一、创作缘由
数据集呈现的方式有很多种,今天和大家仔细谈一谈当我们要读取的数据集信息存储在文本文件时,我们如何读取数据集?
最近在实现一个垃圾分类的任务,数据集中每张图片的名称和数据标签都记录在了文本文件中。
垃圾分类数据集介绍:一共有6种不同类型的垃圾:纸箱、玻璃、金属、纸张、塑料和其他垃圾
每一类垃圾的图片均存储在各自对应的文件夹下面,如图

图1
图2
数据图片的名称和其对应的标签存储在文本文件中:
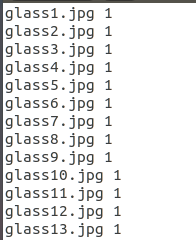
图3
对于这种类型的数据集,PyTorch中没有提供现成的读取方法,需要我们自己定义一个Dataset的派生类
二、数据读取详细步骤记录
(一)、PyTorch中的Dataset类介绍:
1. 原理介绍:
torch.utils.data.Dataset是PyTorch用来表示数据集的抽象类。我们用这个类来处理自己的数据集的时候必须继承Dataset,然后重写下面的函数:
(1) __init__:完成文本文件的读取工作
(2) __len__:使得len(dataset)返回数据集的大小;
(3) __getitem__:使得dataset[i]能够返回第i个数据样本,完成图片的读取工作。(这样做是为了减小内存开销,只需在用到的时候读入图片)
2. 数据集读取代码实现
2.1 导入模块
import os
import torch
import torch.utils.data as data
import cv2 as cv
from torch.utils.data import Subset
2.2 定义函数——获取数据路径和标签值
def get_train_path(list_path, file_path):
# list_path:文本文件所在的绝对路径; file_path:图片数据文件夹的绝对路径
image=[] # 用来存储每一张图片绝对路径的列表
label=[] # 存储每一张图片标签的列表
with open(list_path, "r") as lines:
# 打开txt文件,将文本文件的每一行作为列表中的一个元素存储在一个名为lines的列表中
for line in lines: # 逐行遍历列表lines
line = line.strip('\n') # 文本文件每一行的末尾都有一个换行符,需要删除
line = line.rstrip() # 为了读取到准确的图片名和标签值,去除字符串末尾的空白
# img_pth=os.path.join(file_path, line[:-2]) # 每一张的图片路径 = 图片文件夹路径 + 图片名
img_pth = os.path.join(file_path, line[0:5], line[:-2])
# 每一张的图片路径 = 所有图片总文件夹路径 + 各类文件夹名称 + 图片名
image.append(img_pth)
label.append(line[-1])
return image,label
几点说明:
(1) 对上述代码中的line[:-2]和line[-1]处理作进一步的解释,我们取图3中的第1行为例:
剔除了末尾换行符和末尾空白的字符串 line = 'glass1.jpg 1',最后一个字符'1'是其类别标签,图片名和标签值之间有1个空格,一共有6类数据,所以标签值只占1个字符;去掉字符串 line = 'glass1.jpg 1' 的后两个字符就可以得到图片名称 'glass1.jpg',所以就有了 line[:-2] 的操作;而只取字符串的最后一个字符即是图片标签,所以就有了 line[-1] 的操作。
(2) img_pth = os.path.join(file_path, line[0:5], line[:-2])
分类任务的数据集存储格式如下:
data(file_path)
--class1
--class2
--class3
如果我们将所有子类的名称都简化为5个字符表示:

图4
每一张图片的绝对路径就可表示为:file_path + classn(子类文件夹名) + 图片名
2.3 定义Dataset的派生类
class my_dataset(data.Dataset):
# 自定义的参数
def __init__(self, image, label, transforms=None, debug=False, test=False):
# 已有参数命名,方便在其他模块中用这些参数
self.paths = image
self.labels = label
self.transforms = transforms # 数据增强
self.debug = debug # 可有可无
self.test = test # 可有可无
# 返回图片个数
def __len__(self):
return len(self.paths)
# 获取每个图片
def __getitem__(self, item):
# path
img_path = self.paths[item]
# read image
img = cv.imread(img_path) # BGR格式
# 将BGR格式的图像转为RGB格式图像
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# augmentation 图像增强
if self.transforms is not None:
img = self.transforms(img)
# read label
label = self.labels[item]
# return
return torch.from_numpy(img).float(), int(label)
2.4 实例化派生类——读取图片
file_path = '/home/lab134/yyf/PyTorch_learn/Pytorch/trash_dataset/Garbage_classification_2/'
list_path = '/home/lab134/yyf/PyTorch_learn/Pytorch/trash_dataset/zero-indexed-files.txt'
img, lbl = get_train_path(list_path, file_path)
data_set = my_dataset(image=img, label=lbl) # data_set是my_dataset的一个实例化
2.5 训练集、测试集、验证集的划分
我们按照8:1:1的比例划分训练集、验证集和测试集, 有两种方法划分数据集。
2.5.1 划分数据集的第一种方法——手动划分
我们自己指定数据集的划分区间——需要导入Subset类
from torch.utils.data import Subset
数据集共有2527张图片,指定0~2020张图片作为训练集、2021~2273张图片为验证集、2274~2526张图片为测试集。
代码如下:
train_dataset = Subset(data_set,range(0,2021))
val_dataset = Subset(data_set,range(2021,2274))
test_dataset = Subset(data_set,range(2274,2527))
2.5.2 划分数据集的第二种方法——用data.random_split方法来随机划分数据集
首先计算出训练集、验证集和测试集的大小:
train_size = int(0.8*len(data_set))
print(str(train_size))
test_size = val_size = (len(data_set)-train_size)//2 # '//'式的除号表示商取整
print(str(val_size))
随机切分数据集
# 随机切分数据集
train_dataset,val_dataset,test_dataset = data.random_split(data_set,[train_size,val_size,test_size])
train_dataset = data.DataLoader(train_dataset, 1, shuffle=True, num_workers=0)
2.6 遍历训练集
for i,(img, lbl, path) in enumerate(train_dataset):
print(img.shape)
print(path)
print(lbl)
print(img.type)
到此,我们自己的数据集就可以成功读取了,但是为了能够训练,数据集需要接收一个可以选择的参数transform,用来将图片转换为张量格式。
三、数据增强
常用的图像增强变换
Rescale:重新调整图像大小;
RandomCrop:随机从图像中截取一部分;
ToTensor:将numpy类型表示的图像转换为torch表示的图像
我们用类而不是函数来实现以上三个功能,主要是考虑到如果用函数的话,每次都需要传入参数,但是用类就可以省掉很多麻烦。我们只需要实现每个类的__call__和__init__函数。
class Rescale(object):
"""将样本中的图像重新缩放到给定大小。
Args:
output_size (tuple or int): Desired output size. If tuple, output is
matched to output_size. If int, smaller of image edges is matched
to output_size keeping aspect ratio the same.
"""
def __init__(self, output_size):
# output_size——输出图像大小
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, labels = sample['image'], sample['labels']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# h and w are swapped for landmarks because for images,
# x and y axes are axis 1 and 0 respectively
labels = labels * [new_w / w, new_h / h]
return {'image': img, 'labels': labels}
class RandomCrop(object):
"""Crop randomly the image in a sample.
Args:
output_size (tuple or int): Desired output size. If int, square crop
is made.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, labels = sample['image'], sample['labels']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
labels = labels - [left, top]
return {'image': image, 'labels': labels}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
image, labels = sample['image'], sample['labels']
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'labels': torch.from_numpy(labels)}
今天先更新到这儿,如果大家发现文章中有什么不严谨的地方,欢迎在评论区指正!