一次函数的线性回归
首先我们回顾一下当回归函数为一次函数的情况
存在训练样本矩阵 X ,该矩阵大小为m*n ,其中m为样本数量,n为特征数量
此时回归方程为

其中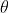 为系数向量
为系数向量
此时代价函数为
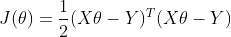
当代价函数取得最小值时,为最优解
对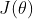 进行求导得到
进行求导得到
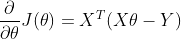
批量梯度下降法
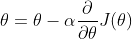
其中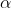 为步长系数,
为步长系数,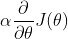 为步长,不断迭代上式,当步长变化小于某个值时,认为得到代价函数的局部最小值。
为步长,不断迭代上式,当步长变化小于某个值时,认为得到代价函数的局部最小值。
数学上,梯度方向是函数值下降最为剧烈的方向。那么,沿着 J(θ) 的梯度方向走,我们就能接近其最小值,或者极小值,从而接近更高的预测精度。
多项式的线性回归
此时回归方程为

代价函数
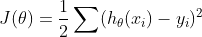
此时我们可以通过遍历矩阵来计算该代价函数的导数,但是会感觉到编程复杂
那么可以像一次函数一样去用矩阵表示代价函数吗?
是可以的,我们只需要将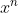 视作一个整体就可以了
视作一个整体就可以了
在一次回归中,样本矩阵 X为 [1,X] 其中 1 表示该列都为1
在多项式回归中,我们可以将 X 扩展为 [1,X,X^2,X^3,...,X^n]
此时我们回到了一次回归的矩阵运算中
具体程序可参考
https://download.csdn.net/download/qq_32478489/10651951