0X01 前言
即席查询怎么做、怎么选型!这次用的是presto来做尝试。
缘起
公司是Impala的深度用户,我主要负责Impala的各方面的工作,最近因为一些特殊原因需要对现有的体系进行一些调整,需要做出来即席查询的组件,在spark sql、impala、dril、impala之间做了一些调研后,暂时决定使用presto来做一些尝试。
原因有下面几个:
- 没有和cdh绑定那么深,用起来比较简单。
- 可以同时连mysql、hive等数据源,并且可以做join,这样就不用为了一些临时的需求导数据了。
- 需要为小组引入一些新的组件。
- 个人因素:好玩。
0X02 安装环境
presto需要的jdk版本是1.8。
0X03 安装记录
1.基本配置文件
etc/config.properties: presto的基本配置文件,分两种角色,coordinator和workers。两种角色的配置不同,其中coordinator有点类似master节点,workers类似于slave节点。
注意:discovery.uri需要配置成coordinator的host。
coordinator:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://host:8080
workers:
coordinator=false
http-server.http.port=8080
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery.uri=http://host:8080
etc/node.properties:
注意:
-
node.environment集群中的所有节点,该配置项要一致。
-
node.id每台机器的id都应该不一样。
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/presto/data
etc/jvm.config: JVM的配置项。
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
2.设置connector
presto可以设置不同的connector,用以连接不同的数据源。我配置了两种:hive和mysql。
需要新建一个目录etc/catalog,然后每种数据源一个配置文件。
hive:
文件名hive.properties。
注意:
- connector.name:我用的是cdh5,因此选择该连接器。
- hive.metastore.uri:hive元数据节点
- hive.config.resources:如果presto安装在集群外的节点,需要copy一下集群中的配置文件,并指定目录。
connector.name=hive-cdh5
hive.metastore.uri=thrift://host:9083
hive.config.resources=/data/presto/etc/cluster/core-site.xml,/data/presto/etc/cluster/hdfs-site.xml
mysql:
connector.name=mysql
connection-url=jdbc:mysql://host:3306
connection-user=zhanghao
connection-password=mima
3.设置启动脚本
需要下载一个jar包,然后重命名为presto,并赋予执行权限。以后可以用它来连接即可。
presto-cli-0.151-executable.jar
4.启动
直接启动使用bin/presto即可。
也可以设置连接的catalog和schema。比如:./presto --server localhost:8080 --catalog hive --schema default
5.安装airpal
airpal的安装不难,按照官网的安装即可。
官网地址
0X04 使用
1.基本查询测试
查看hive中的库。
presto> show schemas from hive;
Schema
-------------------------
test1
test2
...
test20
(20 rows)
Query 20160805_115300_00021_nk48v, FINISHED, 2 nodes
Splits: 2 total, 2 done (100.00%)
0:00 [20 rows, 238B] [99 rows/s, 1.15KB/s]
查看表信息。
presto> desc hive.trace.apptalk;
Column | Type | Comment
------------+---------+---------------
content | varchar |
id | varchar |
... | ... |
k | varchar | Partition Key
(13 rows)
Query 20160805_115429_00022_nk48v, FINISHED, 2 nodes
Splits: 2 total, 2 done (100.00%)
0:00 [13 rows, 798B] [32 rows/s, 1.96KB/s]
查看mysql表中的数据。
presto> select * from mysql.test.test limit 10;
id | name | *** | *** | *** | *** | ***
----+------------------+-------------------------------------+----------------------------------+-------------------------+--------+-------------------------
(10 rows)
2.导出数据
presto可以指定导出数据的格式,但是不能直接指定导出数据的文件地址,需要用Linux的命令支持。
下面是一个带有header的csv数据导出。
bin/presto --execute "sql statement" --output-format CSV_HEADER > test1.csv
3.跨源join
查询mysql和hive的数据,并做join。
这里不再写出sql了。
注意:
- 需要指定catalog。
- 不同库之间做join的时候需要主要字段类型,比如userid,在hive中可能是String,在mysql可能是int,这时候需要使用cast转一下格式,然后再做等于的比较。
4.管理界面
默认的管理界面的端口是8080。看着很炫酷。
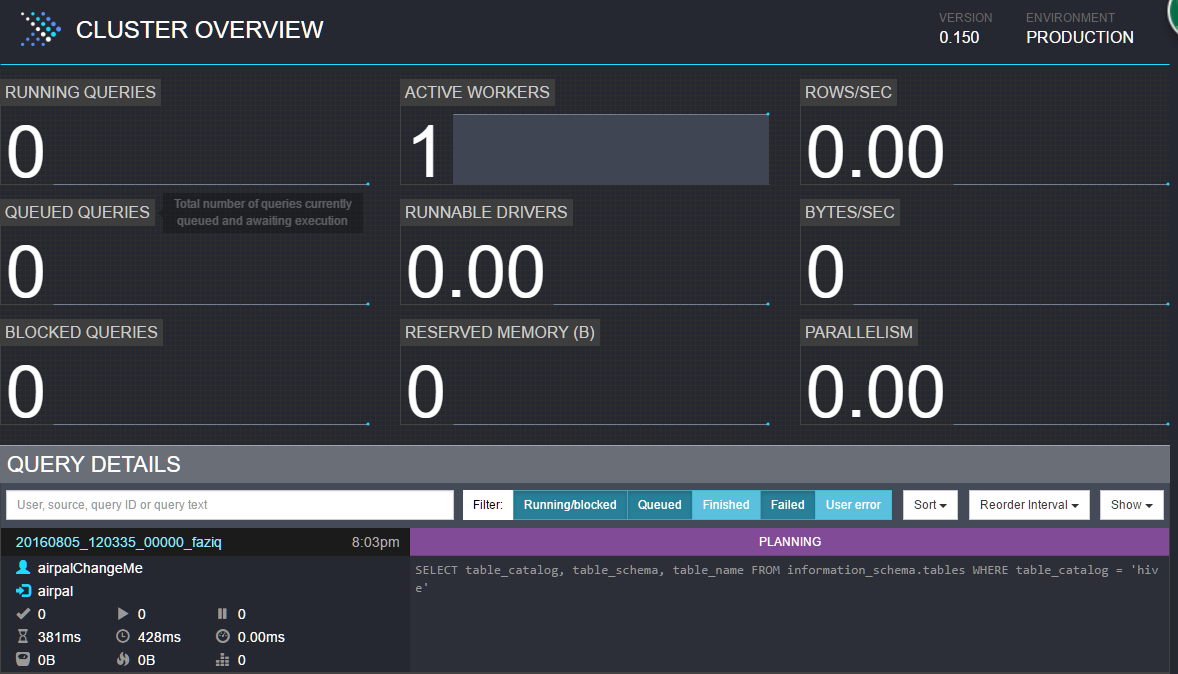
5.airpal
在airpal上提交query倒是也挺方便,但是有不少bug,目测更新的比较慢,跟不上presto的更新速度。用过就知道了…..
来源:
http://blog.csdn.net/zhaodedong/article/details/52132318
2016-08-05 20:17:00 hzct