介绍
label assignment 主要指的是检测器在训练阶段区分正负样本,并给feature map 不同位置匹配合适的监督目标,用于计算损失,进而完成梯度更新,合适的分配策略对于模型来说至关重要,在一定程度上决定了模型的性能。
分类
目前标签分配根据非负即正划分为硬标签分配(hard LA) 和软标签分配(soft LA),其中硬标签分类依据在训练阶段是否动态调整阈值,又可以细分为静态和动态两种。静态分类策略主要依据于模型的先验知识,例如距离阈值和iou阈值等,来选取不同的正负样本,例如二阶段目标检测分配策略和Fcos等,软标签分配策略主要依据在训练阶段采用不同的动态分配策略,如ATSS、SimOTA和PAA等。但是在本质上,不管是动态还是静态分配策略,预测框只有两个结果非负即正,且动态分配策略也是伪动态,如ATSS利用训练阶段的统计量来划分正负样本,但在模型配置和数据量固定时,模型在训练阶段的统计量几乎不存在较大差异,因此并不会产生更好的变化和调整。
软标签分配策略会根据预测结果与gt计算软标签和正负权重,在候选正样本(中心点落在gt框内)的基础上依据正负样本权重分配正负样本并计算相应的损失。且在训练的过程中动态调整软标签和分配权重,例如autoassign、TOOD和DW等。这里面存在了一个训练的冷启动问题,在模型训练的早期,参数都是随机初始化的,若存在一个检错的框,但分类和回归的得分都很高,那么模型会朝着让它更优的方向前进,这就导致一个较好的location没机会翻盘,一些模型加入了中心先验知识去抑制该情况,比如autoassign、DW等。
方法讲解
ATSS
基于L2距离和iou阈值自适应的选择正负样本
- 针对每个gt,在不同尺度的特征图上计算预测框与gt的
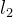 距离,选取其中最小的前k(默认为9)个作为候选正样本。
距离,选取其中最小的前k(默认为9)个作为候选正样本。
- 计算每个gt和候选正样本的iou值,并统计这些iou值的均值和方差
- 求和均值和方差,并将该值作为划分正负样本的阈值,大于该值的候选正样本为最终正样本,反之就是负样本。其中某个候选正样本,匹配到多个gt,则与得分最高的gt进行匹配
SimOTA
基于代价矩阵和iou,在训练的过程中动态的选择正负样本
- 将落在真实框内的特征点作为候选正样本
- 计算候选正样本与gt的分类交叉熵和回归损失,两值相加即为代价矩阵的元素值
- 计算gt和候选正样本的iou值,并对计算出的iou值进行排序,选取前k个值(默认为16)进行相加,该值作为最终划分正样本的个数值
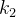 。针对每个gt,选择代价矩阵最小的个候选正样本作为最终的正样本,其余的为负样本。分配到多个gt的预测框取选取最小代价的进行匹配
。针对每个gt,选择代价矩阵最小的个候选正样本作为最终的正样本,其余的为负样本。分配到多个gt的预测框取选取最小代价的进行匹配
AutoAssign
基于预测框的分类得分、框回归得分、中心先验得分计算正负权重,实现对gt框内物体的形状自适应,以及不同FPN层物体正负样本的自动划分
- 所有FPN的特征点落在gt框内的作为候选正样本,其余的作为负样本
- 针对负样本,其负样本属性权重为1,正样本属性权重为0,而针对候选正样本,其负样本属性权重可以理解为该location 预测出的框和所有gt 计算出来的最大iou值,其值越小,负样本属性权重就越高,其计算方式为分类得分乘以前背景得分,而正样本属性权重来自于分类得分,前后景得分和iou得分,以及综合考虑中心先验得分,加上中心先验得分主要为了解决冷启动问题
- loss = 所有样本的负权重+候选正样本的正权重
TOOD
针对分类回归任务解耦所带来的空间不一致问题,即要求正样本必须同时定位高置信度,而负样本必须低置信度低定位,综合考虑两者,设计出一种预测框的度量方式,基于此度量方式,对预测框进行正负样本的划分
- 所有FPN的候选点落在gt框内即为候选正样本,其余为负样本
- 针对每个gt,计算其与候选正样本的iou值,并将该iou值和置信度得分,经过如下方式,后续度量值

其中 和
和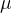 分别表示的是置信度得分和iou得分,
分别表示的是置信度得分和iou得分, 和
和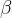 分类是超参数,用于调整两者的影响
分类是超参数,用于调整两者的影响
3. 根据t排序选择前k个候选正样本作为最终的正样本
4. 如果一个预测框和多个gt进行匹配,则选择iou最大的那个gt
5.计算正样本和度量t的celoss以及gt的GIoU损失
TODO
后续有时间更新Fcous、DW和GFL分配策略