Python微信订餐小程序课程视频
https://edu.csdn.net/course/detail/36074
Python实战量化交易理财系统
https://edu.csdn.net/course/detail/35475
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器—(7) —Distributed Hash之前向传播
目录* [源码解析] NVIDIA HugeCTR,GPU 版本参数服务器—(7) —Distributed Hash之前向传播
+ 0x00 摘要
+ 0x01 前文回顾
+ 0x02 总体逻辑
- 2.1 注释&思路
- 2.2 总体代码
+ 0x03 配置数据
- 3.1 CUB函数
* 3.1.1 cub::DeviceScan::InclusiveSum
* 3.1.2 cub::DeviceSelect::If
* 3.1.3 临时存储
- 3.2 配置数据
+ 0x04 Lookup操作
- 4.1 提取数据
- 4.2 查找
* 4.2.1 查找算子
* 4.2.2 get_insert
- 4.3 combiner
* 4.3.1 为何要聚合
* 4.3.2 设计准则
* 4.3.3 Combiner代码
+ 4.3.3.1 例子
+ 4.3.3.2 要点
+ 4.3.3.3 注释版代码
+ 4.3.3.4 并行操作
* 4.3.4 嵌入表大小
+ 0x05 Reduce Scatter
- 5.1 背景知识
- 5.2 代码
+ 0x06 Combiner
- 6.1 AllReduce
- 6.2 Forward Scale
+ 0x07 总结
+ 0xFF 参考
0x00 摘要
在这系列文章中,我们介绍了 HugeCTR,这是一个面向行业的推荐系统训练框架,针对具有模型并行嵌入和数据并行密集网络的大规模 CTR 模型进行了优化。
其中借鉴了HugeCTR源码阅读 这篇大作,特此感谢。
本系列其他文章如下:
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(1)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器— (2)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器—(3)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器— (4)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器— (5) 嵌入式hash表
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器— (6) — Distributed hash表
0x01 前文回顾
目前为止,逻辑如下:

现在我们知道了DistributedSlotSparseEmbeddingHash的基本结构,接下来看前向传播。
为了更好的说明,我们给出一个实际例子,假定一共有两个slot(User ID 和 Item ID),每个slot内部最长为4个元素,稠密向量长度 embedding_vec_size 是8。下面CSR文件之中,每行是一个slot,所以一共有两个样本,每个样本两行,假定batch size = 2,所以这两个样本一起训练。
* 40,50,10,20
* 30,50,10
* 30,20
* 10
* Will be convert to the form of:
* row offset: 0,4,7,9,10
* value: 40,50,10,20,30,50,10,30,20,10
第一个样本包括:
40,50,10,20 # slot 1
30,50,10 # slot 2
第二个样本是
30,20 # slot 1
10 # slot 2
0x02 总体逻辑
前向传播的总体功能是:Embedded_lookuper负责本地gpu计算和查找嵌入向量,即用户输入->嵌入向量。这里只考虑 *train* 名字的各种变量,忽略 *evalute* 名字的各种变量,即只看训练逻辑。
2.1 注释&思路
源码之中的注释如下:
/**
* All the CUDA kernel functions used by embedding layer are defined in this file, including
* forward propagation, backward propagation. The functions are defined by propagation type
* and combiner type(sum or mean) as below:
* 1) forward
* sum: calling forward\_sum\_kernel()
* mean: calling foward\_sum\_kernel() + forward\_scale\_kernel()
* 2) backward:
* calculating wgrad:
* sum: calling backward\_sum\_kernel()
* mean: calling backward\_mean\_kernel()
* update embedding table: including several steps as below,
* step1: expand sample IDs, calling sample\_id\_expand\_kernel()
* step2: get value\_index by key (will call hash\_table->get\_insert() in nv\_hashtable lib)
* step3: sort by value\_index (will call cub::DeviceRadixSort::SortPairs in cub lib)
* step4: count the number for each unduplicated value\_index, calling value\_count\_kernel()
* step5: use optimizer method to compute deltaw, and record corresponding, including three
* types of optimizer: Adam: caling opt\_adam\_kernel() Momentum sgd: calling
* opt\_momentum\_sgd\_kernel() Nesterov: calling opt\_nesterov\_kernel() step6: update embedding table
* by deltaw, calling update\_kernel()
*/
我们翻译梳理逻辑如下 Read data from input_buffers_ -> look up -> write to output_tensors,具体就是:
- 从
input_buffers_读取数据。具体是通过 filter_keys_per_gpu 来完成对 embedding_data_ 的一系列配置。
- 从embedding之中进行 look up,即调用 functors_.forward_per_gpu 从本gpu的hashmap做lookup操作。
- 由 DistributedSlotSparseEmbeddingHash 的特点我们知道,因为当前gpu对应的数据key都在此gpu,所以此时不需要做节点间通信。
- 这里
hash_tables_[i],hash_table_value_tensors_[i],hash_value_index_tensors_[i] 就是本地第 i 个GPU对应的hashmap组合。
- embedding_data_.get_value_tensors(is_train)[i] 就是从我们之前提到的GPU sparse input 内部提取的输入训练数据。
- 进行本地规约。
- 做reduce scatter操作。每个gpu的数据是batch size条,但是每条数据里的每个slot只是一部分key,需要做reduce scatter操作,做完reduce scatter后,数据才是完整的,此时每个gpu上分到完整数据的一部分。
- 写到output_tensors。
具体一些成员变量的定义需要回忆一下。
- hash_value_index_tensors_ :embedding vector表的row index。就是低维矩阵的 row offset。
- 需要注意,其类型是 Tensors2,其类型是 std::vector>,所以每一个GPU对应该vector之中的一个元素。
- index 和 value 的行数相关。
- 内容是hash table value_index(row index of embedding)。
- hash_table_value_tensors_ :embedding vector表的value。就是低维矩阵。
- 需要注意,其类型是 Tensors2,其类型是 std::vector>,所以每一个GPU对应该vector之中的一个元素。
- 其内容是embedding vector。
- 用hash_value_index_tensors_的结果在这里查找一个 embedding vector。
后续我们依然做简化,忽略多个 worker,多个 GPU 的情况。
2.2 总体代码
前向传播总体代码如下:
- 本地多个GPU并行前向传播,每个线程对应一个GPU,多GPU进行。
- 调用 filter_keys_per_gpu 完成完成了对 EmbeddingData 的配置,这里i就是GPU index,拿到本GPU对应的输入数据。
- 调用 forward_per_gpu 从本gpu的hashmap做lookup操作。
- reduce scatter,做了之后,数据才是完整的,每个gpu上分到完整数据的一部分。
- all_reduce 操作,这是combiner=mean时需要继续处理。
- forward_scale 操作,做平均。
/**
* The forward propagation of embedding layer.
*/
void forward(bool is\_train, int eval\_batch = -1) override {
// Read data from input\_buffers\_ -> look up -> write to output\_tensors
#pragma omp parallel num\_threads(embedding\_data\_.get\_resource\_manager().get\_local\_gpu\_count())
{ // 本地多个GPU并行前向传播
// 每个线程对应一个GPU,多GPU进行
size\_t i = omp\_get\_thread\_num(); // 拿到本线程序号
CudaDeviceContext context(embedding\_data\_.get\_local\_gpu(i).get\_device\_id());
if (embedding_data_.embedding_params_.is_data_parallel) {
// 这里完成了对 EmbeddingData 的配置,这里i就是GPU index
filter\_keys\_per\_gpu(is_train, i, embedding_data_.get\_local\_gpu(i).get\_global\_id(),
embedding_data_.get\_resource\_manager().get\_global\_gpu\_count());
}
// 从本gpu的hashmap做lookup操作
// 这里 hash\_tables\_[i],hash\_table\_value\_tensors\_[i],hash\_value\_index\_tensors\_[i] 就是对应的hashmap
functors_.forward_per_gpu(embedding_data_.embedding_params_.get\_batch\_size(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, 0, is_train,
embedding_data_.get\_row\_offsets\_tensors(is_train)[i],
embedding_data_.get\_value\_tensors(is_train)[i],
*embedding_data_.get\_nnz\_array(is_train)[i], *hash_tables_[i],
hash_table_value_tensors_[i], hash_value_index_tensors_[i],
embedding_feature_tensors_[i],
embedding_data_.get\_local\_gpu(i).get\_stream());
}
// do reduce scatter
// 做了之后,数据才是完整的,每个gpu上分到完整数据的一部分
size\_t recv_count = embedding_data_.get\_batch\_size\_per\_gpu(is_train) *
embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.embedding_vec_size;
functors_.reduce\_scatter(recv_count, embedding_feature_tensors_,
embedding_data_.get\_output\_tensors(is_train),
embedding_data_.get\_resource\_manager());
// scale for combiner=mean after reduction
if (embedding_data_.embedding_params_.combiner == 1) {
size\_t send_count = embedding_data_.embedding_params_.get\_batch\_size(is_train) *
embedding_data_.embedding_params_.slot_num +
1;
functors_.all\_reduce(send_count, embedding_data_.get\_row\_offsets\_tensors(is_train),
row_offset_allreduce_tensors_, embedding_data_.get\_resource\_manager());
// do average
functors_.forward_scale(
embedding_data_.embedding_params_.get\_batch\_size(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, row_offset_allreduce_tensors_,
embedding_data_.get\_output\_tensors(is_train), embedding_data_.get\_resource\_manager());
}
return;
}
具体流程是:

0x03 配置数据
之前,在EmbeddingData 初始化时候,只是配置了其成员函数 train_keys_,train_keys_ 就是前面提到的 sparse_input,就是CSR format对应的稀疏张量。
template <typename TypeKey, typename TypeEmbeddingComp>
class EmbeddingData {
public:
const Embedding_t embedding_type_;
SparseEmbeddingHashParams embedding_params_; /**< Sparse embedding hash params. */
std::vector>>
bufs\_; /**< The buffer for storing output tensors. */
Tensors2 train\_output\_tensors\_; /**< The output tensors. */
Tensors2 evaluate\_output\_tensors\_; /**< The output tensors. */
Tensors2 train\_row\_offsets\_tensors\_; /**< The row\_offsets tensors of the input data. */
Tensors2 train\_value\_tensors\_; /**< The value tensors of the input data. */
std::vectorsize\_t>> train\_nnz\_array\_;
Tensors2
evaluate\_row\_offsets\_tensors\_; /**< The row\_offsets tensors of the input data. */
Tensors2 evaluate\_value\_tensors\_; /**< The value tensors of the input data. */
std::vectorsize\_t>> evaluate\_nnz\_array\_;
std::shared\_ptr resource\_manager\_; /**< The GPU device resources. */
SparseTensors train\_keys\_;
SparseTensors evaluate\_keys\_;
Tensors2 embedding\_offsets\_;
}
此时数据如下, embedding_offsets_ 和 train_output_tensors_ 都是预先分配的,我们假设 CSR 数据为 :40,50,10,20,30,50,10,30,20,CSR row offset 是 0,4,7,9。

3.1 CUB函数
我们首先要介绍几个cub库的方法,这是NVIDIA提供的函数库,用来操作CUDA,把一些常见方法用并行化来实现,比如数组求和,不并行计算就是从头查到尾,如果CUDA并行,则可以高速实现。其网址为:https://docs.nvidia.com/cuda/cub/index.html,配置数据中就采用其中了几个方法。
3.1.1 cub::DeviceScan::InclusiveSum
此函数作用是使用GPU来计算inclusive prefix sum。
使用举例如下:
* int num_items; // e.g., 7
* int *d_in; // e.g., [8, 6, 7, 5, 3, 0, 9]
* int *d_out; // e.g., [ , , , , , , ]
* ...
*
* // Determine temporary device storage requirements for inclusive prefix sum
* void *d_temp_storage = NULL;
* size\_t temp_storage_bytes = 0;
* cub::DeviceScan::InclusiveSum(d_temp_storage, temp_storage_bytes, d_in, d_out, num_items);
*
* // Allocate temporary storage for inclusive prefix sum
* cudaMalloc(&d_temp_storage, temp_storage_bytes);
*
* // Run inclusive prefix sum
* cub::DeviceScan::InclusiveSum(d_temp_storage, temp_storage_bytes, d_in, d_out, num_items);
*
* // d\_out <-- [8, 14, 21, 26, 29, 29, 38]
函数实现为:
/**
* \brief Computes a device-wide inclusive prefix sum.
*
* \par
* - Supports non-commutative sum operators.
* - Provides "run-to-run" determinism for pseudo-associative reduction
* (e.g., addition of floating point types) on the same GPU device.
* However, results for pseudo-associative reduction may be inconsistent
* from one device to a another device of a different compute-capability
* because CUB can employ different tile-sizing for different architectures.
* - \devicestorage
*/
template <
typename InputIteratorT,
typename OutputIteratorT>
CUB\_RUNTIME\_FUNCTION
static cudaError\_t InclusiveSum(
void* d\_temp\_storage, ///< [in] %Device-accessible allocation of temporary storage. When NULL, the required allocation size is written to \p temp\_storage\_bytes and no work is done.
size\_t& temp\_storage\_bytes, ///< [in,out] Reference to size in bytes of \p d\_temp\_storage allocation
InputIteratorT d\_in, ///< [in] Pointer to the input sequence of data items
OutputIteratorT d\_out, ///< [out] Pointer to the output sequence of data items
int num\_items, ///< [in] Total number of input items (i.e., the length of \p d\_in)
cudaStream\_t stream = 0, ///< [in] **[optional]** CUDA stream to launch kernels within. Default is stream0.
bool debug\_synchronous = false) ///< [in] **[optional]** Whether or not to synchronize the stream after every kernel launch to check for errors. May cause significant slowdown. Default is \p false.
{
// Signed integer type for global offsets
typedef int OffsetT;
return DispatchScan::Dispatch(
d\_temp\_storage,
temp\_storage\_bytes,
d\_in,
d\_out,
Sum(),
NullType(),
num\_items,
stream,
debug\_synchronous);
}
如果想深入研究,可以参见 https://nvlabs.github.io/cub/structcub_1_1_device_scan.html 。
3.1.2 cub::DeviceSelect::If
此函数作用是:使用 select_op 函数,将相应的元素从 d_in 分割到一个分区序列 d_out。被复制到第一个分区的元素总数被写入 d_num_selected_out。
具体使用方法为,此例子中,小于7的放在第一个分区,分区内元素数目为5.
* // Functor type for selecting values less than some criteria
* struct LessThan
* {
* int compare;
*
* CUB\_RUNTIME\_FUNCTION \_\_forceinline\_\_
* LessThan(int compare) : compare(compare) {}
*
* CUB\_RUNTIME\_FUNCTION \_\_forceinline\_\_
* bool operator()(const int &a) const {
* return (a < compare);
* }
* };
*
* // Declare, allocate, and initialize device-accessible pointers for input and output
* int num_items; // e.g., 8
* int *d_in; // e.g., [0, 2, 3, 9, 5, 2, 81, 8]
* int *d_out; // e.g., [ , , , , , , , ]
* int *d_num_selected_out; // e.g., [ ]
* LessThan select\_op(7);
* ...
*
* // Determine temporary device storage requirements
* void *d_temp_storage = NULL;
* size\_t temp_storage_bytes = 0;
* cub::DeviceSelect::If(d_temp_storage, temp_storage_bytes, d_in, d_out, d_num_selected_out, num_items, select_op);
*
* // Allocate temporary storage
* cudaMalloc(&d_temp_storage, temp_storage_bytes);
*
* // Run selection
* cub::DeviceSelect::If(d_temp_storage, temp_storage_bytes, d_in, d_out, d_num_selected_out, num_items, select_op);
*
* // d\_out <-- [0, 2, 3, 5, 2, 8, 81, 9]
* // d\_num\_selected\_out <-- [5]
函数实现是
/**
* \brief Uses the \p select\_op functor to split the corresponding items from \p d\_in into a partitioned sequence \p d\_out. The total number of items copied into the first partition is written to \p d\_num\_selected\_out.
*/
template <
typename InputIteratorT,
typename OutputIteratorT,
typename NumSelectedIteratorT,
typename SelectOp>
CUB\_RUNTIME\_FUNCTION \_\_forceinline\_\_
static cudaError\_t If(
void* d\_temp\_storage, ///< [in] %Device-accessible allocation of temporary storage. When NULL, the required allocation size is written to \p temp\_storage\_bytes and no work is done.
size\_t &temp\_storage\_bytes, ///< [in,out] Reference to size in bytes of \p d\_temp\_storage allocation
InputIteratorT d\_in, ///< [in] Pointer to the input sequence of data items
OutputIteratorT d\_out, ///< [out] Pointer to the output sequence of partitioned data items
NumSelectedIteratorT d\_num\_selected\_out, ///< [out] Pointer to the output total number of items selected (i.e., the offset of the unselected partition)
int num\_items, ///< [in] Total number of items to select from
SelectOp select\_op, ///< [in] Unary selection operator
cudaStream\_t stream = 0, ///< [in] **[optional]** CUDA stream to launch kernels within. Default is stream0.
bool debug\_synchronous = false) ///< [in] **[optional]** Whether or not to synchronize the stream after every kernel launch to check for errors. May cause significant slowdown. Default is \p false.
{
typedef int OffsetT; // Signed integer type for global offsets
typedef NullType* FlagIterator; // FlagT iterator type (not used)
typedef NullType EqualityOp; // Equality operator (not used)
return DispatchSelectIftrue>::Dispatch(
d\_temp\_storage,
temp\_storage\_bytes,
d\_in,
NULL,
d\_out,
d\_num\_selected\_out,
select\_op,
EqualityOp(),
num\_items,
stream,
debug\_synchronous);
}
};
如果想深入研究,参见 https://nvlabs.github.io/cub/structcub_1_1_device_select.html
3.1.3 临时存储
前面cub方法之中,都要有一个临时存储区域,因此 DistributedSlotSparseEmbeddingHash 之中有一个 DistributedFilterKeyStorage 就是用来达到这个目的。
template <typename TypeHashKey, typename TypeEmbeddingComp>
class DistributedSlotSparseEmbeddingHash : public IEmbedding {
using NvHashTable = HashTablesize\_t>;
std::vector> filter\_keys\_storage\_;
}
DistributedFilterKeyStorage 定义如下:
template <typename TypeHashKey>
struct DistributedFilterKeyStorage {
Tensor2<size\_t> value_select_num;
Tensor2<void> temp_value_select_storage;
Tensor2 rowoffset\_select;
Tensor2<void> temp\_rowoffset\_select\_scan\_storage;
DistributedFilterKeyStorage(const std::shared\_ptr> &buf,
size\_t max\_nnz, size\_t rowoffset\_count, size\_t global\_id,
size\_t global\_num);
};
具体构建方法如下:
template <typename TypeHashKey>
DistributedFilterKeyStorage::DistributedFilterKeyStorage(
const std::shared\_ptr> &buf, size\_t max\_nnz,
size\_t rowoffset\_count, size\_t global\_id, size\_t global\_num) {
buf->reserve({1}, &value\_select\_num);
// select value
{
distributed\_embedding\_kernels::HashOp select\_op{global\_id, global\_num};
size\_t size\_in\_bytes = 0;
cub::DeviceSelect::If(nullptr, size\_in\_bytes, (TypeHashKey *)nullptr, (TypeHashKey *)nullptr,
(size\_t *)nullptr, max\_nnz, select\_op);
buf->reserve({size\_in\_bytes}, &temp\_value\_select\_storage);
}
// count rowoffset
{
size\_t size\_in\_bytes = 0;
cub::DeviceScan::InclusiveSum(nullptr, size\_in\_bytes, (TypeHashKey *)nullptr,
(TypeHashKey *)nullptr, rowoffset\_count);
buf->reserve({size\_in\_bytes}, &temp\_rowoffset\_select\_scan\_storage);
}
buf->reserve({rowoffset\_count}, &rowoffset\_select);
}
3.2 配置数据
在前向传播之中,首先就是在 filter_keys_per_gpu 之中使用 train_keys_ 来对其他成员变量进行配置,目的是拿到本GPU上 DistributedSlotSparseEmbeddingHash 对应的输入数据。回忆一下,EmbeddingData 的这几个成员变量 get_output_tensors,get_input_keys,get_row_offsets_tensors,get_value_tensors,get_nnz_array 都返回引用,这说明大部分成员变量都是可以被直接修改的。具体配置代码如下:
template <typename TypeHashKey, typename TypeEmbeddingComp>
void DistributedSlotSparseEmbeddingHash::filter\_keys\_per\_gpu(
bool is\_train, size\_t id, size\_t global\_id, size\_t global\_num) {
// 对当前GPU进行配置
// 得到 train\_keys\_,利用它来配置row offsets和value
const SparseTensor &all\_gather\_key = embedding\_data\_.get\_input\_keys(is\_train)[id];
// 得到 embedding\_data\_.train\_row\_offsets\_tensors\_,修改 rowoffset\_tensor 就是修改此成员变量
Tensor2 rowoffset\_tensor = embedding\_data\_.get\_row\_offsets\_tensors(is\_train)[id];
// 得到 embedding\_data\_.train\_value\_tensors\_,修改 value\_tensor 就是修改此成员变量
Tensor2 value\_tensor = embedding\_data\_.get\_value\_tensors(is\_train)[id];
std::shared\_ptr<size\_t> nnz\_ptr = embedding\_data\_.get\_nnz\_array(is\_train)[id];
auto &filter\_keys\_storage = filter\_keys\_storage\_[id];
auto &stream = embedding\_data\_.get\_local\_gpu(id).get\_stream();
size\_t batch\_size = embedding\_data\_.embedding\_params\_.get\_batch\_size(is\_train);
size\_t slot\_num = (all\_gather\_key.rowoffset\_count() - 1) / batch\_size;
size\_t rowoffset\_num = batch\_size * slot\_num + 1;
size\_t rowoffset\_num\_without\_zero = rowoffset\_num - 1;
// select value
{
distributed\_embedding\_kernels::HashOp select\_op{global\_id, global\_num};
size\_t size\_in\_bytes = filter\_keys\_storage.temp\_value\_select\_storage.get\_size\_in\_bytes();
// 配置 embedding\_data\_.train\_value\_tensors\_
cub::DeviceSelect::If(filter\_keys\_storage.temp\_value\_select\_storage.get\_ptr(), size\_in\_bytes,
all\_gather\_key.get\_value\_ptr(), value\_tensor.get\_ptr(),
filter\_keys\_storage.value\_select\_num.get\_ptr(), all\_gather\_key.nnz(),
select\_op, stream);
}
// select rowoffset
{
cudaMemsetAsync(filter\_keys\_storage.rowoffset\_select.get\_ptr(), 0,
filter\_keys\_storage.rowoffset\_select.get\_size\_in\_bytes(), stream);
{
constexpr int block\_size = 512;
int grid\_size = (rowoffset\_num\_without\_zero - 1) / block\_size + 1;
distributed\_embedding\_kernels::select\_rowoffset<<0, stream>>>(
all\_gather\_key.get\_rowoffset\_ptr(), rowoffset\_num\_without\_zero,
all\_gather\_key.get\_value\_ptr(), filter\_keys\_storage.rowoffset\_select.get\_ptr(), global\_id,
global\_num);
}
{
size\_t size\_in\_bytes =
filter\_keys\_storage.temp\_rowoffset\_select\_scan\_storage.get\_size\_in\_bytes();
// 配置row offset,就是拷贝到 rowoffset\_tensor之中。
cub::DeviceScan::InclusiveSum(
filter\_keys\_storage.temp\_rowoffset\_select\_scan\_storage.get\_ptr(), size\_in\_bytes,
filter\_keys\_storage.rowoffset\_select.get\_ptr(), rowoffset\_tensor.get\_ptr(), rowoffset\_num,
stream);
}
// select nnz
// 直接拷贝即可
cudaMemcpyAsync(nnz\_ptr.get(), filter\_keys\_storage.value\_select\_num.get\_ptr(), sizeof(size\_t),
cudaMemcpyDeviceToHost, stream);
}
}
配置完成之后,得到如下,其中 train_value_tensors_ 对应了csr value,train_row_offsets_tensors_ 对应了csr row offset,从SparseTensor拷贝到 EmbeddingData。

结合我们例子,最后前向传播输入训练数据是:

0x04 Lookup操作
此部分就是完成嵌入表 look up操作。现在EmbeddingData得到了各种配置,就是sparse input参数,所以可以利用其作为key,得到embedding vector了。这部分是在 forward_per_gpu 内部完成的。
functors_.forward_per_gpu(embedding_data_.embedding_params_.get\_batch\_size(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, 0, is_train,
embedding_data_.get\_row\_offsets\_tensors(is_train)[i],
embedding_data_.get\_value\_tensors(is_train)[i],
*embedding_data_.get\_nnz\_array(is_train)[i], *hash_tables_[i],
hash_table_value_tensors_[i], hash_value_index_tensors_[i],
embedding_feature_tensors_[i],
embedding_data_.get\_local\_gpu(i).get\_stream());
}
4.1 提取数据
这里用到了比如 get_row_offsets_tensors 这样的方法从 embedding_data_ 之中提取输入数据。从input_buffers_读取数据对应的提取数据代码如下,就是从GPU的sparse input csr数据中读取到输入数据,作为后续在hash table查找的key:
Tensors2& get\_value\_tensors(bool is\_train) {
if (is_train) {
return train_value_tensors_;
} else {
return evaluate_value_tensors_;
}
}
从 CSR 读取 offset 代码如下:
Tensors2& get\_row\_offsets\_tensors(bool is\_train) {
if (is_train) {
return train_row_offsets_tensors_;
} else {
return evaluate_row_offsets_tensors_;
}
}
因为输入有几千万个,但是可能其中只有几百个才非零,所以hash表就是把这几千万个输入做第一次映射,可以减少大量内存空间。
4.2 查找
目前代码来到了这里,就是利用哈希表来从输入CSR得到对应的嵌入向量。

forward_per_gpu 分为两部分:查找和内部规约。
4.2.1 查找算子
forward_per_gpu 函数是用来具体做lookup的。从其注释可以看到其用途,就是我们之前分析过的。
@param row_offset row_offset (CSR format of input sparse tensors)
@param hash_key value (CSR format of input sparse tensors)
@param nnz non-zero feature number per batch
@param hash_table hash table, pairs of
@param hash\_table\_value hash table value, which represents embedding vector
@param hash\_value\_index hash table value\_index(row index of embedding)
这里的参数都是引用,可以修改外部数据,具体思路是:
- 首先使用 hash_key value (CSR format of input sparse tensors) 来调用 get_insert 去 hash table 之中查找,如果找到了,得到的就是 hash_value_index。这个value 是 低维 embedding表 的 row index。这部分代码是 hash_table.get_insert 相关。其实,这里没有用到get_insert 返回值,而是把 hash_key value 插进哈希表内部,得到一个映射,具体如何查找是通过 csr row offset完成。
- hash_table.get_insert 如果在 hash_table 的内部数据结构之中找到了,就返回,如果没有找到,就插入一个递增的数值,这个数值被设置到 hash_value_index 之中。
- 然后通过 hash_value_index 作为 index,在 hash_table_value 之中得到最终的 embedding vector,并且先在slot内部做reduce。这部分代码是 forward_sum 和 forward_mean 相关。
所以 hash_table_value_tensors_[i], hash_value_index_tensors_ 这两部分何时设置?其实是在forward_per_gpu完成的,具体逻辑如图:
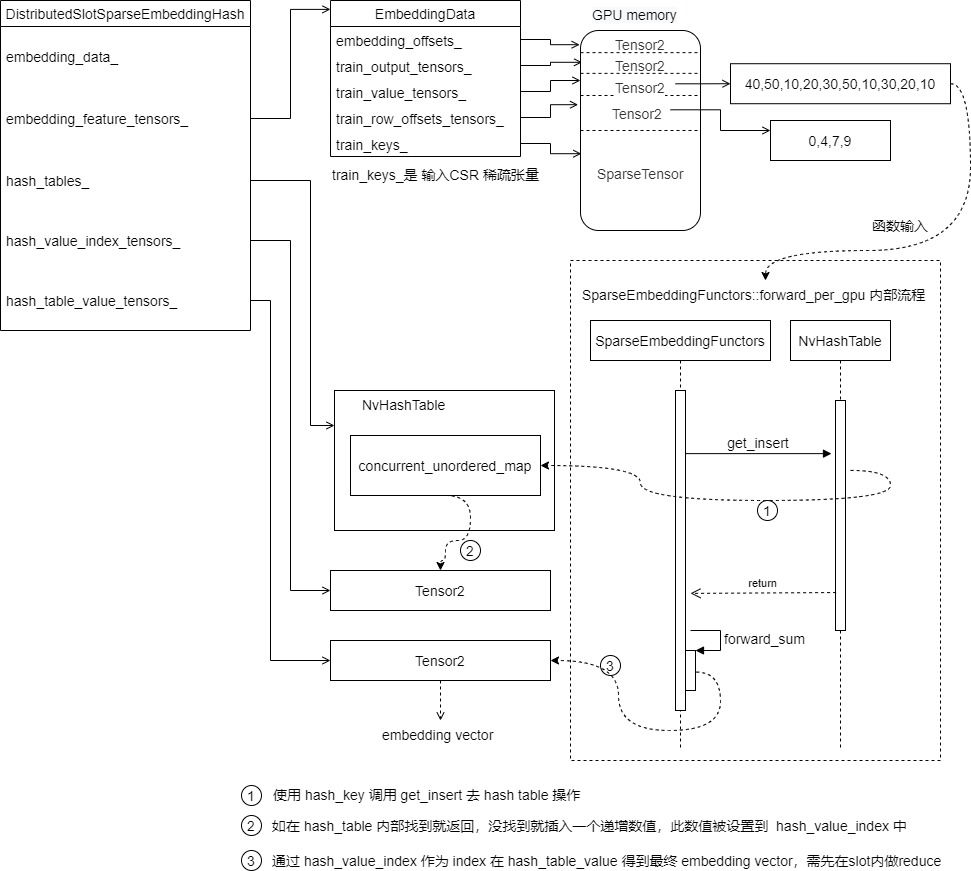
具体代码是:
/**
* forward propagation on each GPU for LocalizedSlotSparseEmbeddingHash
* @param batch\_size batch size for the current mini-batch computation.
* @param slot\_num the number of slots for current GPU
* @param embedding\_vec\_size embedding vector size.
* @param combiner 0-sum; 1-mean
* @param row\_offset row\_offset (CSR format of input sparse tensors)
* @param hash\_key value (CSR format of input sparse tensors)
* @param nnz non-zero feature number per batch
* @param hash\_table hash table, pairs of
* @param hash\_table\_value hash table value, which represents embedding vector
* @param hash\_value\_index hash table value\_index(row index of embedding)
* @param embedding\_feature embedding feature (output)
* @param stream cuda stream
*/
template <typename TypeHashKey, typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::forward\_per\_gpu(
size\_t batch\_size, size\_t slot\_num, size\_t embedding\_vec\_size, int combiner, bool train,
const Tensor2 &row\_offset, const Tensor2 &hash\_key, size\_t nnz,
HashTablesize\_t> &hash\_table, const Tensor2<float> &hash\_table\_value,
Tensor2<size\_t> &hash\_value\_index, Tensor2 &embedding\_feature,
cudaStream\_t stream) {
try {
if (train) { // 训练会来到这里
// 先从hash\_table之中依据 hash\_key 得到hash\_value\_index 之中对应的位置,作用就是让 hash\_value\_index 之中包含所有key对应的内部hash\_value\_index
// 其实,这里是否返回不重要,重要的是把hash\_key value插进哈希表内部,具体如何查找是通过csr row offset完成
hash_table.get\_insert(hash_key.get\_ptr(), hash_value_index.get\_ptr(), nnz, stream);
} else {
hash_table.get\_mark(hash_key.get\_ptr(), hash_value_index.get\_ptr(), nnz, stream);
}
// do sum reduction
if (combiner == 0) { // 0-sum; 1-mean
// 然后利用 hash\_value\_index 从 hash\_table\_value 之中得到 value,再进行操作
forward_sum(batch_size, slot_num, embedding_vec_size, row_offset.get\_ptr(),
hash_value_index.get\_ptr(), hash_table_value.get\_ptr(),
embedding_feature.get\_ptr(), stream);
} else if (combiner == 1) {
// 然后利用 hash\_value\_index 从 hash\_table\_value 之中得到 value,再进行操作
forward_mean(batch_size, slot_num, embedding_vec_size, row_offset.get\_ptr(),
hash_value_index.get\_ptr(), hash_table_value.get\_ptr(),
embedding_feature.get\_ptr(), stream);
} else {
CK\_THROW\_(Error_t::WrongInput, "Invalid combiner type ");
}
} catch (const std::runtime_error &rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
算子内部也分为 get_insert 来处理哈希表,和 combiner 处理,我们一一看看。
4.2.2 get_insert
前面我们分析了哈希表的 get 和 insert 操作,这里是合而为一,就是如果找不到就插入。开始训练时候,不需要给哈希表赋初值,而是在训练过程之中使用get_insert动态插入。
我们再回忆下原理。
比如一共有1亿个单词,40表示第40个单词。如果想表示 10,30,40,50,20在这一亿个单词是有效的,最常见的办法是弄个1亿长度数组,把40,50,20,30,10这5个位置设置为1,其他位置设置为0。对应嵌入矩阵也是一个高维矩阵,比如 1亿 x 64 维度矩阵。
如果想省空间,就弄会构建一个小数据结构(低维矩阵)来存储这些有意义的值,弄一个一个hash函数 m_hf来做"从高维矩阵到低维矩阵的转换",就是10 -->?,20 --> ? 等。
假如是选取十位数数为key,对于我们的例子,就是
m\_hf(10)=1
m\_hf(20)=2
m\_hf(30)=3
m\_hf(40)=4
m\_hf(50)=5
1,2,3,4,5 就是内部的hash_value,叫做 hash_value(对应下面代码),对应的内部存储数组叫做 hashtbl_values。但是因为分桶了,所以在哈希表内部是放置在hashtbl_values之中(这里我们做了一个简化,就是 hashtbl_values[i] = i)。
hashtbl_values[1] = 1,hashtbl_values[2] = 2, hashtbl_values[3] = 3,...
以上说的是哈希表,我们回到 DistributedSlotSparseEmbeddingHash 本身,于是1,2,3 (数组之中的内容,不是数组index,简化成恰好相等)就是DistributedSlotSparseEmbeddingHash 想得到的 10, 20, 30 对应的数据,就是10 放在低维嵌入表第一个位置,20放在低维嵌入表第二个位置,就是就是低维矩阵的row offset。即,hash_value_index 的内容是 [1,2,3,4,5],这些是原始输入数据 10,20,30,40,50 分别在 hash_table_value 之中对应的index,因此,10 对应的就是 hash_table_value[1],20 对应就是 hash_table_value[2],依此类推。
再返回哈希表,NvHashTable 的 get_insert 代码如下。
template <typename KeyType, typename ValType>
void NvHashTable::get\_insert(const void *d\_keys, void *d\_vals, size\_t len, cudaStream\_t stream) {
const KeyType *\_d\_keys = reinterpret\_cast<const KeyType*>(d\_keys);
ValType *\_d\_vals = reinterpret\_cast(d\_vals);
return hashtable\_.get\_insert(\_d\_keys, \_d\_vals, len, stream);
}
HashTable 的 get_insert 位于 sparse_operation_kit/kit_cc/kit_cc_infra/src/hashtable/nv_hashtable.cu。这里是在GPU进行并行操作,提取value。
template <typename Table>
\_\_global\_\_ void get\_insert\_kernel(Table* table, const typename Table::key\_type* const keys,
typename Table::mapped\_type* const vals, size\_t len,
size\_t* d\_counter) {
ReplaceOp<typename Table::mapped_type> op;
const size\_t i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < len) {
auto it = table->get\_insert(keys[i], op, d_counter);
vals[i] = it->second; // 在这里对外面 hash\_value\_index做了设置
}
}
template <typename KeyType, typename ValType>
void HashTable::get\_insert(const KeyType* d\_keys, ValType* d\_vals, size\_t len,
cudaStream\_t stream) {
if (len == 0) {
return;
}
const int grid\_size = (len - 1) / BLOCK\_SIZE\_ + 1;
get\_insert\_kernel<<0, stream>>>(container\_, d\_keys, d\_vals, len,
d\_counter\_);
}
最后还是来到 HugeCTR/include/hashtable/cudf/concurrent_unordered_map.cuh。如果没有value,就生成一个value。
// \_\_forceinline\_\_ 的意思是编译为内联函数
// \_\_host\_\_ \_\_device\_\_ 表示是此函数同时为主机和设备编译
template <typename aggregation_type, typename counter_type, class comparison\_type = key_equal,
typename hash_value_type = typename Hasher::result_type>
__forceinline__ __device__ iterator get\_insert(const key_type& k, aggregation_type op,
counter_type* value_counter,
comparison_type keys_equal = key\_equal(),
bool precomputed_hash = false,
hash_value_type precomputed_hash_value = 0) {
const size_type hashtbl_size = m_hashtbl_size;
value_type* hashtbl_values = m_hashtbl_values;
hash_value_type hash_value{0};
// If a precomputed hash value has been passed in, then use it to determine
// the write location of the new key
if (true == precomputed_hash) {
hash_value = precomputed_hash_value;
}
// Otherwise, compute the hash value from the new key
else {
hash_value = m\_hf(k); // 3356作为key,得到了一个hash\_value
}
size_type current_index = hash_value % hashtbl_size; // 找到哪个位置
value_type* current_hash_bucket = &(hashtbl_values[current_index]); // 找到该位置的bucket
const key_type insert_key = k;
bool insert_success = false;
size_type counter = 0;
while (false == insert_success) {
// Situation %5: No slot: All slot in the hashtable is occupied by other key, both get and
// insert fail. Return empty iterator
// hash表已经满了
if (counter++ >= hashtbl_size) {
return end();
}
key_type& existing_key = current_hash_bucket->first; // 这个才是table key
volatile mapped_type& existing_value = current_hash_bucket->second; // 这个才是table value
// 如果 existing\_key == unused\_key时,则当前哈希位置为空,所以existing\_key由atomicCAS更新为insert\_key。
// 如果 existing\_key == insert\_key时,这个位置已经被插入这个key了。
// 在任何一种情况下,都要执行existing\_value和insert\_value的atomic聚合,因为哈希表是用聚合操作的标识值初始化的,所以在existing\_value仍具有其初始值时,执行该操作是安全的
// Try and set the existing\_key for the current hash bucket to insert\_key
const key_type old_key = atomicCAS(&existing_key, unused_key, insert_key);
// If old\_key == unused\_key, the current hash bucket was empty
// and existing\_key was updated to insert\_key by the atomicCAS.
// If old\_key == insert\_key, this key has already been inserted.
// In either case, perform the atomic aggregation of existing\_value and insert\_value
// Because the hash table is initialized with the identity value of the aggregation
// operation, it is safe to perform the operation when the existing\_value still
// has its initial value
// TODO: Use template specialization to make use of native atomic functions
// TODO: How to handle data types less than 32 bits?
// Situation #1: Empty slot: this key never exist in the table, ready to insert.
if (keys\_equal(unused_key, old_key)) { // 如果没有找到hash key
existing_value = (mapped_type)(atomicAdd(value_counter, 1)); // hash value 就递增
break;
} // Situation #2+#3: Target slot: This slot is the slot for this key
else if (keys\_equal(insert_key, old_key)) {
while (existing_value == m_unused_element) {
// Situation #2: This slot is inserting by another CUDA thread and the value is not yet
// ready, just wait
}
// Situation #3: This slot is already ready, get successfully and return (iterator of) the
// value
break;
}
// Situation 4: Wrong slot: This slot is occupied by other key, get fail, do nothing and
// linear probing to next slot.
// 此位置已经被其他key占了,只能向后遍历
current_index = (current_index + 1) % hashtbl_size;
current_hash_bucket = &(hashtbl_values[current_index]);
}
return iterator(m_hashtbl_values, m_hashtbl_values + hashtbl_size, current_hash_bucket);
}
具体逻辑演进如下:

4.3 combiner
拿到了多个向量之后,需要做聚合,因为此处过于繁琐,因此我们单独拿出来说一下,把它提升到和查找一个级别,大家不要误会。
4.3.1 为何要聚合
在CTR领域,人们通常会把多个embedding向量合并成一个向量,这就是pooling。比如用户看了3本艺术书,2本体育书,所以 读书习惯 = 3 * 艺术 + 2 * 体育。这种聚合经常使用加权的pooling,而不是concat。因为虽然concat效果更好,但是pooling更快,而且这样做好处就是即使向量长度不同,也可以生成一个同样长度的新张量。比如:特征的embeddingSize是10,现在所有Field的个数是50,其中5个Field是序列形式的特征(对于序列长度的上限取40)。此时你有两种处理方式:
- mean/sum pooling :embedding层的参数量是10 * 50 = 500
- concat :embedding层的参数量是 10*(50-5) + 40 * 10 * 5 = 2450
如果使用 concat,则embedding层的参数量直接涨了4倍左右,实际ctr模型种参数量最大部分一般就是embedding -> MLP的这一层,所以concat会直接拖慢线上inference的速度。
4.3.2 设计准则
我们回忆一下前面提到的设计准则:嵌入表可以被分割成多个槽(或feature fields)。为了在不同的嵌入上获得最佳性能,可以选择不同的嵌入层实现。
-
LocalizedSlotEmbeddingHash:同一个槽(特征域)中的特征会存储在一个GPU中,这就是为什么它被称为“本地化槽”,根据槽的索引号,不同的槽可能存储在不同的GPU中。
-
DistributedSlotEmbeddingHash:所有特征都存储于不同特征域/槽上,不管槽索引号是多少,这些特征都根据特征的索引号分布到不同的GPU上。这意味着同一插槽中的特征可能存储在不同的 GPU 中,这就是将其称为“分布式插槽”的原因。由于需要全局规约,所以DistributedSlotEmbedding 适合 embedding 大于 GPU 内存大小的情况,因而DistributedSlotEmbedding 在 GPU 之间有更多的内存交换。
一定要注意,LocalizedSlotEmbeddingHash 和 DistributedSlotEmbeddingHash 的区别在于同一个槽(特征域)中的特征 是不是 会存储在同一个GPU中。比如,有 2 张GPU卡,有4个slot。
- local模式 :GPU0存slot0和slot1,GPU1存slot2和slot3。
- distribute模式 :每个GPU都会存所有slot的一部分参数,通过哈希方法决定如何将一个参数分配到哪个GPU上。
在嵌入查找过程中,属于同一槽的稀疏特征输入在分别转换为相应的密集嵌入向量后,被简化为单个嵌入向量。然后,来自不同槽的嵌入向量连接在一起。这个就是前面提到的combiner操作。
4.3.3 Combiner代码
现在已经拿到了 embedding table 的 index,需要看看如何拿到 embedding vector,如何仅需操作。
// do sum reduction
if (combiner == 0) { // 0-sum; 1-mean 这里是combiner类型
// 然后利用 hash\_value\_index 从 hash\_table\_value 之中得到 value,再进行操作
forward_sum(batch_size, slot_num, embedding_vec_size, row_offset.get\_ptr(),
hash_value_index.get\_ptr(), hash_table_value.get\_ptr(),
embedding_feature.get\_ptr(), stream);
} else if (combiner == 1) {
// 然后利用 hash\_value\_index 从 hash\_table\_value 之中得到 value,再进行操作
forward_mean(batch_size, slot_num, embedding_vec_size, row_offset.get\_ptr(),
hash_value_index.get\_ptr(), hash_table_value.get\_ptr(),
embedding_feature.get\_ptr(), stream);
}
具体是通过 forward_sum 和 forward_mean 完成,我们用 forward_sum 举例看看。
// do sum reduction
template <typename TypeHashKey>
void forward\_sum(size\_t batch\_size, size\_t slot\_num, size\_t embedding\_vec\_size,
const TypeHashKey *row\_offset, const size\_t *hash\_value\_index,
const float *hash\_table\_value, \_\_half *embedding\_feature, cudaStream\_t stream) {
const size\_t grid_size = batch_size; // each block corresponds to a sample
if (embedding_vec_size % 2 == 0) {
const size\_t block_size = embedding_vec_size / 2;
forward_sum_align2_kernel<<0, stream>>>(
batch\_size, slot\_num, embedding\_vec\_size / 2, row\_offset, hash\_value\_index,
hash\_table\_value, embedding\_feature);
} else {
const size\_t block\_size =
embedding\_vec\_size; // each thread corresponds to one element in an embedding vector
forward\_sum\_kernel<<0, stream>>>(
batch\_size, slot\_num, embedding\_vec\_size, row\_offset, hash\_value\_index, hash\_table\_value,
embedding\_feature);
}
}
上面代码之中需要注意两个注释
- grid_size = batch_size; // each block corresponds to a sample
- const size_t block_size = embedding_vec_size; // each thread corresponds to one element in an embedding vector
4.3.3.1 例子
回忆我们的例子:
* 40,50,10,20
* 30,50,10
* 30,20
* 10
* Will be convert to the form of:
* row offset: 0,4,7,9,10
* value: 40,50,10,20,30,50,10,30,20,10
第一个样本包括:
40,50,10,20 # slot 1
30,50,10 # slot 2
第二个样本是
30,20 # slot 1
10 # slot 2
所以,应该得到10个稠密向量,比如40有一个稠密向量,50有一个稠密向量。
怎么知道 40 对应低维嵌入表的哪一行呢?通过一个哈希表来处理的,假如哈希函数是选取十位数为key,则得到:
m\_hf(40)=4
所以,就知道了,40应该在低维嵌入表的第4行(我们对哈希表做了简化)。
4.3.3.2 要点
forward_sum_kernel 的代码如下,这里代码很烧脑,需要结合注释仔细分析,
第一个要点是回忆一下hash_value_index_tensors_的使用:
细心读者可能有疑问,如果哈希表能从高维offset映射到低维offset,这个hash_value_index_tensors_ 应该就没有用了吧?这里解释如下:
- 事实上,因为解耦合的原因,hash_value_index_tensors_ 并不应该知道 哈希表内部把高维矩阵的维度映射了多大的低维矩阵,而 hash_value_index_tensors_ 大小也不应该随之变化。
- 所以,hash_value_index_tensors_ 大小被固定为:batch_size * nnz_per_slot,可以认为就是CSR之中元素个数。所以 hash_value_index_tensors_ 实际上记录了每个元素对应的低维矩阵offset 数值,hash_value_index_tensors_ 事实上就是和CSR之中元素位置一一对应。
- 因此,最终嵌入表查找时候,是通过CSR row offset 来找到 CSR之中每个元素,从而也找到了hash_value_index_tensors_ 这个表的index,从而就能找到其低维矩阵offset。
- 针对我们的例子,hash_value_index_tensors_ 的数值就是 4,5,1,2,3,5,1,3,2,1。
其余几个要点是:
- bid 是第几个样本。
- tid 是最终嵌入向量的第几个元素,一个线程处理嵌入向量的一个元素。
- hash_value_index 是低维嵌入表的offset表的指针。
- hash_value_index 是一张表,就是上面说的hash_value_index_tensors_。
- row_offset 是CSR offset,例子就是 0,4,7,9,10,所以对于第二个样本,row offset 是 7,9。
- hash_table_value 可以认为是一个数组,低维嵌入矩阵是存储在这个数组之中。hash_table_value[value_index * embedding_vec_size] 就是对应的稠密向量。
4.3.3.3 注释版代码
// forward kernel funcion: for both combiner=sum and combiner=mean
template <typename TypeKey, typename TypeEmbeddingComp>
\_\_global\_\_ void forward\_sum\_kernel(int batch\_size, int slot\_num, int embedding\_vec\_size,
const TypeKey *row\_offset, const size\_t *hash\_value\_index,
const float *hash\_table\_value,
TypeEmbeddingComp *embedding\_feature) {
// bid是第几个样本,假如是1,那么就是第二个样本
int bid = blockIdx.x; // each block corresponding to one sample
// tid最终是嵌入向量的第几个元素,一个线程处理嵌入向量的一个元素
int tid = threadIdx.x; // each thread corresponding to one element in the embedding vector
if (bid < batch_size && tid < embedding_vec_size) { // batch\_size = 2
for (int i = 0; i < slot_num; i++) { // slot\_num = 2
// 得到当前行对应的在row offset之中的位置,比如是2或者3,就是从 0,4,7,9,10 之中找第2,第3个
int feature_row_index = bid * slot_num + i; // feature\_row\_index 范围是 2,3
// 得到当前行在CSR内的元素偏移,行0,行1 是第一个样本,行2,行3是第二个样本
TypeKey value_offset = row_offset[feature_row_index]; // 行2的偏移value\_offset是7,行3是9
// 每行有多少元素,行2对应的元素个数是9-7=2,行3对应的元素个数是10-9=1
TypeKey feature_num =
row_offset[feature_row_index + 1] - value_offset; // number of hash values in one slot
float sum = 0.0f;
// reduce in a slot
for (int j = 0; j < feature_num; j++) { // 行内元素个数,行2是2,行3是1
// 假如是行2,则value是30,20,则取出hash\_value\_index的第7,8个位置的数值,分别是3,2
size\_t value_index = hash_value_index[value_offset + j];
// 取出hash\_table\_value的第3,2个元素的数值,进行计算
// value\_index 就是具体哪一个 CSR user ID 在 hash\_table\_value 之中的起始位置,即hash\_value\_index记录了哪一个 CSR user ID 在hash\_table\_value的第几行
// hash\_table\_value[value\_index * embedding\_vec\_size] 就是 CSR user ID对应的稠密向量
// hash\_table\_value[value\_index * embedding\_vec\_size + tid] 就是 CSR user ID对应的稠密向量的第tid个element
sum += (value_index != std::numeric_limits<size\_t>::max())
? hash_table_value[value_index * embedding_vec_size + tid]
: 0.0f;
}
// store the embedding vector
// 这里就对应了2,3两行,就是一个样本的两个slots 会顺序排在一起,最终输出稠密向量的每个元素值是样本之中所有元素稠密向量对应位置元素的和
embedding_feature[feature_row_index * embedding_vec_size + tid] =
TypeConvertFuncfloat>::convert(sum);
}
}
}
4.3.3.4 并行操作
关于并行操作,留意点是:
- bid是第几个样本。
- tid 是最终嵌入向量的第几个元素,一个线程处理嵌入向量的一个元素。
- hash_table_value[value_index * embedding_vec_size] 就是 CSR user ID对应的稠密向量。
- hash_table_value[value_index * embedding_vec_size + tid] 就是 CSR user ID对应的稠密向量的第 tid 个element。
之前说了,应该是两个样本一共10个元素 40,50,10,20,30,50,10,30,20,10,应该对应10个稠密向量。但是在GPU之中会启动tid个线程并行操作,会在一个slot之中进行reduce,然后把结果存入到 embedding_feature 之中。GPU并行体现在同时生成一个稠密向量的所有元素。就是每一个sample生成 slot_num 个稠密向量。稠密向量的每个元素都是根据样本内部元素计算出来的。
比如第一个样本是:
40,50,10,20 # slot 1
30,50,10 # slot 2
- slot 1 应该输出
40 对应的稠密向量 + 50 对应的稠密向量 + 10 对应的稠密向量 + 20 对应的稠密向量。
- slot 2 应该输出
30 对应的稠密向量 + 50 对应的稠密向量 + 10 对应的稠密向量。
但经过 combiner之后,样本1输出了两个稠密向量,分别对应两个slot,假定每个稠密向量长度是8,计算方式是:
- 稠密向量1 = 40 对应的稠密向量 + 50 对应的稠密向量 + 10 对应的稠密向量 + 20 对应的稠密向量
- 稠密向量2 = 30 对应的稠密向量 + 50 对应的稠密向量 + 10 对应的稠密向量
稠密向量1内部8个元素分别是由40,50,10,20对应的稠密向量8个同位置上元素的和构成。即 稠密向量1的[0] = sum(40 对应的稠密向量的[0], 50 对应的稠密向量的[0], 10 对应的稠密向量的[0], 20 对应的稠密向量的[0] )。可以看到,其确实转成了嵌入式向量,但并不是用矩阵乘法,而是用了自己一套机制,具体入下图:

4.3.4 嵌入表大小
我们已经知道可以通过哈希表来进行缩减嵌入表大小,现在又知道其实还可以通过combine来继续化简,所以在已经有了哈希表基础之上,我们需要先问几个问题。
- 目前 hash_table_value 究竟有多大?就是权重矩阵(稠密矩阵)究竟多大?
- embedding_feature (嵌入层前向传播的输出)究竟有多大?就是输出的规约之后的矩阵应该有多大?
- embedding_feature 的每一个元素是怎么计算出来的?
- 实际矩阵有多大?
我们解答一下。
- 第一个问题hash_table_value 究竟有多大?
前文之中有分析 hash_table_value 大小是:max_vocabulary_size_per_gpu_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu;
实际上,大致可以认为,hash_table_value 的大小是:(value number in CSR) * (embedding_vec_size) 。
hash_table_value 的数值是随机初始化的。每一个原始的 CSR user ID 对应了其中的 embedding_vec_size 个元素。hash_value_index 和 row_offset 凑在一起,就可以找到每一个原始的 CSR user ID 对应了其中的 embedding_vec_size 个元素。
- 第二个问题:embedding_feature 究竟有多大?就是逻辑上的稠密矩阵究竟有多大?从代码可以看到,
embedding_feature[feature_row_index * embedding_vec_size + tid] =
TypeConvertFuncfloat>::convert(sum);
可见,embedding_feature 的大小是:(row number in CSR) * (embedding_vec_size) 。因此,对于 embedding_feature_tensors_,我们抽象一下,输入假设是4行 CSR格式,则输出就是4行稠密向量格式。
- 第三个问题:embedding_feature 的每一个元素是怎么计算出来的?
是遍历slot和element,进行计算。
sum += (value_index != std::numeric_limits<size\_t>::max())
? hash_table_value[value_index * embedding_vec_size + tid]
: 0.0f;
- 第四个问题:实际embedding矩阵,或者说工程上的稠密矩阵有多大?
其实就是 slot_num * embedding_vec_size。row number 其实就是 slot_num。从下面输出可以看到。
以 deep_data 为例,其slot num 是26,embedding_vec_size = 16,最后输出的一条样本大小是 [26 x 16]。
model.add(hugectr.Input(label_dim = 1, label_name = label,
dense_dim = 13, dense_name = dense,
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam(wide_data, 30, True, 1),
hugectr.DataReaderSparseParam(deep_data, 2, False, 26)]))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = 23,
embedding_vec_size = 1,
combiner = sum,
sparse_embedding_name = sparse_embedding2,
bottom_name = wide_data,
optimizer = optimizer))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = 358,
embedding_vec_size = 16,
combiner = sum,
sparse_embedding_name = sparse_embedding1,
bottom_name = deep_data,
optimizer = optimizer))
输出:
"------------------------------------------------------------------------------------------------------------------\n",
"Layer Type Input Name Output Name Output Shape \n",
"------------------------------------------------------------------------------------------------------------------\n",
"DistributedSlotSparseEmbeddingHash wide\_data sparse\_embedding2 (None, 1, 1) \n",
"DistributedSlotSparseEmbeddingHash deep\_data sparse\_embedding1 (None, 26, 16)
0x05 Reduce Scatter
现在每个GPU之上都得到了自己样本对应的稠密向量,记录在 embedding_feature_tensors_ 之上。每个GPU的数据是 batch size 条,每条有 slot number 个稠密向量,我们现在回忆一下:
DistributedSlotEmbeddingHash:所有特征都存储于不同特征域/槽上,不管槽索引号是多少,这些特征都根据特征的索引号分布到不同的GPU上。这意味着同一插槽中的特征可能存储在不同的 GPU 中,这就是将其称为“分布式插槽”的原因。由于需要全局规约,所以DistributedSlotEmbedding 适合 embedding 大于 GPU 内存大小的情况,因而DistributedSlotEmbedding 在 GPU 之间有更多的内存交换。
GPU之上每个样本数据之中的slot只是slot的一部分数据,我们给出一个例子。我们假设一共有2个gpu,batch size为2,一共3个slot。有两个样本,拿第一个样本为例,slot 1有两个key,分别是GPU 1 上的1,GPU 2上的7。所以需要把这两个key进行归并操作。具体如下:

每条数据里面的每个slot都只是一部分key,同一插槽中的特征可能存储在不同的 GPU 中,这些特征都根据特征的索引号分布到不同的GPU上。这样就需要把GPU 1,GPU 2之上的数据进行合并,做完reduce scatter后,数据应该是完整的,并且每个gpu上只分到一部分完整的数据。
5.1 背景知识
关于 Reduce Scatter 的原理,请参见 https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/operations.html。这里只是大致介绍。
Reduce操作的作用是对所有计算节点上的数值进行归约操作,并且只将归约后的结果保存到主节点上。和 AllReduce 的操作其实一样,只不过是把结果只放到root上而已。

ReduceScatter 操作执行与Reduce操作相同的操作,只是结果分散在rank之间的相等块中,每个rank根据其rank索引获得一块数据,即每个rank只受到reduce结果的一部分数据。
或者说,ReduceScatter 就是先做Scatter,将数据切分成同等大小的数据块,再依据Rank Index 对每一个rank所获得的数据做Reduce。这类似于全聚集,但是并不是将数据简单拼接到一起而是做了规约操作(比如,求和或最大值操作)。
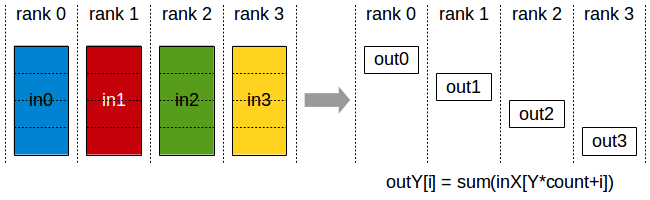
或者参见下图,来自NVIDIA文档 https://images.nvidia.cn/events/sc15/pdfs/NCCL-Woolley.pdf。对所有GPU上的数据进行reduce操作,这里是sum,然后将结果切分到所有的GPU上。

5.2 代码
具体代码如下,是对 embedding_feature_tensors_ 进行 reduce scatter,结果放在 embedding_data_.get_output_tensors(is_train) 之上。
// do reduce scatter
// 做了之后,数据才是完整的,每个gpu上分到完整数据的一部分
size\_t recv_count = embedding_data_.get\_batch\_size\_per\_gpu(is_train) *
embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.embedding_vec_size;
functors_.reduce\_scatter(recv_count, embedding_feature_tensors_,
embedding_data_.get\_output\_tensors(is_train),
embedding_data_.get\_resource\_manager());
reduce_scatter 算子代码是,这里是sum操作:
template void SparseEmbeddingFunctors::reduce\_scatter<float>(
size\_t recv_count, const Tensors2<float> &send_tensors, Tensors2<float> &recv_tensors,
const ResourceManager &resource_manager);
template <typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::reduce\_scatter(size\_t recv\_count,
const Tensors2 &send\_tensors,
Tensors2 &recv\_tensors,
const ResourceManager &resource\_manager) {
size\_t local_gpu_count = resource_manager.get\_local\_gpu\_count();
size\_t total_gpu_count = resource_manager.get\_global\_gpu\_count();
// need to know the type of TypeHashKey here
ncclDataType_t type;
switch (sizeof(TypeEmbeddingComp)) {
case 2:
type = ncclHalf;
break;
case 4:
type = ncclFloat;
break;
default:
CK\_THROW\_(Error_t::WrongInput, "Error: TypeHashKey not support by now");
}
// for multi GPUs, use NCCL to do Reduce-Scatter(supporting multi-node GPU servers)
if (total_gpu_count > 1) {
CK\_NCCL\_THROW\_(ncclGroupStart());
for (size\_t id = 0; id < local_gpu_count; id++) {
const auto &local_gpu = resource_manager.get\_local\_gpu(id);
CK\_NCCL\_THROW\_(ncclReduceScatter(send_tensors[id].get\_ptr(), // send buf
recv_tensors[id].get\_ptr(), // recv buff
recv_count, type, ncclSum, local_gpu->get\_nccl(),
local_gpu->get\_stream()));
}
CK\_NCCL\_THROW\_(ncclGroupEnd());
}
// for single GPU, just do memcpyD2D
else { // total\_gpu\_count == 1
const auto &local_gpu = resource_manager.get\_local\_gpu(0);
CudaDeviceContext context(local\_gpu->get\_device\_id());
CK\_CUDA\_THROW\_(cudaMemcpyAsync(recv_tensors[0].get\_ptr(), send_tensors[0].get\_ptr(),
recv_count * sizeof(TypeEmbeddingComp), cudaMemcpyDeviceToDevice,
local_gpu->get\_stream()));
}
return;
}
我们用图例来展示一下目前过程,为了更好的理解,这里我们可以把Reduce-Scatter分段考虑,
- Reduce 就是类似AllReduce操作,这个之后,所有GPU之上拥有所有数据。
- Scatter 则按照 rank 来对样本进行分配,所以GPU 1 之上是Sample 1,GPU 2之上是Sample 2。

我们最后归纳整体如下:

0x06 Combiner
如果需要做 mean pooling,则需需要做两个操作。
* 1) forward
* sum: calling forward\_sum\_kernel()
* mean: calling foward\_sum\_kernel() + forward\_scale\_kernel()
第一个操作是对CSR row offset 做一个AllReduce,这样就相当于是一个全局offset了,就可以拿到每个sample每个slot里的key的总个数。
第二个操作是Forward Scale,就是把embedding的值除以这个"个数",也就等于做了平均。
// scale for combiner=mean after reduction
if (embedding_data_.embedding_params_.combiner == 1) {
size\_t send_count = embedding_data_.embedding_params_.get\_batch\_size(is_train) *
embedding_data_.embedding_params_.slot_num +
1;
functors_.all\_reduce(send_count, embedding_data_.get\_row\_offsets\_tensors(is_train),
row_offset_allreduce_tensors_, embedding_data_.get\_resource\_manager());
// do average
functors_.forward_scale(
embedding_data_.embedding_params_.get\_batch\_size(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, row_offset_allreduce_tensors_,
embedding_data_.get\_output\_tensors(is_train), embedding_data_.get\_resource\_manager());
}
6.1 AllReduce
AllReduce 结果如下:

回忆一下 CSR 例子。
* 40,50,10,20
* 30,50,10
* 30,20
* 10
* Will be convert to the form of:
* row offset: 0,4,7,9,10
* value: 40,50,10,20,30,50,10,30,20,10
row_offset 的数字就是:第一行起始位置是0,第二行起始位置是4,第三行起始位置是7… 我们假设这是在Node 1之上。
如果Node 2的row_offset为 0,5,7,10,11,说明在这个Node之上,第一行起始位置是0,第二行起始位置是5,第三行起始位置是7…,对应CSR是:
* 40,50,10,20,30
* 30,50
* 30,20,40
* 10
* Will be convert to the form of:
* row offset: 0,5,7,10,11
* value: 40,50,10,20,30,50,10,30,20,10
做了AllReduce之后,得到:0,9,14,19,21。这样就知道第一个行总个数是9个,第二行总个是是7+7-9 = 5个。
具体算子如下:
/**
* collection communication: all\_reduce.
* @param send\_count the count of elements will be sent.
* @param send\_tensors the send tensors of multi GPUs.
* @param recv\_tensors the recv tensors of multi GPUs.
* @param device\_resources all gpus device resources.
* @param context gpu device context, for switching device.
*/
template <typename TypeHashKey>
void SparseEmbeddingFunctors::all\_reduce(size\_t send\_count,
const Tensors2 &send\_tensors,
Tensors2 &recv\_tensors,
const ResourceManager &resource\_manager) {
size\_t local_gpu_count = resource_manager.get\_local\_gpu\_count();
size\_t total_gpu_count = resource_manager.get\_global\_gpu\_count();
// need to know the type of Type here
ncclDataType_t type;
switch (sizeof(TypeHashKey)) {
case 4:
type = ncclUint32;
break;
case 8:
type = ncclUint64;
break;
default:
CK\_THROW\_(Error_t::WrongInput, "Error: Type not support by now");
}
// for multi GPUs, use NCCL to do all\_reduce (supporting multi-node GPU servers)
if (total_gpu_count > 1) {
CK\_NCCL\_THROW\_(ncclGroupStart());
for (size\_t id = 0; id < local_gpu_count; id++) {
const auto &local_gpu = resource_manager.get\_local\_gpu(id);
// ALLReduce操作
CK\_NCCL\_THROW\_(ncclAllReduce(send_tensors[id].get\_ptr(), recv_tensors[id].get\_ptr(),
send_count, type, ncclSum, local_gpu->get\_nccl(),
local_gpu->get\_stream()));
}
CK\_NCCL\_THROW\_(ncclGroupEnd());
}
// for single GPU, just do memcpyD2D
else { // total\_gpu\_count == 1
const auto &local_gpu = resource_manager.get\_local\_gpu(0);
CudaDeviceContext context(local\_gpu->get\_device\_id());
CK\_CUDA\_THROW\_(cudaMemcpyAsync(recv_tensors[0].get\_ptr(), send_tensors[0].get\_ptr(),
send_count * sizeof(TypeHashKey), cudaMemcpyDeviceToDevice,
local_gpu->get\_stream()));
}
return;
}
6.2 Forward Scale
最后要做一步 Forward Scale 操作。
// do average
functors_.forward_scale(
embedding_data_.embedding_params_.get\_batch\_size(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, row_offset_allreduce_tensors_,
embedding_data_.get\_output\_tensors(is_train), embedding_data_.get\_resource\_manager());
前面我们做了AllReduce之后,得到 row_offset_allreduce_tensors_ 是 0,9,14,19,21。这样就知道第一个行总个数是9个,第二行总个是是7+7-9 = 5个。就可以对embedding_data_.get_output_tensors(is_train)的每个元素进行操作,每个元素都除以本slot的元素总数,就是做mean了。
算子如下:
// forward kernel function: this is an additional function for combiner=mean (only for Distributed
// Embedding)
template <typename TypeKey, typename TypeEmbeddingComp>
\_\_global\_\_ void forward\_scale\_kernel(int batch\_size, int slot\_num, int embedding\_vec\_size,
const TypeKey *row\_offset,
TypeEmbeddingComp *embedding\_feature) {
int bid = blockIdx.x;
int tid = threadIdx.x;
if (bid < batch_size && tid < embedding_vec_size) {
for (int i = 0; i < slot_num; i++) {
size\_t feature_row_index = bid * slot_num + i;
// 本slot元素总数
int feature_num = row_offset[feature_row_index + 1] - row_offset[feature_row_index];
// 输出矩阵的row offset
size\_t feature_index = feature_row_index * embedding_vec_size + tid;
float feature =
TypeConvertFunc<float, TypeEmbeddingComp>::convert(embedding_feature[feature_index]);
float scaler = 1.0f;
if (feature_num > 1) {
scaler = 1.0f / (float)feature_num; // 除数
}
embedding_feature[feature_index] = // 设置
TypeConvertFuncfloat>::convert(feature * scaler);
}
}
}
template <typename TypeKey, typename TypeEmbeddingComp>
void do\_forward\_scale(size\_t batchsize\_per\_gpu, size\_t slot\_num, size\_t embedding\_vec\_size,
const TypeKey *row\_offset, TypeEmbeddingComp *embedding\_feature,
cudaStream\_t stream) {
const size\_t grid\_size = batchsize\_per\_gpu;
const size\_t block\_size = embedding\_vec\_size;
forward\_scale\_kernel<<0, stream>>>(
batchsize\_per\_gpu, slot\_num, embedding\_vec\_size, row\_offset, embedding\_feature);
};
0x07 总结
最终结果如下,图有几个被简化的地方,比如hash_table_value_tensors_ 应该是向量的向量,这里简化为向量。
embedding vector数值也是虚拟的。嵌入层的最终输出是在 EmbeddingData 的成员变量 train_output_tensors_ 之上。

或者从下面来看。

0xFF 参考
快过HugeCTR:用OneFlow轻松实现大型推荐系统引擎
https://nvlabs.github.io/cub/annotated.html
https://developer.nvidia.com/blog/introducing-merlin-hugectr-training-framework-dedicated-to-recommender-systems/
https://developer.nvidia.com/blog/announcing-nvidia-merlin-application-framework-for-deep-recommender-systems/
https://developer.nvidia.com/blog/accelerating-recommender-systems-training-with-nvidia-merlin-open-beta/
HugeCTR源码阅读
embedding层如何反向传播
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
稀疏矩阵存储格式总结+存储效率对比:COO,CSR,DIA,ELL,HYB
无中生有:论推荐算法中的Embedding思想
tf.nn.embedding_lookup函数原理
求通俗讲解下tensorflow的embedding_lookup接口的意思?
【技术干货】聊聊在大厂推荐场景中embedding都是怎么做的
ctr预估算法对于序列特征embedding可否做拼接,输入MLP?与pooling
推荐系统中的深度匹配模型
土法炮制:Embedding 层是如何实现的?
不等距双杆模型_搜索中的深度匹配模型(下)
深度特征 快牛策略关于高低层特征融合
[深度学习] DeepFM 介绍与Pytorch代码解释
deepFM in pytorch
推荐算法之7——DeepFM模型
DeepFM 参数理解(二)
推荐系统遇上深度学习(三)–DeepFM模型理论和实践
[深度学习] DeepFM 介绍与Pytorch代码解释
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/operations.html
带你认识大模型训练关键算法:分布式训练Allreduce算法