强化学习算法主要在于学习最优的决策,到目前为止,我们所讨论的决策选择都是通过价值预估函数来间接选择的。本节讨论的是通过一个参数化决策模型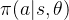 来直接根据状态
来直接根据状态 选择动作,而不是根据价值预估函数
选择动作,而不是根据价值预估函数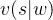 来间接选择。
来间接选择。
我们可以定义如下Policy Gradient更新策略,来求解参数化决策模型的参数,其中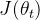 表示用于衡量决策模型优劣的损失函数。
表示用于衡量决策模型优劣的损失函数。

1. Policy Approximation and its Advantages
对于参数化决策模型存在两种建模方式:生成式或判别式。
当动作空间是离散且较小时,可以采用判别式模型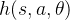 ,表示状态-动作对
,表示状态-动作对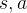 的优劣得分,此时可以表示为下式,这种通过softmax求得选择动作概率,兼顾了ε-greedy动作探索的功能。另一方面在很多情况下随机动作也是最优的,softmax方式具备这种特性。
的优劣得分,此时可以表示为下式,这种通过softmax求得选择动作概率,兼顾了ε-greedy动作探索的功能。另一方面在很多情况下随机动作也是最优的,softmax方式具备这种特性。
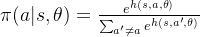
当动作空间是连续时,生成式模型是一个比较好选择,一种简单方式是将决策动作分布建模为一个高斯分布,由于动作分布方差的存在,因此也兼顾了动作探索的特性。
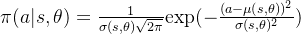
2. The Policy Gradient Theorem
接下来关键在于如何找到一个衡量决策模型优劣的损失函数。直观上理解,在最优决策下,各状态价值应该也是最优的,因此可以定义:
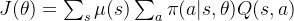
此时有
![\partial J(\theta)\\=\sum_s \mu(s) \sum_a Q(s,a) \partial_{\theta}\pi(a|s,\theta) \\=\sum_s \mu(s) \sum_a Q(s,a)\pi(a|s,\theta) \frac{\partial_{\theta}\pi(a|s,\theta)}{\pi(a|s,\theta) }\\=E[G(s,a)\frac{\partial_{\theta}\pi(a|s,\theta)}{\pi(a|s,\theta)}]](https://latex.csdn.net/eq?%5Cpartial%20J%28%5Ctheta%29%5C%5C%3D%5Csum_s%20%5Cmu%28s%29%20%5Csum_a%20Q%28s%2Ca%29%20%5Cpartial_%7B%5Ctheta%7D%5Cpi%28a%7Cs%2C%5Ctheta%29%20%5C%5C%3D%5Csum_s%20%5Cmu%28s%29%20%5Csum_a%20Q%28s%2Ca%29%5Cpi%28a%7Cs%2C%5Ctheta%29%20%5Cfrac%7B%5Cpartial_%7B%5Ctheta%7D%5Cpi%28a%7Cs%2C%5Ctheta%29%7D%7B%5Cpi%28a%7Cs%2C%5Ctheta%29%20%7D%5C%5C%3DE%5BG%28s%2Ca%29%5Cfrac%7B%5Cpartial_%7B%5Ctheta%7D%5Cpi%28a%7Cs%2C%5Ctheta%29%7D%7B%5Cpi%28a%7Cs%2C%5Ctheta%29%7D%5D)
可以定义如下SGD更新参数式子:

根据上式,同MC结合的Policy Gradient Methods:

3. Baseline
因为参数化决策模型中参数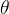 在不同下会同步更新,因此某些状态下其累积收益
在不同下会同步更新,因此某些状态下其累积收益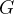 远大于其他状态,而决策模型是根据状态来选择动作,所以不同状态下其累积收益不同,会引入偏差,这个偏差会影响模型的影响。
远大于其他状态,而决策模型是根据状态来选择动作,所以不同状态下其累积收益不同,会引入偏差,这个偏差会影响模型的影响。
因此可以对累积收益减去状态带来的偏差,即
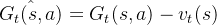
此时参数更新可以变为:

另外也可以看出虽然减去状态带来的偏差因子,原来同损失函数也是等价的。
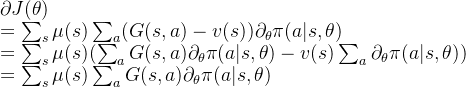

4. Actor–Critic Methods

