- 全称:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension。BART来源于Bidirectional and Auto-Regressive Transformers
- 发表时间: 2019.10.29
- 团队:Facebook AI
- Paper地址
- 代码地址
目录
Abstract
1. Introduction
2. Model
2.1 Architecture(模型结构)
2.2 Pre-training BART(预训练)
3. Fine-tuning BART(微调)
3.1 Sequence Classification Tasks(分类任务)
3.2 Token Classification Tasks(Token级别的分类任务)
3.3 Sequence Generation Tasks(文本生成任务)
3.4 Machine Translation(机器翻译)
4. Comparing Pre-training Objectives
4.1 Comparison Objects
4.2 Tasks
4.3 Results
5. Large-scale Pre-training Experiments
BART是一种非常适用与生成式任务的模型,当然它也能完成判别式任务,而且效果也很好。它主要结合了BERT和GPT两种模型思路,使得它不仅具有双向编码的优势,也具有单向自回归编码的优势。本篇主要探讨一下BART的原始论文,如果仅仅想作为了解,看完本篇介绍就够了,但是我还是强烈建议读者读一读原始论文。论文中的每一部分,我这里仅做要点解读。
Abstract

- BART沿用了标准的Transformer结构,也就是Encoder-Decoder的Transformer。
- BART的预训练主要依据以下两步走的思路:
1)通过随机噪声函数(说白了就是能够制造破坏文档结构的任何方法)来破坏文章结构;
2)逼迫模型能够学会将结构已经被破坏了的文章进行重构,使文章变回原来的样子;
至于如何破坏文章结构呢?作者说了,他们通过评估不同方法后发现采用下列方法效果最好,一个是随机打乱原文句子的顺序,一个是随机将文中的连续小片段(连续几个字或词)用一个[MASK]代替,和Bert不同,Bert是一个词用一个[MASK]替换,BART是连续多个词用一个[MASK]替换。

论文中,作者还仿照其它的预训练模型的方式,对BART进行了消融实验,也就是说,把BERT、XLNet等预训练方法移植到BART中,以此更好的验证哪一些模型的哪一些因素对最终任务的性能影响最大。
1. Introduction

这个和摘要中介绍的差不多,总之就是告诉我们BART的训练分两步走:通过随机噪声破坏文章结构,再训练一个序列到序列的模型来重构被破坏的文本。

对于片段式MASK,片段的长度是随机选取的,但实际上也不是随机的,后文有提到,用了泊松分布的方法采样不同长度的片段(包括长度为0)。

这里提到了,BART不仅在生成任务上(NLG)特别有效,同时在自然语言理解任务上(NLU)表现的也很出色。
下面看一些论文提供的BART示意图:
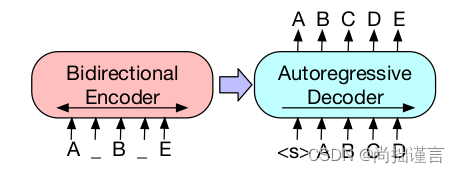

在BART中,它的输入输出并不需要严格的保持长度一致,即Encoder的输入与Decoder的输出不需要对齐。从上述结构图中可以看出,左边部分Encoder接收的结构破坏后的文章,它经过Encoder双向编码,类似于Bert,右边部分接收来自Encoder的输出后,经过自回归解码输出预测结果,类似于GPT(注意GPT是不需要Encoder的)。自回归解码依据的是最大似然概率,这一点和N-Gram词袋模型或者NNLM模型是相似的。作者在上图中还提到了,对于微调,BART的Encoder和Decoder接收同样的输入,且此时的输入文章是没有被破坏了的,这样一来,Decoder最后一维的输出被拿来作为文章的向量表示,类似于Bert,只不过bert用的是Encoder的final hidden state。其实这里作者介绍的笼统了,下文有提到,微调方式是需要依据不同的任务的,这个下文再说。
2. Model
这一节是重点。

开头作者就精辟的总结了:BART模型的实现本质上仍然是Sequence-to-Sequence范式,实质就是Encoder-Decoder架构,Encoder属于双向编码,对被破坏的文本进行编码;Decoder属于单向解码(left-to-right),也就是自回归解码,解码出我们想要的目标文本。优化目标是负的对数似然函数。
2.1 Architecture(模型结构)


这一段有几个重点:
- BART模型中,激活函数使用了GeLUs而不是ReLU;
- 参数随机初始化使用的是均值为0,方差为0.02的正态分布;
- Bart-base是6层编解码器,Bart-large是12层;
与此同时,作者指出了BART和BERT的不同:
- 解码器的每一层中cross-attention部分的k和v使用的是Encoder最后一层的输出,q是Decoder的self-attention的输出。这就是原生transformer的结构。
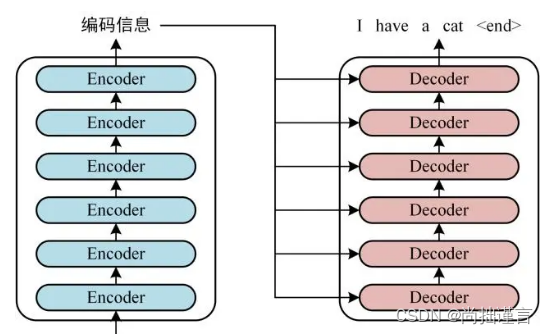
- Bert在最后输出预测前又使用了一个前馈网络(feed-forward),而BART把它去掉了。这也导致了BART比BERT在同等模型等级下,例如同样都是base,参数量减少了大概10%。
说实话,个人觉得上述两个differences有点多此一举了,因为BART的Architecture的定位本来就是Full Transformer,自然和BERT就存在上述差别。
2.2 Pre-training BART(预训练)

BART的预训练目标就是对于被破坏的文章优化一个重构损失函数,实际上就是针对Decoder的预测结果和目标文章(label)的交叉熵损失。亮点是它允许接受任意破坏形式的文章,这个还是挺强的,本人打过一些比赛,输入是一堆关键词,要求输出是基于这些关键词的完整结构的文章,用BART效果挺不错的。作者也指出了,假设极端的情况下,输入完全是空的,那么BART实质上就是一个语言模型,不是很明白作者想说明啥。
下文作者列出了几种具体的打破文章结构的方式:


- 单Token级别的掩码(Token Masking),这个和BERT一样,按一定比例随机采样Token进行[MASK];
- Token级别的丢失(Token Deletion),直接随机删掉文章中的一些单词(注意作者没有提到deletion的Token是否可以连续,因此猜测这种方式同样也包含了连续几个Token被delete的情况),这和MASK可不一样,MASK的话模型至少知道原Token在哪,而直接deletion的话,模型不仅需要知道原Token是啥,还需要知道原Token都在哪些位置,这无形就提高了模型的预测能力。
- 片段级别的Token MASK(Text Infilling),这个在上文已经解释过了,这里作者给出了片段选取的依据,即通过均值λ为3的泊松分布对span text进行采样,比如有长度为0的,长度为3的,长度为5的等等片段,将它们分别只用一个MASK替换。作者也提到这种方式和SpanBERT的思路类似,区别在于SpanBERT使用的是clamped geometric分布采样,且采出来的片段长度是多少,就用相同数量的MASK替换,可见BART实际上对这种方式的学习更加苛刻。作者也说了,text-infilling是为了让模型学习到一个MASK中原本是有多少个Token,其它们是啥。
- 句序打乱(Sentence Permutation),将完整的句子在原文中的顺序打乱,让模型学习它们原来应该在什么位置。
- 文章旋转(Document Rotation),其实就是随机在文章中取一个词,并以该词为基点将文章旋转,然后再让模型学习原文的起始Token是啥。说实话,这个操作挺骚气的,虽然看上去很牛的样子,但是还没怎么领会其中的奥妙,我觉得Sentence Permutation已经包含了这个功能了。
下面看下作者给出的几种corruption方式的示意图:
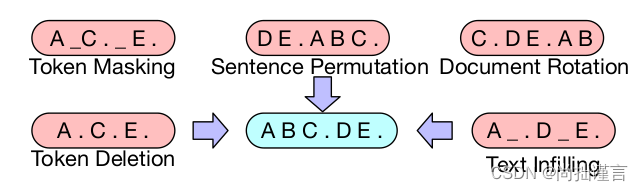
一直没太明白,作者开源的模型是这几种corruption的方式都同时用了?还是只用了其中一种或几种。
3. Fine-tuning BART(微调)
前文说了,微调的方式根据任务的不同而不同。下面是作者提到的几种任务的微调:
3.1 Sequence Classification Tasks(分类任务)

Encoder和Decoder接受了相同的输入,然后取Decoder的输出的最后一个Token的hidden state接上一个分类层进行微调,实际上调的就是这个分类层,思路和BERT的分类任务微调极其相似,但Token的选取是不一样的,BERT中,是在输入序列的第一个位置添加了[CLS]Token,最后输出取得也是这个CLS,而BART是在最后一个位置添加的[CLS],所以最后取得也是最后一个Token,作者认为这样能使最后一个Token的表示参考了前面所有Token的语义信息。个人认为合理与否得看具体实验对比,事实上本身要取哪个Token来表征整个句子都不是写死的。
3.2 Token Classification Tasks(Token级别的分类任务)

Token级别的分类任务有实体识别、阅读理解、问答等,均为抽取式。该任务和句子分类类似,只不过这里用到了Decoder输出的每一个Token的hidden state,即对每个Token进行分类。
3.3 Sequence Generation Tasks(文本生成任务)


该任务可以算是BART的强项所在了,由于其模型结构特点,它天然支持序列生成任务,例如抽象问答任务和摘要任务(注意是生成式的非抽取式的),其微调方式也很直接简单,给模型一个原始文本和一个目标文本,编码器接收原始文本,解码器解码出预测文本,并和目标文本求损失。
3.4 Machine Translation(机器翻译)
这个任务比较有意思,作者在BART的Encoder部分做了比较大的改动。

作者将原来BART的Encoder和Decoder看成了一个整体,作为新的Decoder,然后将原来Encoder的词嵌入层(embedding layer)替换成一个新的Encoder,通过新的Encoder将原始外文编码先编码,再送进原始BART的Encoder-Decoder的结构中。猜测作者认为,通过再训练一个新的编码器,并用原来的编码器和解码器统一作为解码器,以此能弥补单纯用一个Decoder造成的Decoder能力不足的缺陷。
微调的时候,作者采取了两步走的策略:第一步先只更新随机初始化的源编码器(即新Encoder)、BART的位置嵌入向量和编码器第一层的自注意输入投影矩阵(原Encoder)。其余参数固定住。第二步少量迭代全部参数。

4. Comparing Pre-training Objectives
4.1 Comparison Objects
这一节其实就是对不同类型的语言模型进行了一个对比介绍,包括GPT、XLNet、BERT、UniLM、MASS等,感兴趣的同学可以看下原文。
4.2 Tasks
这一节对一些常见的NLP任务进行了简要的介绍,感兴趣可以读一下原文。
4.3 Results
这一节展示了上述不同类型的语言模型在不同任务上以及BART不同随机噪声函数下(即上文介绍的不同文档破坏方法)在不同任务上的实验效果,并进行了对比总结:
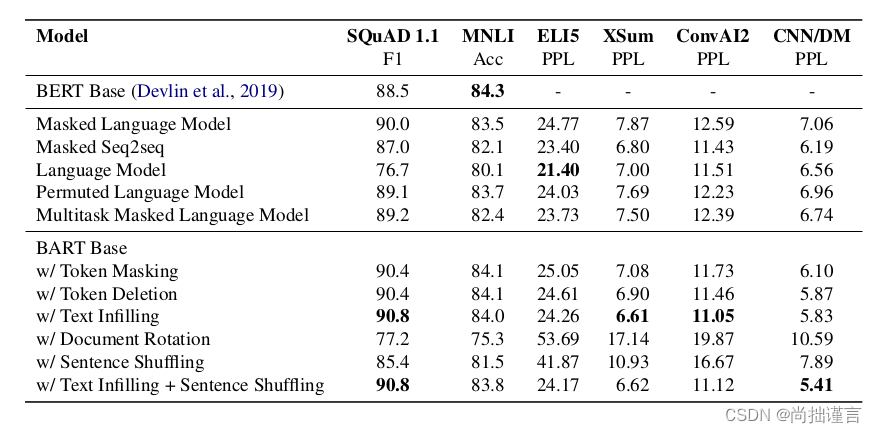
根据表格,作者得出了以下几个重要的结论:

总结来说,有以下几点:
- 预训练的效果是和预训练的任务相关的,说白了也就是和任务数据相关。
- 前文说的文档转换(Document Rotation)或句序打乱(Sentence Permutation)的方式在单独使用时表现不佳。而使用删除(Token Deletion)或掩码(Token MASK)效果比较好,这是个关键点。其中,在生成任务上,删除的方式大体上要优于掩码的方式。
- 对于生成任务,基于掩码机制和乱序机制的模型表现不如基于其它机制的模型,而前者是不包括left-to-right自回归机制的模型,由此得出,自回归机制对于生成任务来说能有效提升性能。
- 双向编码的机制在SQuAD预训练任务上是非常关键的,比如BERT模型。不过,BART模型在该任务上也表现的很好。我认为,这是因为SQuAD是一种抽取式的阅读理解任务,它不需要有很强的自由发挥的能力,而是严格的遵循预训练过程中学习的最大似然概率值下的文本语义,有种专而精的感觉,所以双向编码反而有利于这种任务。
- 预训练的方式或许不仅仅是影响性能的唯一因素,模型本身结构上的改进也是很关键的,比如相对位置编码或者分级重复(我没想到是啥)结构。
- 在ELT5任务上,BART是唯一一个表现不如其它模型的,作者认为这是因为该任务的数据集相比于其它任务具有更高的困惑性,作者得出了一个结论:当输出仅受到输入的松散约束时,换句话说,输出不需要严格的参照输入的信息,BART的效果较差,我认为,这种情况下,差不见得是坏事,因为大多数生成任务中,我们的生成结果都需要严格的参照输入的信息来的,答非所问怕不是很好。
- 除了ELI5任务外,在有Text-filling方式参与的情况下,BART的表现都很好。侧面反映了Text-filling的有效性。
5. Large-scale Pre-training Experiments
这一章讲的是BART-large的预训练实验,我就统一讲一下预训练的实验设置:


- BART-large用了12层;
- hidden size 1024维;
- 8000个batch size;
- 迭代了500000步;
- Tokenizer使用GPT-2相同的方式;
- 结合了30%的Text-filling和所有句子Sentence Permutation两种噪声方式;
- 在最后10%的step中停用dropout;
- 共使用160Gb的数据;
作者还在几个不同的生成式任务中进行了进一步实验对比,感兴趣的可以看下原文。这里特别提一下在生成任务中,微调阶段作者用的是smoothed cross entropy loss,平滑因子设置为0.1。在模型推理阶段,作者设置了Beam Search的方式,大小为5,还设置了最小生成长度和最大生成长度以及长度惩罚。

另外,作者还侧面说明了BART更擅长于抽象式生成任务,因为作者发现,如果摘要在原文中有高度相似之处时,不管是抽取式模型还是生成模型,都表现的差不多。
到此为止,事实上BART的核心要点都介绍完了,论文其余的部分仅仅是常规内容,想要全面了解BART的同学,建议读一下原文以及源码。