1,快速排序--找到基准点的位置
既不浪费空间又可以快一点的排序算法。
如:“6 1 2 7 9 3 4 5 10 8”这10个数进行排序。首先找到一个数作为基准点(一个参照数),为了方便,让第一个数6作为基准点。然后将这个序列中所有比基准数大的数放在6右边,比基准点小的数放在6的左边,类似这种:“3 1 2 5 4 6 9 7 10 8”.
(相当于每一次快速排序,就将基准点的位置确定了,然后,比基准点小的数在位置左边,比基准点大的数在位置右边,然后再选取新的基准点,再进行快速排序。)
解释:分别在初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。从右到左找小于6的数,从左到右找大于6的数,然后交换他们。
这里用i和j,分别指向序列最左边和最右边。即i=1,指向数字6,j=10,指向数字。
首先j开始行动。因为此处设置的基准数是最左边的数,所以需要j先动。
j向左移动(j--),直到找到一个小于6的数停下。
然后i向右移动(i++),直到找到一个大于6的数停下。
例子里,j是在数字5的位置,i是在数字7的位置上。
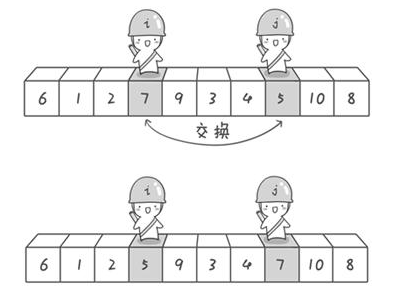
交换i和j位置上的数字,这样:“6 1 2 5 9 3 4 7 10 8”。
到此,第一次交换结束。
然后,继续让j向左移动,找比6小的数,即“4”。
让i向右移动,找到比6大的数,即“9”。
进行交换,这样:“6 1 2 5 4 3 9 7 10 8”。第二次交换结束。
继续这样移动,找值,j发现了3,停下。i向右移动,遇到了j。说明“探测”结束。
将基准数6和3交换,这个位置定为基准数的位置。“3 1 2 5 4 6 9 7 10 8”.

第一次的“探测”结束(可以理解为一次快速排序结束,基准点找到了位置)。
过程:j找到小于基准数的数,i找到大于基准数的数,直到i和j相遇。
接下来,要以基准点6,分为两个序列,左边“3 1 2 5 4”,右边“9 7 10 8”。
按照以上的方法,处理两个序列。
左边:“3 1 2 5 4”。以3为基准点,3的左边都小于等于3,3的右边都大于等于3.
结果“2 1 3 5 4”。i和j相遇,值交换,3以归位。
然后继续分为两个序列,“2 1”和“5 4”,在排序。
这样左边结束后,结果“1 2 3 4 5 6 9 7 10 8”。
右边:“9 7 10 8”。同理,得到“1 2 3 4 5 6 7 8 9 10”。

分析:快速排序比较快,以外每次交换都是跳跃式的。每次交换不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离大了,交换的次数也就少了。
当然在最坏的情况下,还是可能相邻的两个数进行交换,所以快速排序的zui最差时间复杂度和冒泡排序是一样的O(N2),平均时间复杂度O(NlogN)。
代码(c++):
#include <stdio.h>
int a[101],n; //全局变量
void quicksort(int left,int right) //位置,索引
{
int i,j,t,temp;
if(left>right) return;
temp=a[left]; //temp中存的是基准数
i=left;
j=right;
while(i!=j)
{
while(a[j]>=temp && i<j) //顺序很重要,从右边先开始,找小于基准点的数
j--;
while(a[i]<=temp && i<j) //找大于基准点的数
i++;
if(i<j) //交换位置
{
t=a[i];
a[i]=a[j];
a[j]=t;
}
}
//基准数归位
a[left]=a[i];
a[i]=temp;
quicksort(left,i-1); //处理左边的,递归
quicksort(i+1,right); //处理右边的,递归
}
抄录于:详细快速排序
代码(java):
public void quick_sort(int []a,int left,int right){
if(left>right) return;
int i=left;
int j=right;
int temp=a[left];
while(i!=j){
while(i<j && a[j]>=temp)
j--;
while(i<j && a[i]<=temp)
i++;
if(i<j){
int tt=a[i];
a[i]=a[j];
a[j]=tt;
}
}
int kk=a[i];
a[i]=temp;
a[left]=kk;
quick_sort(a,left,i-1);
quick_sort(a,j+1,right);
}
2,冒泡排序--相邻比较,找到最值
基本思想:从无序序列头部开始,进行两两比较,根据大小交换位置,直到最后将最大(小)的数据元素交换到无序队列的队尾,从而成为有序序列的一部分;然后继续这个过程。
通过两两比较交换位置,选出剩余无序序列中最大(小)的数据元素放到队尾。
时间复杂度:O(N2),也有说最优时间复杂度是O(n),这里不提。空间复杂度:O(1)。
过程:1,比较相邻的元素。如果第一个比第二个大(小),交换。
2,对每一对相邻元素做同样的工作,从开始到结尾,最后的元素是最大(小)的数。
3,针对所有的元素重复以上步骤,除了有序的元素。(已选出的元素)
4,持续对无序元素重复以上步骤,直到都有序。
例如:

以上为例(小到大):
第一次排序,3,6比较,不需要交换。6,4比较,交换得到4,6。
6,2比较,交换得2,6。 6,11比较,不交换。
11,10比较,交换得10,11。11,5比较,交换得5,11。
得到“3 4 2 6 10 5 11”。
之后的排序最后有序的序列不参与,元素两者之间的比较。得到最大值,放在无序序列的队尾。
代码(c++):
void bubble_sort(int arr[],int len){
int i,j;
for(i=0;i<len-1;i++){
for(j=0;j<len-1-i;j++){ //无序序列长度
if(arr[j]>arr[j+1])
swap(arr[j],arr[j+1]);
}
}
}
代码(java):
public static void bubble_sort(int[] arr){
int i,j,temp,len=arr.length;
for(i=0;i<len-1;i++){
for(j=0;j<len-1-i;j++){
if(arr[j]>arr[j+1]){
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}
3,二分查找算法--数组中以中间值二分查找数
二分查找算法是在有序数组中用到较为频繁的一种查找算法。对数组一直进行二分,然后查找到数。
对数组进行遍历,每个元素进行比较,其时间是O(n)。二分查找则是O(lgn)。
重点:二分查找的时间复杂度是O(logn)。最坏的情况下是O(n)。
二分查找的条件是待查询的数组是有序的,我们假设数组是升序。
二分查找主要思路:设定两个指针start和end分别指向数组的首尾两端,然后比较数组中间节点array[mid]和待查找元素。如果待查找元素小于中间元素,那么表明待查找元素在数组的前半段,那么将end=mid-1;如果待查找元素大于中间元素,那么表明待查找元素在数组的后半段,那么将start=mid+1;如果待查找元素等于中间元素,那么就是mid的值。
例如,{1,2,3,4,5,6,7,8,9}查找6:
1,中间元素mid=(start+end)/2,即5。5<6,所有,6在{6,7,8,9}中。
2,{6,7,8,9}中间元素,即8。8>6,元素在{6,7,8}中查找。
3,{6,7,8}中间元素,即7。7>6,左边数组只剩下6,找到了。
代码(java):
public class BinarySearch {
public static void main(String[] args) {
int [] array = {1,2,3,4,4,7,12};
int len = array.length;
}
/**
* 二分查找(递归)
* @param arry 递增数组
* @param value 待查找数值
* @param start 起始查找位置
* @param end 末查找位置
* @return
*/
private static int binarySearchRecursion(int arry[],int value,int start,int end)
{
if(start > end)
return -1;
int mid=start + (end-start)/2;
if(arry[mid] == value)
return mid;
else if(value < arry[mid])
{
end = mid - 1;
return binarySearchRecursion(arry,value,start,end);
}
else
{
start = mid + 1;
return binarySearchRecursion(arry,value,start,end);
}
}
/**
* 二分查找(非递归,循环)
* @param arry 递增数组
* @param value 待查找数值
* @param start 起始查找位置
* @param end 末查找位置
* @return
*/
private static int binarySearchRecursionNon(int arry[],int value,int start,int end)
{
while(start <= end){
int mid=start + (end-start)/2; //或者是 (start+end)/2
if(arry[mid] == value)
return mid;
else if(value < arry[mid])
{
end = mid - 1;
}
else
start = mid + 1;
}
return -1;
}
}
时间复杂度:外循环和内循环以及判断和交换元素的时间开销。最优情况是开始就排好序了,不用交换元素,最坏的是逆序。
空间复杂度:在交换元素时那个临时变量所占的内存空间。最优情况是开始就排好序了,不用交换元素,最坏的是逆序。
这些是自己的一些记录收集和理解。