坏的次数
- NumberRealEstateLoansOrLines -----抵押贷款和房地产贷款数量,包括房屋净值信贷额度
- NumberOfTime60-89DaysPastDueNotWorse -----过去两年内出现60-89天逾期但是没有发展得更坏的次数
- NumberOfDependents -----家庭中不包括自身的家属人数(配偶,子女等)
查看描述统计信息
train.describe([0.01,0.03,0.05,0.07,0.1,0.25,.5,.75,.9,.99]).T
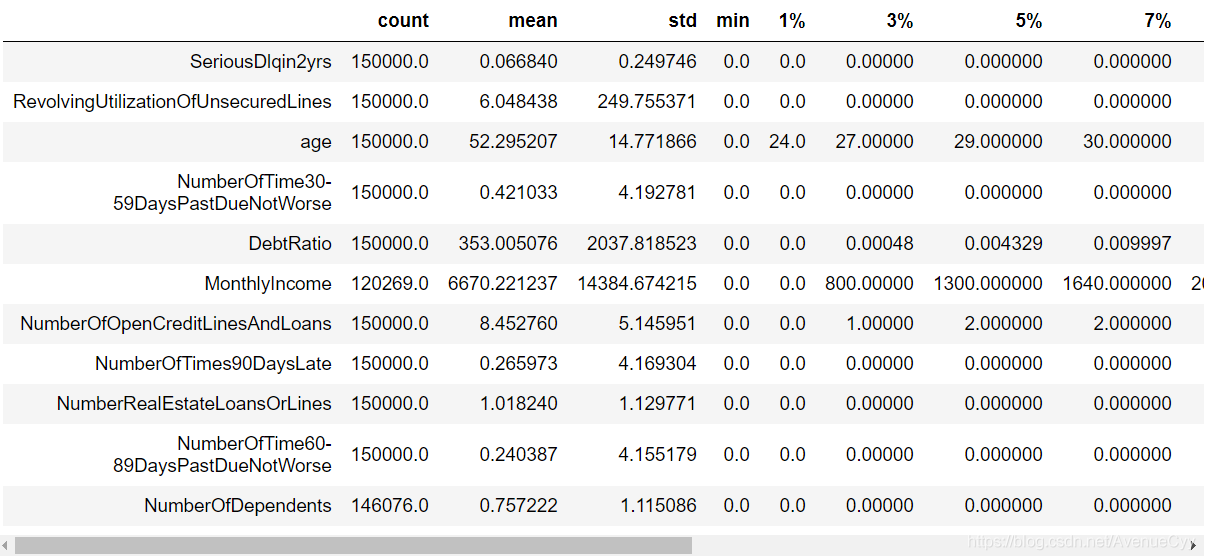
通过以上数据描述性信息可以看出:
- 有多个特征存在异常值。比如贷款额度与总额度比例存在大于1甚至几千的情况最大值为50708。年龄最小值为0,最大值为109的情况等等。这些异常值在数据探索性分析中将逐个进行说明。
- 多个特征存在有偏分布。比如贷款额度与总额度,月薪,负债率等特征。
train.info()

通过以上数据信息可以看出:
- 数据类型都为int或float,说明都是数值型的数据。
- 月薪和家属人数存在空缺值。
2.探索性数据分析
这是之前写的数据探索性分析,在分析时可以当做个参考,提供些思路。
目标特征分析:好坏客户特征
figure,ax = plt.subplots(figsize=(12,4))
train['SeriousDlqin2yrs'].value_counts().plot.pie(autopct='%1.1f%%')
plt.show()
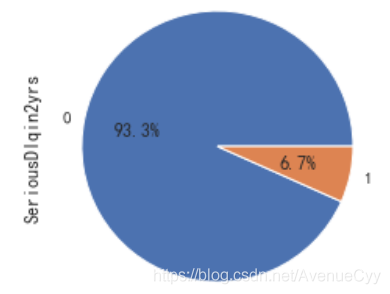
- 正样本(好客户)占比93.3%,负样本(坏客户)占比6.7%。说明客户一般为好客户。我们需要捕捉的是坏客户,但由于比例太过悬殊,此时样本不平衡,需要后续进行处理。
贷款额度与总额度比例
fig= plt.figure(figsize=(14,4))
ax1=fig.add_subplot(1,2,1)
sns.distplot(train['RevolvingUtilizationOfUnsecuredLines'],kde=True)
ax1=fig.add_subplot(1,2,2)
sns.boxplot(y=train['RevolvingUtilizationOfUnsecuredLines'])
plt.show()

- 样本分布极度不平衡。大部分的值都在“0左右”,存在大量的异常数据。需要进行进一步的分析。
- 而这些异常数据可能是由于没有除以总额度造成的,或是别的一些情况。这就需要借助具体的业务进行分析。
一般认为贷款额度与总额度比例小于1是合理的情况。因此先分析比例小于时,贷款额度与总额度比例和好坏客户之间的关系。
cut_num=[0,0.3,0.5,0.7,1,10,100,1000,10000]
get_compare_plot(train,feature_plot="RevolvingUtilizationOfUnsecuredLines",cut_num=cut_num,is_qcut=False)
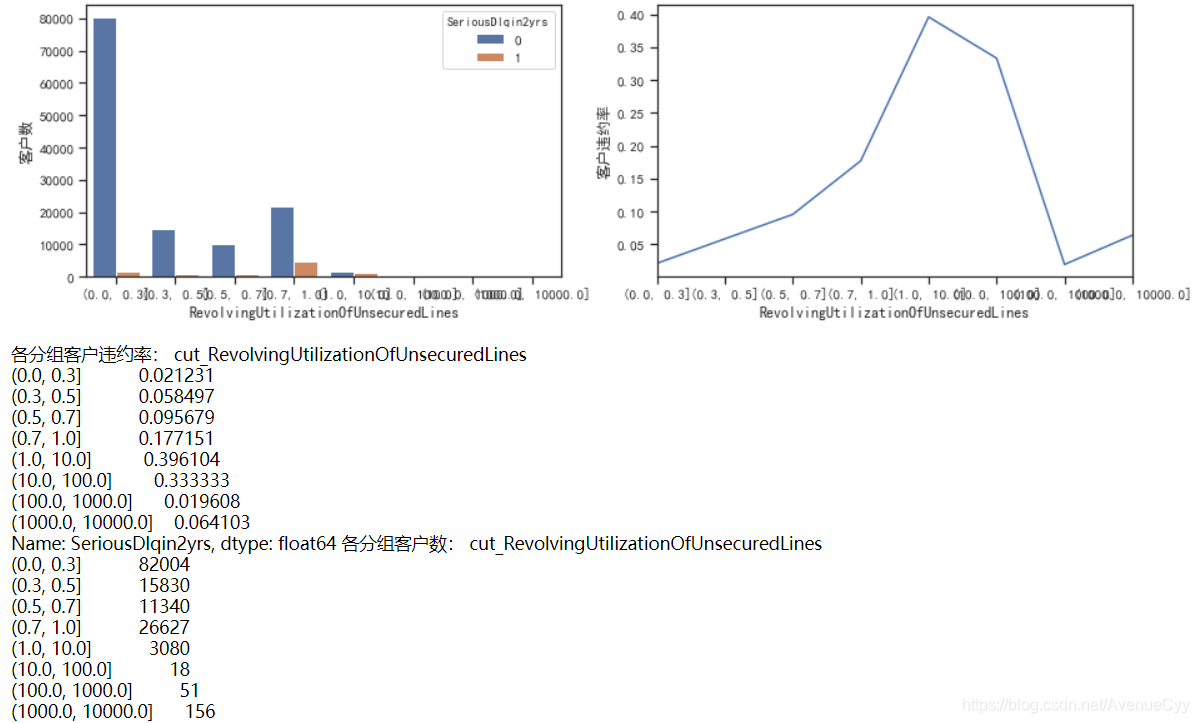
- 这里可以看到,当Revol(贷款额度与总额度比例) 小于1时,随着该比例的增加,客户违约率也在增加,符合业务逻辑。正常来说,应该是随着比例的增加,客户违约率也会增加,但是在大于1后,该规律发生了改变,因此对其进行进一步分析。
cut_num=[0,1,10,30,50,70,100,1000,10000,100000]
get_compare_plot(train,feature_plot="RevolvingUtilizationOfUnsecuredLines",cut_num=cut_num,is_qcut=False)
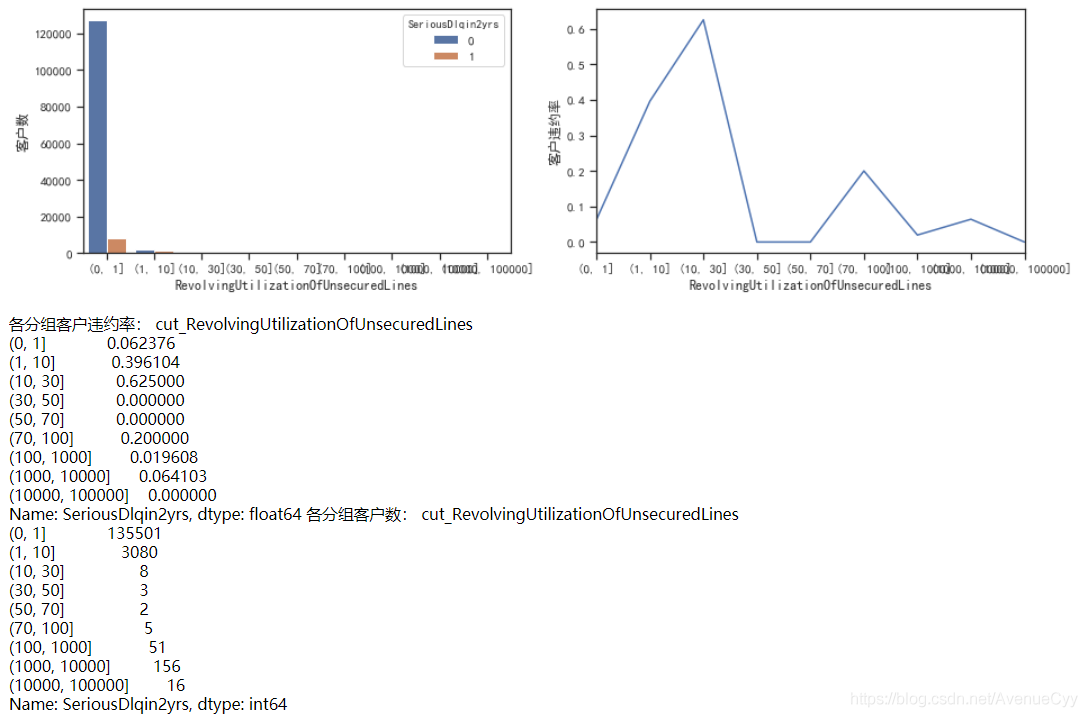
- 这里主要分析Revol大于10是什么情况。通过图像和数据可以发现,当比例大于10后,客户违约率在10~30达到高峰,然后下降,再往后的比例都差不多,上下浮动。
- 出现这个情况,此时要做的就是找到阈值,能分割正常值和异常值的阈值。我们可以认定10~30是一个分界点,因为它的违约率非常高,但是要注意,10-30这个区间内,客户数只有8人,随机性太大,因此不做考虑。发现1-10这个区间内的样本数足够,并且违约率也在上升,因此进一步分析。
cut_num=[]
for i in np.arange(-1,11,1):
cut_num.append(i)
get_compare_plot(train,feature_plot="RevolvingUtilizationOfUnsecuredLines",cut_num=cut_num,is_qcut=False)
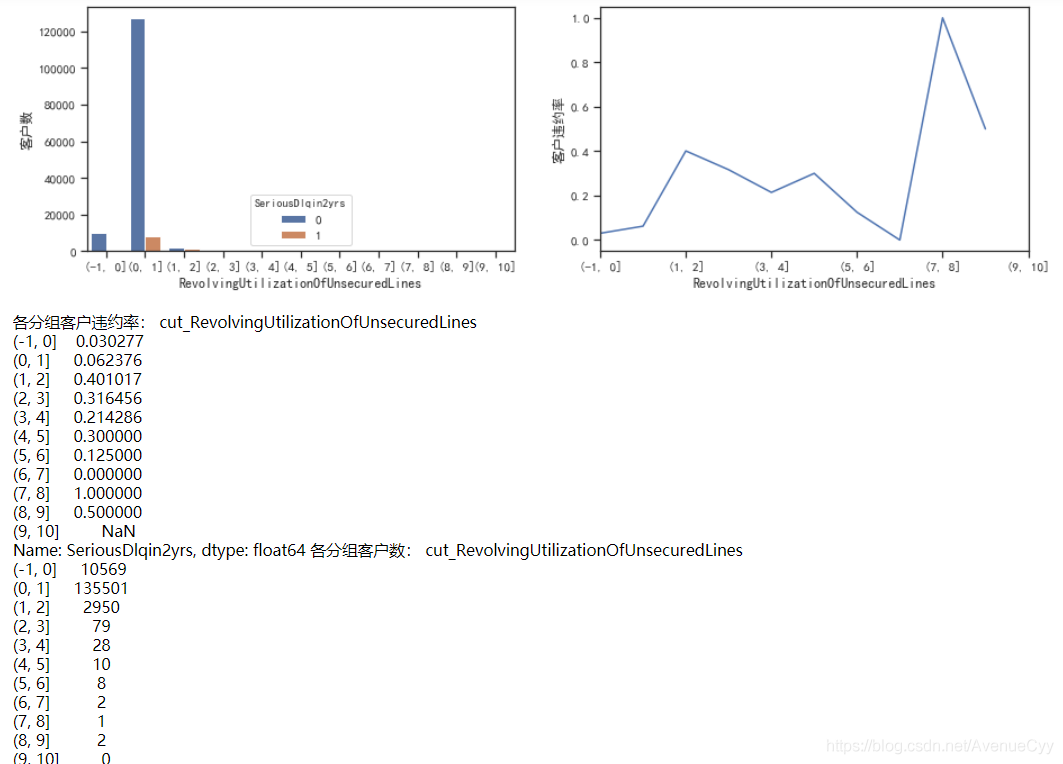
- 对1-10分析后,可以看到,在数据量足够的情况下(大于30),即1-4,违约率是在逐渐下降的,这不符合正常的规律性,应该是Revol越大,违约率越大。
- 我们发现在1-2时,违约率有了特别大的提升,从0.06到0.4。因此,可以认为阈值在这个区间内。