目录
Hadoop三种运行模式
本地运行模式
伪分布式运行模式
完全分布式运行模式(开发重点)
Hadoop三种运行模式
Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop 官方网站:http://hadoop.apache.org/
本地运行模式
1.
官方
Grep
案例
①创建在 hadoop-2.7.6 文件下面创建一个 input 文件夹:
[root@master hadoop-2.7.6]# mkdir input
②将 Hadoop 的 xml 配置文件复制到 input
[root@master hadoop-2.7.6]# cp etc/hadoop/*.xml input
③执行 share 目录下的 MapReduce 程序
[root@master hadoop-2.7.6]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input output 'dfs[a-z.]+'
④查看输出结果:
[root@master hadoop-2.7.6]# cat output/*
伪分布式运行模式
1.启动 HDFS 并运行 MapReduce 程序
(1)分析
①配置集群
②启动、测试集群增、删、查
③执行 WordCount 案例
(2)执行步骤
①配置集群
(a)配置:hadoop-env.sh
主节点中,获取 jdk 的路径:
[root@master hadoop-2.7.6]# echo $JAVA_HOME
编辑 hadoop-env.sh,并添加 jdk 路径:
[root@master hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

(b)配置:core-site.xml
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定 Hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
(c)配置:hdfs-site.xml
<!-- 指定 HDFS 副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
②启动集群
(a)格式化 NameNode(第一次启动时格式化,以后就不要总格式化)
[root@master hadoop-2.7.6]# hadoop namenode -format

(b)启动 NameNode
[root@master hadoop-2.7.6]# hadoop-daemon.sh start namenode

(c)启动 DataNode
[root@master hadoop-2.7.6]# hadoop-daemon.sh start datanode
③查看集群
(a)查看是否启动成功
[root@master hadoop-2.7.6]# jps
7461 NameNode
7559 DataNode
7641 Jps
(b)web 端查看 HDFS 文件系统
http://master:50070

(c)查看产生的 Log 日志
说明:在企业中遇到 Bug 时,经常根据日志提示信息去分析问题、解决 Bug。
[root@master hadoop-2.7.6]# cd logs/
[root@master logs]# ll

(d)思考:为什么不能一直格式化 NameNode,格式化 NameNode,要注意什
么?
[root@master hadoop-2.7.6]# cd tmp/dfs/name/current
[root@master current]# cat VERSION
#Mon Jul 11 10:27:14 CST 2022
namespaceID=1179648118
clusterID=CID-92721281-f46b-419c-bab2-e23edc300e06
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1720451217-192.168.18.133-1657506434948
layoutVersion=-63
[root@master data]# cd current/
[root@master current]# ll
总用量 4
drwx------. 4 root root 54 7 月 11 10:30 BP-1720451217-192.168.18.133-1657506434948
-rw-r--r--. 1 root root 229 7 月 11 10:30 VERSION
[root@master current]# cat VERSION
#Mon Jul 11 10:30:12 CST 2022
storageID=DS-7efd22c8-fc53-4e03-beae-6699e4398181
clusterID=CID-92721281-f46b-419c-bab2-e23edc300e06
cTime=0
datanodeUuid=5774abb7-ab49-4740-8747-a6923bd17d8e
storageType=DATA_NODE
layoutVersion=-56
注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode的集群 id 不一致,集群找不到已往数据。所以,格式 NameNode 时,一定要先删除 data 数据和 log 日志,然后再格式化 NameNode。
④操作集群
(a)在 HDFS 文件系统上创建一个 input 文件夹
[root@master hadoop-2.7.6]# hadoop dfs -mkdir /input
(b)将测试文件内容上传到文件系统上
[root@master hadoop-2.7.6]# hadoop dfs -put wordcountinput/wc.input /input
(c)查看上传的文件是否正确
[root@master hadoop-2.7.6]# hadoop dfs -ls /input
[root@master hadoop-2.7.6]# hadoop dfs -cat /input/wc.input
(d)运行 MapReduce 程序
[root@master hadoop-2.7.6]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
(e)查看输出结果
命令行查看:
[root@master hadoop-2.7.6]# hadoop dfs -cat /output/*
2. 启动 YARN 并运行 MapReduce 程序
(1)分析
①配置集群在 YARN 上运行 MR
②启动、测试集群增、删、查
③在 YARN 上执行 WordCount 案例
(2)执行步骤
①配置集群
(a)配置 yarn-env.sh
配置一下 JAVA_HOME
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
(b)配置 yarn-site.xml
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- Reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(c)配置:mapred-env.sh
配置一下 JAVA_HOME
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
(d)配置: (对 mapred-site.xml.template 重新命名为) mapred-site.xml
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vim mapred-site.xml
<!-- 指定 MR 运行在 YARN 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
②启动集群
(a)启动前必须保证 NameNode 和 DataNode 已经启动
(b)启动 ResourceManager
[root@master hadoop]# yarn-daemon.sh start resourcemanager
(c)启动
NodeManager
[root@master hadoop]# yarn-daemons.sh start nodemanager
③集群操作
(a)YARN 的浏览器页面查看:http://master:8088/cluster
(b)执行 MapReduce 程序:
[root@master hadoop-2.7.6]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
(c)查看运行结果:
[root@master hadoop-2.7.6]# hadoop dfs -cat /output/*

3.配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如
下:
1. 配置 mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
2. 启动历史服务器
[root@master hadoop-2.7.6]# mr-jobhistory-daemon.sh start historyserver
3. 查看历史服务器是否启动
[root@master hadoop-2.7.6]# jps
10016 Jps
9234 NodeManager
7461 NameNode
7559 DataNode
9948 JobHistoryServer
8941 ResourceManager
4. 查看 JobHistory
http://master:19888/jobhistory
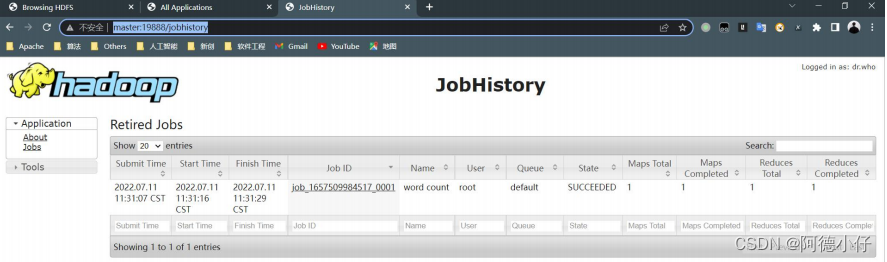
4.
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager和 HistoryManager。
开启日志聚集功能具体步骤如下:
1. 配置 yarn-site.xml
[root@master hadoop]# vim yarn-site.xml
在该文件里面增加如下配置。
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2. 关闭 NodeManager 、ResourceManager 和 HistoryManager
[root@master hadoop]# yarn-daemon.sh stop resourcemanager
[root@master hadoop]# yarn-daemons.sh stop nodemanager
[root@master hadoop]# mr-jobhistory-daemon.sh stop historyserver
3. 启动 NodeManager 、ResourceManager 和 HistoryManager
[root@master hadoop]# yarn-daemon.sh start resourcemanager
[root@master hadoop]# yarn-daemon.sh start nodemanager
[root@master hadoop]# mr-jobhistory-daemon.sh start historyserver
4. 删除 HDFS 上已经存在的输出文件
[root@master hadoop]# hadoop dfs -rm -r /output
5. 执行 WordCount 程序
[root@master hadoop-2.7.6]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
6. 查看日志
http://master:19888/jobhistory


5.
配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修
改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件

(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个
配置文件存放在$HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求
重新进行修改配置。
完全分布式运行模式(开发重点)
1.
准备工作
(1)设备
三台虚拟机:master、node1、node2
(2)时间同步
date
(3)修改主机名
三台主机名分别是:master、node1、node2
(4)关闭防火墙
systemctl stop firewalld
(5)查看防火墙状态
systemctl status firewalld
(6)取消防火墙自启
systemctl disable firewalld
(7)免密登录
三台都需要免密:
# 1、生成密钥
ssh-keygen -t rsa
# 2、配置免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3、测试免密登录
ssh node1
2.
搭建
Hadoop
集群
(1)上传安装包并解压
①使用 xftp 上传压缩包至 master 的/usr/local/packages/
②解压
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
(2)配置环境变量
vim /etc/profile
JAVA_HOME=/usr/local/soft/jdk1.8.0_171
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 重新加载环境变量
source /etc/profile
(3)修改 Hadoop 配置文件
①进入 hadoop 的配置文件
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
②core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
③hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

④hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
⑤mapred-site.xml.template
重命名文件:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
⑥slaves
⑦yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(4)分发 Hadoop 到 node1、node2
cd /usr/local/soft/
scp -r hadoop-2.7.6/ node1:`pwd`
scp -r hadoop-2.7.6/ node2:`pwd`
(5)格式化 namenode(第一次启动的时候需要执行)
hdfs namenode -format

(6)启动 Hadoop 集群
start-all.sh
(7)检查 master、node1、node2 上的进程
①master
②node1

③node2

(8)访问 HDFS 的 WEB 界面
http://master:50070

(9)访问 YARN 的 WEB 界面
http://master:8088/cluster

3.scp&rsync
的使用
(1) scp(secure copy)安全拷贝
①scp 定义:
scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
②基本语法
scp -r /usr/local/soft/data/ node1:`pwd`
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径 /名称
③案例实操
在 master 上,将 master 中/usr/local/soft/下的 data/目录拷贝到 node1
中的 soft 目录下:
[root@master soft]# scp -r data/ node1:`pwd`
(2)rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。
①基本语法
[root@master soft]# rsync -rvl data/ node2:`pwd`
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明:
选项

②案例实操
把 master 机器上的/usr/local/packages 目录同步到 node1 服务器的 root
用户下的/usr/local/packages 目录
[root@master local]# rsync -rvl packages/
node1:/usr/local/packages/