1.什么是搜索引擎?
全文搜索引擎: 自然语言处理(NLP)、爬虫、网页处理大数据处理如谷歌、百度、搜狗、必应等等
垂直搜索引擎: 有明确搜索目的的搜索行为各大电商网站、OA、站内搜索、视频网站等
2.搜索引擎应具备哪些要求?
- 查询结果快: 高效的压缩算法,快速的编码和解码速度
- 结果准确度: es7.0+ 使用BM25评分算法,es7.0-使用TF-IDF评分算法
- 检索结果丰富: 召回率
3. 面向海量数据,如何达到“搜索引擎”级别的查询效率?
- 索引: 帮助快速检索;以数据结构为载体;以文件的形式落地
4. MySQL innodb索引能解决大数据检索的问题吗?
- 索引可能会失效
- 检索的是
文本,索引字段可能很长,树深增加,io次数增多
- 精准度差

一. Lucene
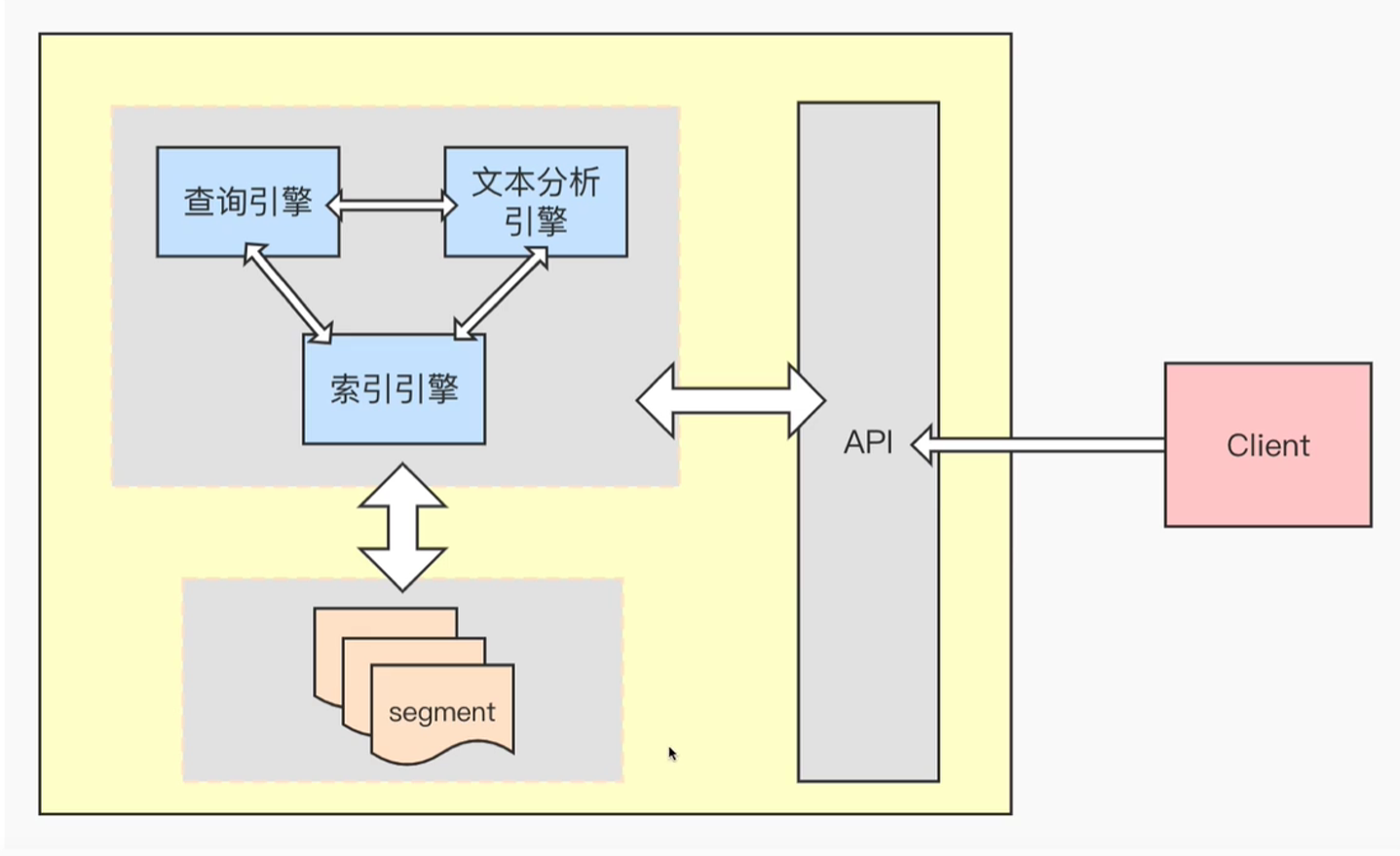
Lucene是一个成熟的全文检索库,由Java语言编写,具有高性能、可伸缩的特点,并且开源、 免费。 Lucene是一个IR库(Information Retrieval lib 后来才由Shay Banon在其基础上开发了Elasticsearch
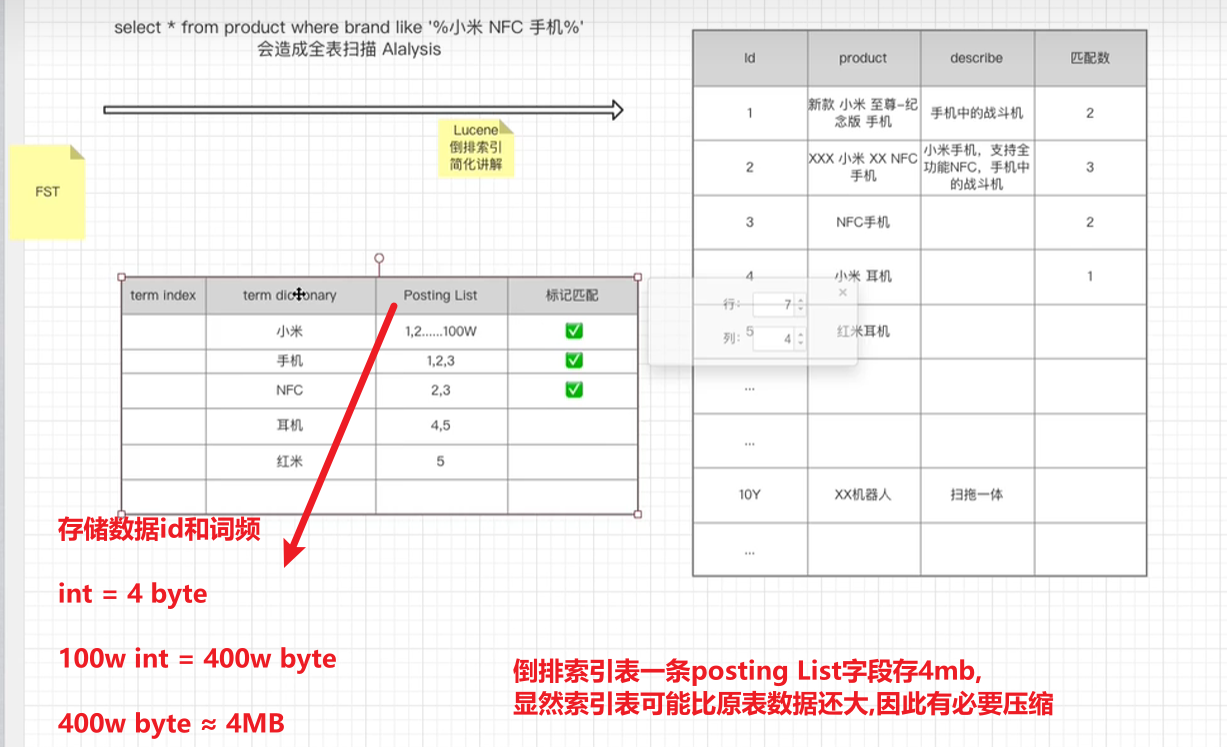
全文检索∶索引系统通过扫描文章中的每一个词,对其创建索引,指明在文章中出现的次数和位置,当用户查询时,索引系统过就会根据事先简历的索引进行查找,并将查找的结果反馈给用户的检索方式
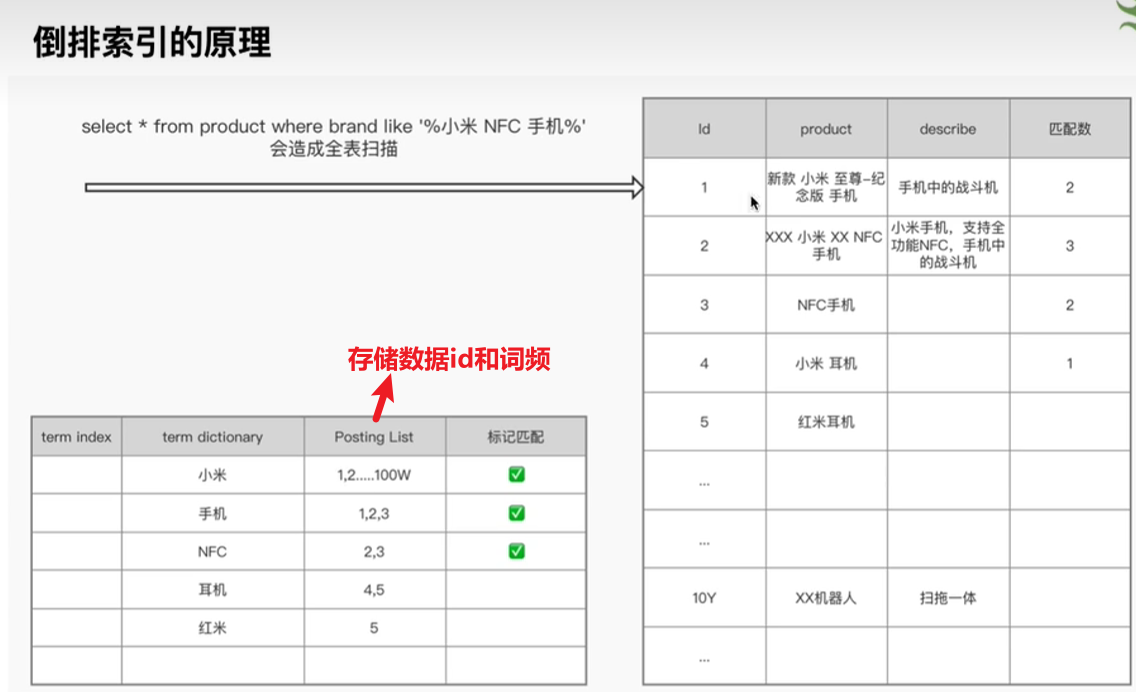
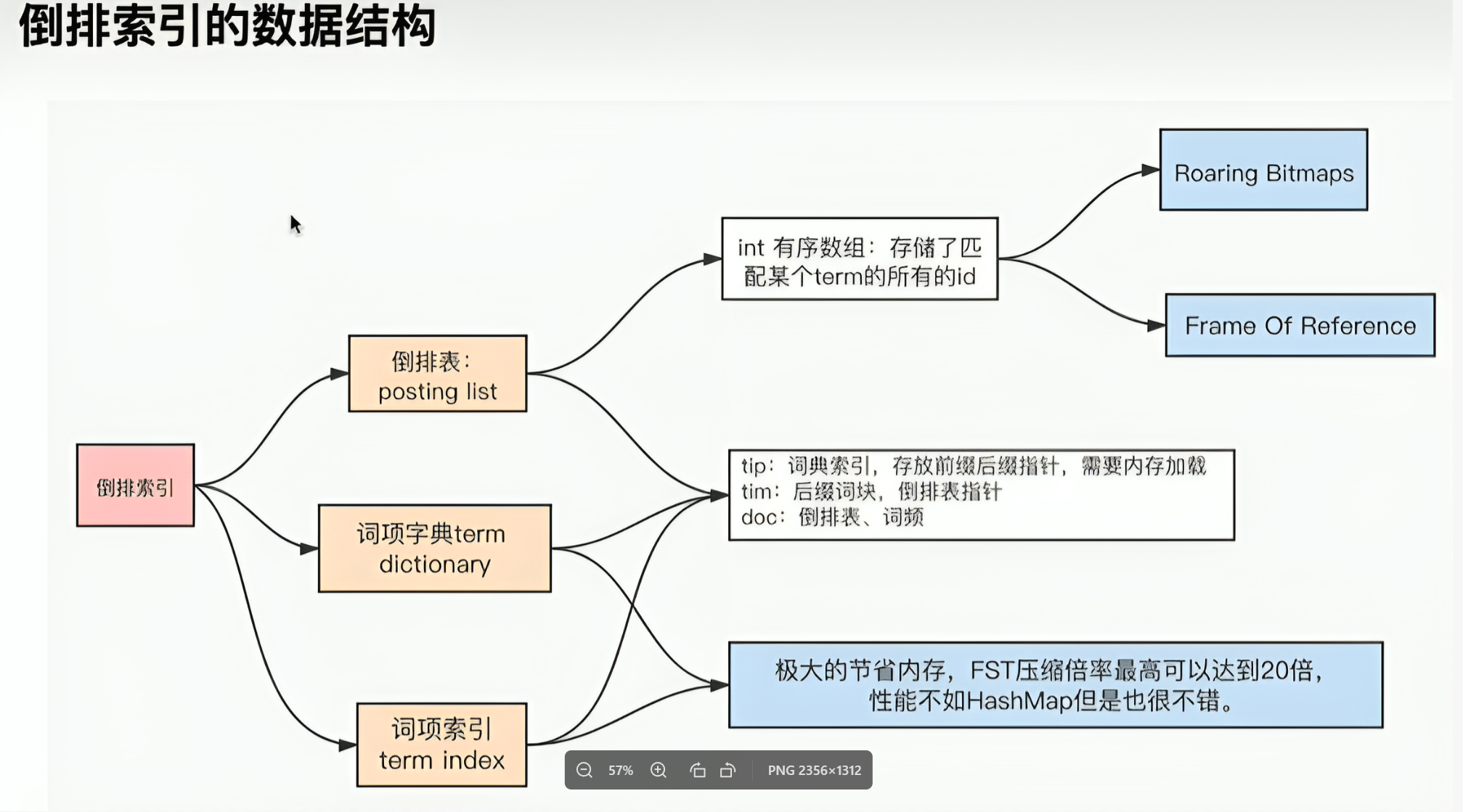
二.倒排索引算法
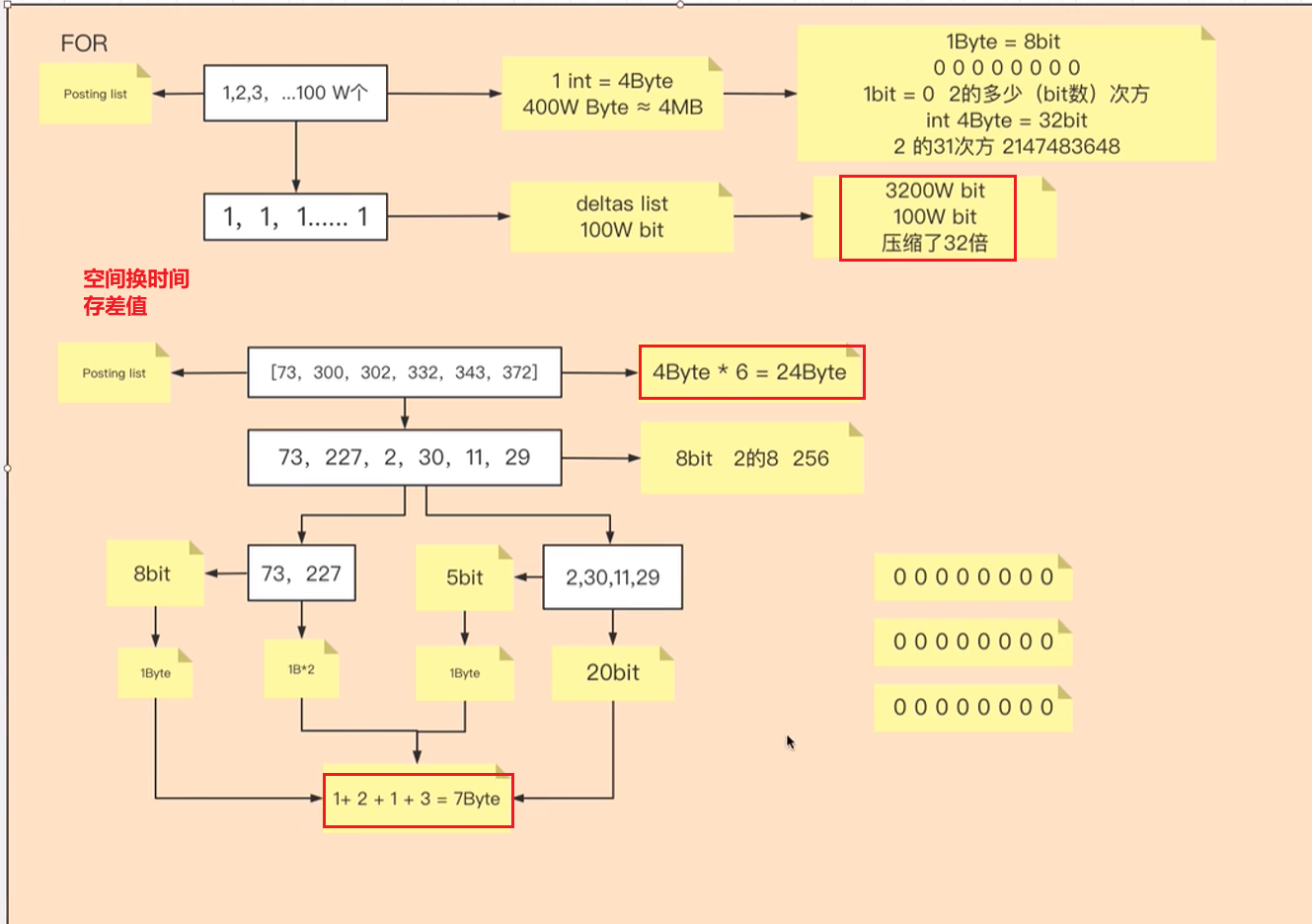
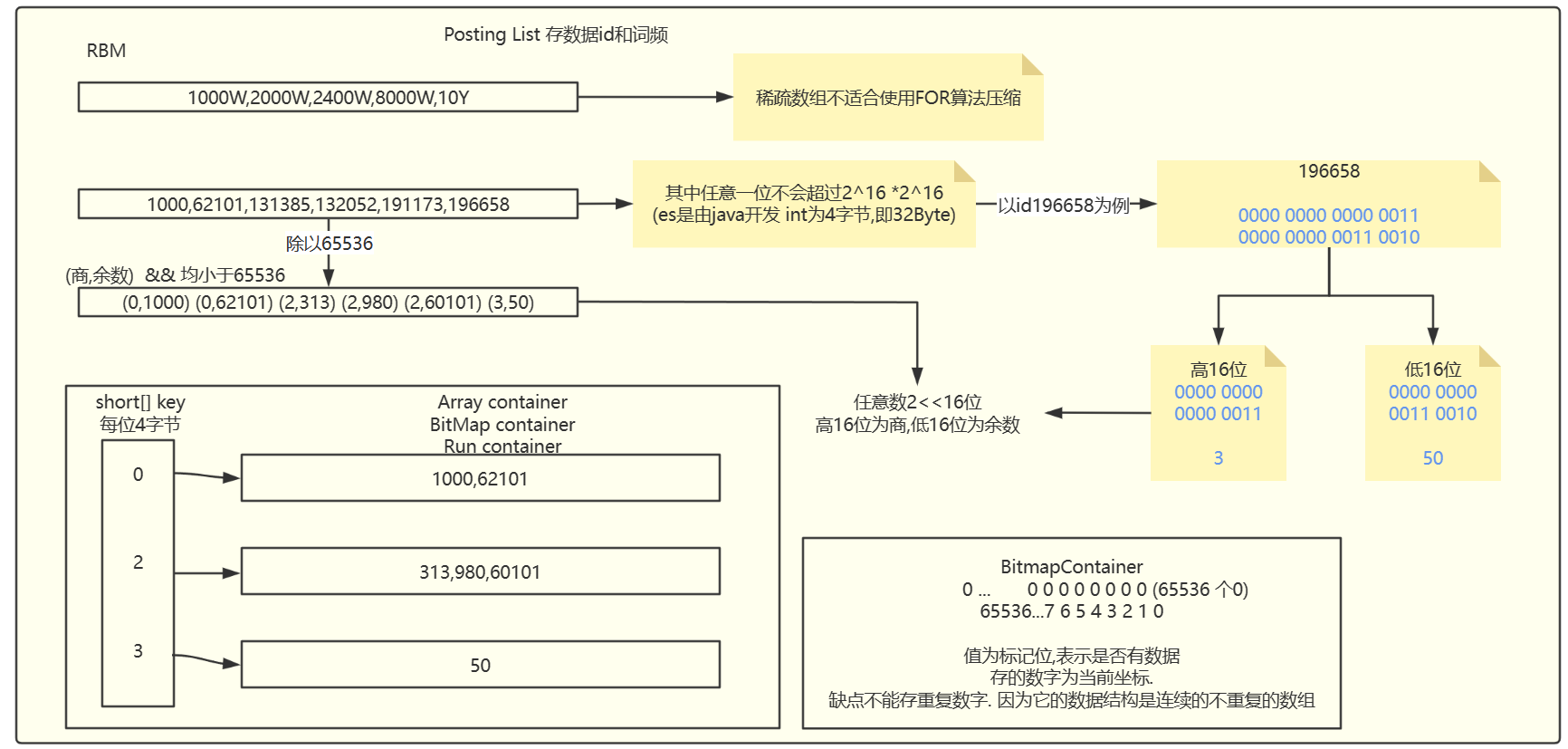
倒排表的压缩算法
FOR: Frame Of Reference
RBM:RoaringBitmap
词项索引的检索原理
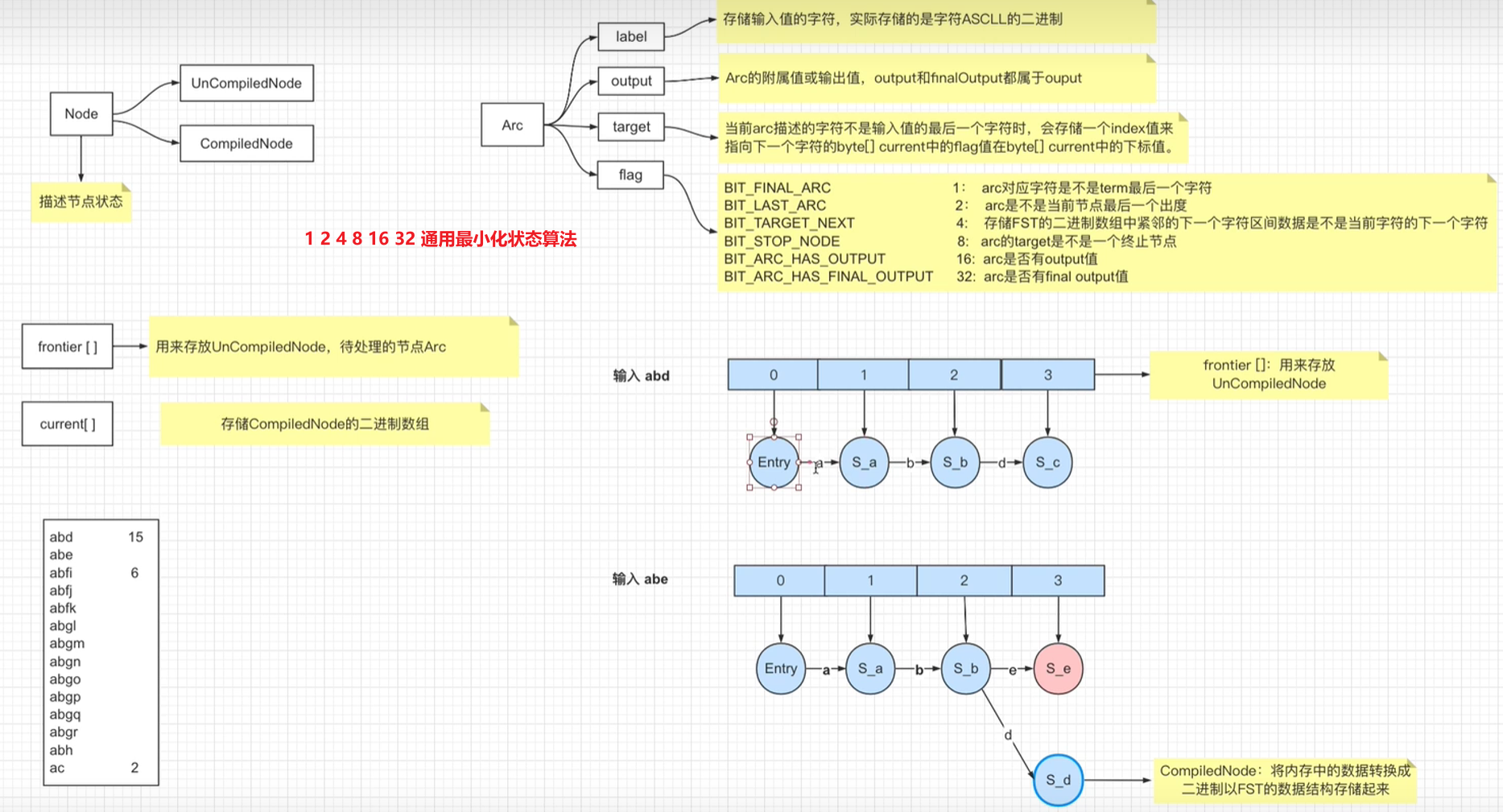
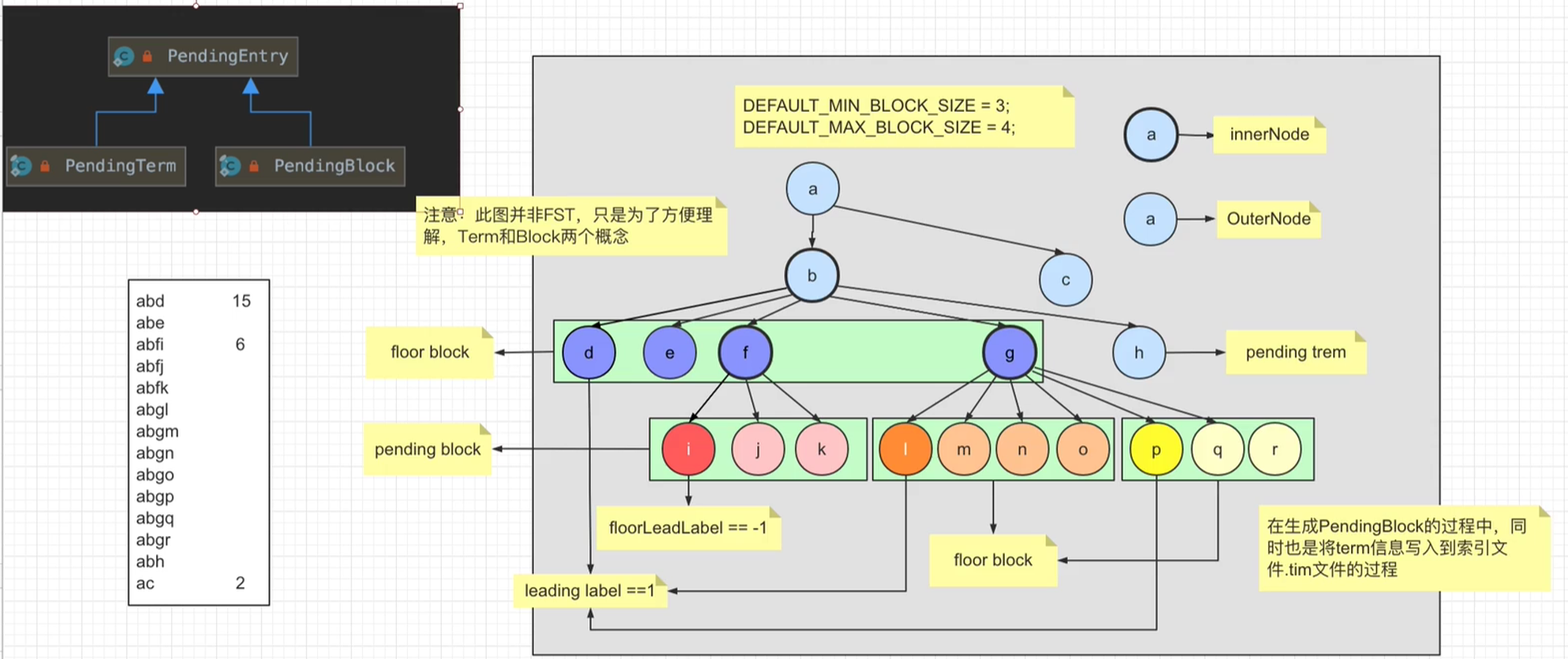
FST: Finit state Transducers
2.1 Posting List压缩算法
2.1.1 FOR
FOR: 针对稠密数组
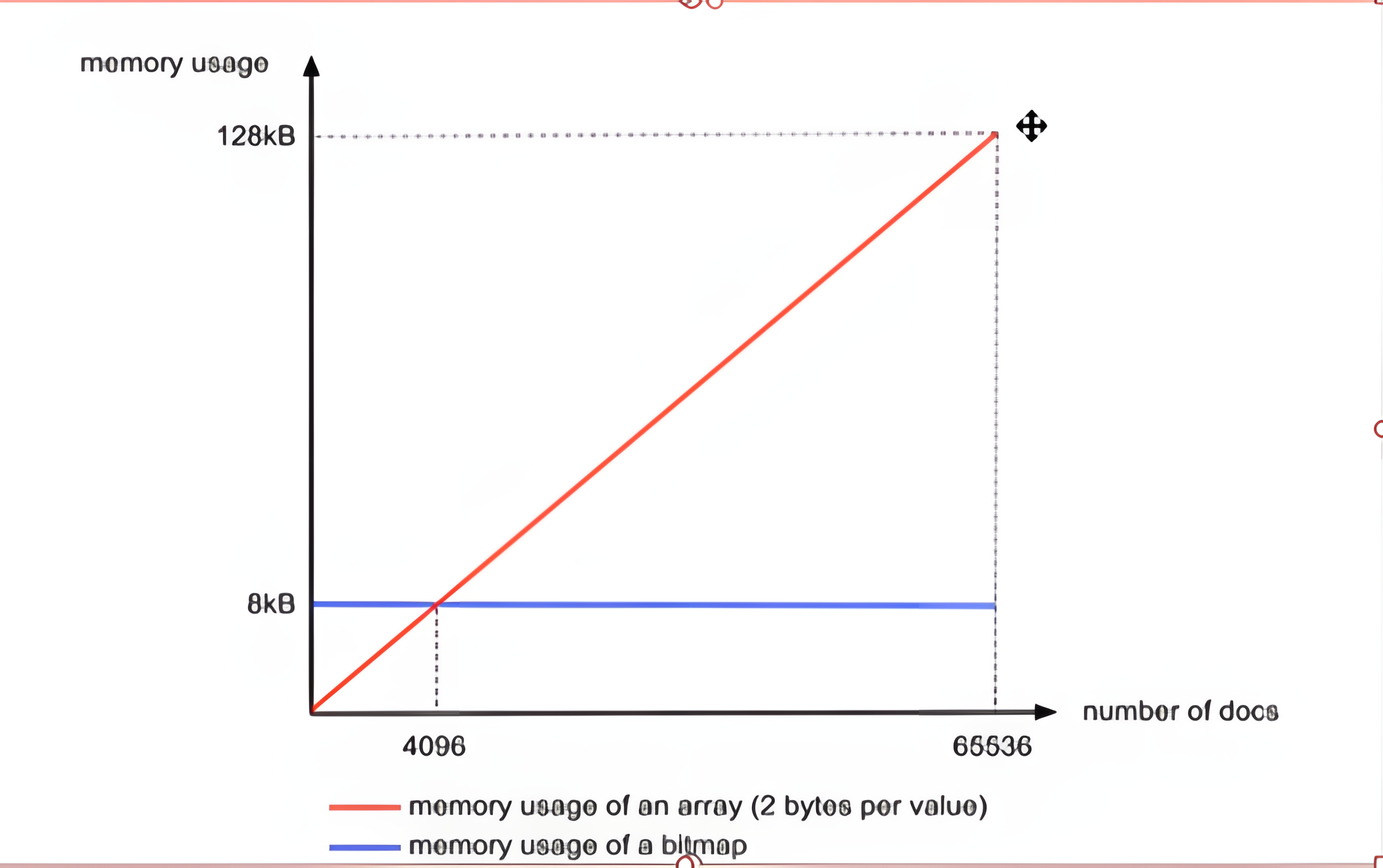
2.1.2 RoaringBitmap压缩
RBM: 针对稀疏数组
2.3 FST压缩算法
2.3.1 trie前缀树原理
什么是trie树?
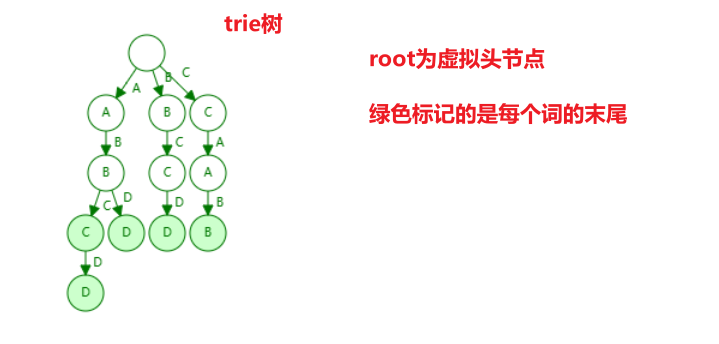
为什么要按照term字典序思想处理(但es的索引压缩不是trie)? 为了生成最小化的FST数据结构,复用相同字符节约空间
2.3.2 FST构建过程
NFA
NFA详情
Nondeteministic Finite Automaton,非确定自动状态机
A 是一个五元组 A = (Σ, S, s0, δ, F):
字母表 Σ (ϵ !∈ Σ)
有穷的状态集合 S
唯一的初始状态 s0 ∈ S
状态转移函数 δ
δ : S × (Σ ∪ {ϵ}) → 2S
接受状态集合 F ⊆ S
A 定义了一种语言 L(A): 它能接受的所有字符串构成的集合
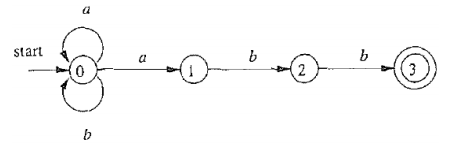
约定:所有没有对应出边的字符默认指向一个不存在的 “空状态” ∅
DFA
NFA详情
Deterministic Finite Automaton,确定性有穷自动机
A 是一个五元组 A = (Σ, S, s0, δ, F):
字母表 Σ (ϵ !∈ Σ)
有穷的状态集合 S
唯一的初始状态 s0 ∈ S
状态转移函数 δ
δ : S × Σ → S
接受状态集合 F ⊆ S
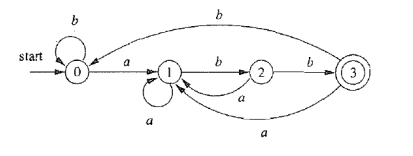
约定: 所有没有对应出边的字符默认指向一个不存在的 “死状态”
FSM
有限个状态
同一时间只能处于同一个状态不同状态可以互相转换
状态是无序的
FSA
确定性:在任何给定状态下,对于任何输入,最多只能遍历一个transition
非循环:不可能重复遍历同一个状态
Final唯一性:当且仅当有限状态机在输入序列的末尾处于“最终"状态时,才"“接受”"特定的输入序列

FST:有限状态转换机构建原理
FST最重要的功能是可以实现Key到Value的映射,相当于HashMap<Key,Value>。FST的查询速度比HashMap要慢一点,但FST的内存消耗要比HashMap少很多。FST在Lucene中被大量使用,例如:倒排索引的存储,同义词词典的存储,搜索关键字建议等


FST在lucene中实现原理